 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICECAP: Information Concentrated Entity-aware Image Captioning
Paper and Code

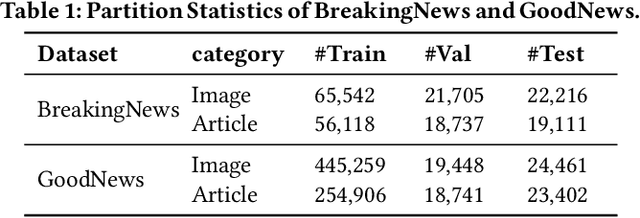
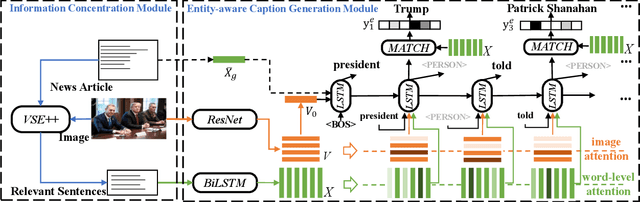
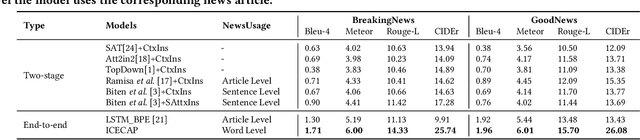
Most current image captioning systems focus on describing general image content, and lack background knowledge to deeply understand the image, such as exact named entities or concrete events. In this work, we focus on the entity-aware news image captioning task which aims to generate informative captions by leveraging the associated news articles to provide background knowledge about the target image. However, due to the length of news articles, previous works only employ news articles at the coarse article or sentence level, which are not fine-grained enough to refine relevant events and choose named entities accurately. To overcome these limitations, we propose an Information Concentrated Entity-aware news image CAPtioning (ICECAP) model, which progressively concentrates on relevant textual information within the corresponding news article from the sentence level to the word level. Our model first creates coarse concentration on relevant sentences using a cross-modality retrieval model and then generates captions by further concentrating on relevant words within the sentences. Extensive experiments on both BreakingNews and GoodNews datasets demonstrate the effectiveness of our proposed method, which outperforms other state-of-the-arts. The code of ICECAP is publicly available at https://github.com/HAWLYQ/ICECAP.