 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
C-MADA: Unsupervised Cross-Modality Adversarial Domain Adaptation framework for medical Image Segmentation
Oct 29, 2021
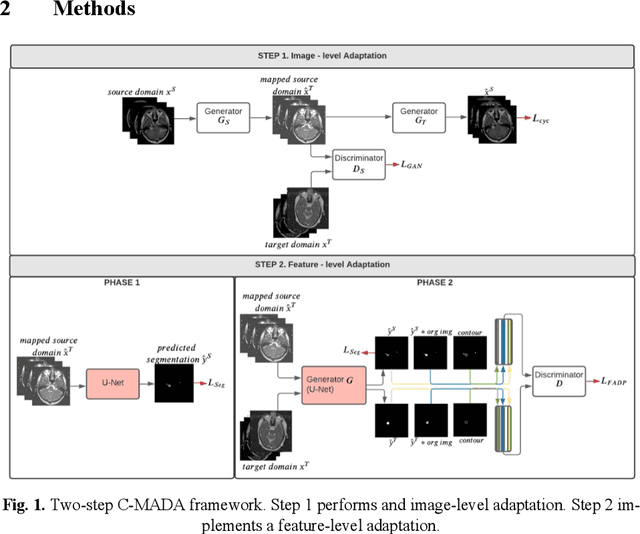

Deep learning models have obtained state-of-the-art results for medical image analysis. However, when these models are tested on an unseen domain there is a significant performance degradation. In this work, we present an unsupervised Cross-Modality Adversarial Domain Adaptation (C-MADA) framework for medical image segmentation. C-MADA implements an image- and feature-level adaptation method in a sequential manner. First, images from the source domain are translated to the target domain through an un-paired image-to-image adversarial translation with cycle-consistency loss. Then, a U-Net network is trained with the mapped source domain images and target domain images in an adversarial manner to learn domain-invariant feature representations. Furthermore, to improve the networks segmentation performance, information about the shape, texture, and con-tour of the predicted segmentation is included during the adversarial train-ing. C-MADA is tested on the task of brain MRI segmentation, obtaining competitive results.
The Image Local Autoregressive Transformer
Jun 04, 2021

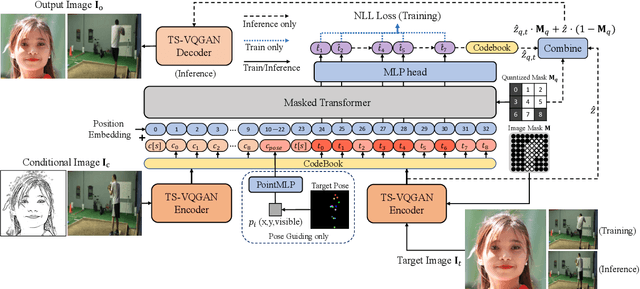
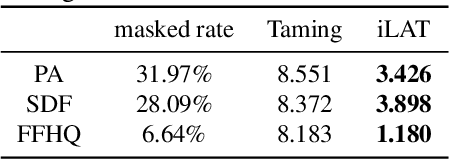
Recently, AutoRegressive (AR) models for the whole image generation empowered by transformers have achieved comparable or even better performance to Generative Adversarial Networks (GANs). Unfortunately, directly applying such AR models to edit/change local image regions, may suffer from the problems of missing global information, slow inference speed, and information leakage of local guidance. To address these limitations, we propose a novel model -- image Local Autoregressive Transformer (iLAT), to better facilitate the locally guided image synthesis. Our iLAT learns the novel local discrete representations, by the newly proposed local autoregressive (LA) transformer of the attention mask and convolution mechanism. Thus iLAT can efficiently synthesize the local image regions by key guidance information. Our iLAT is evaluated on various locally guided image syntheses, such as pose-guided person image synthesis and face editing. Both the quantitative and qualitative results show the efficacy of our model.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
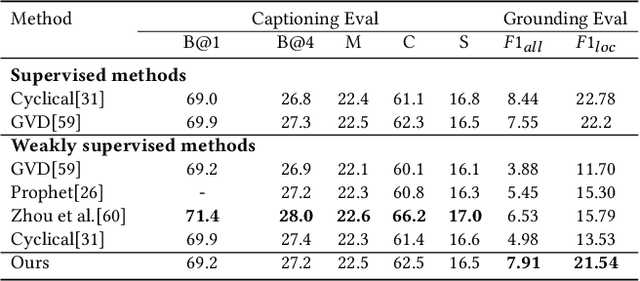
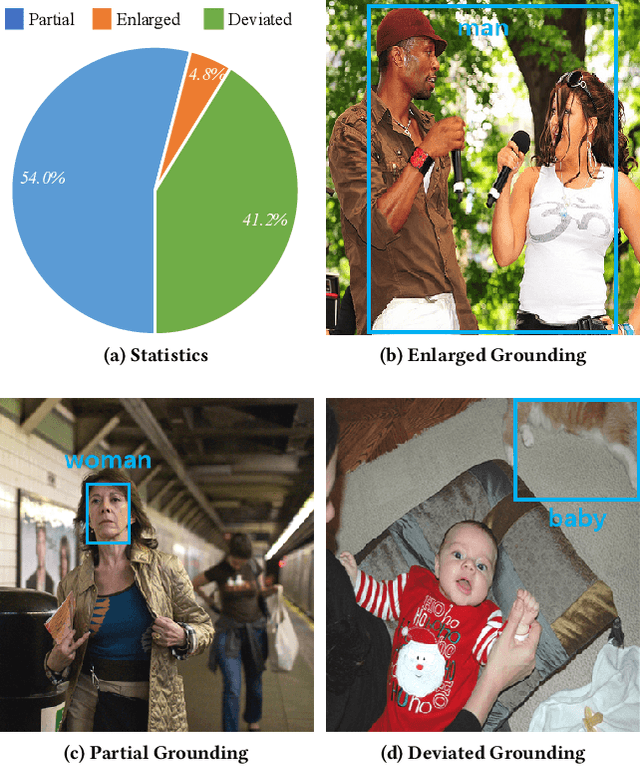
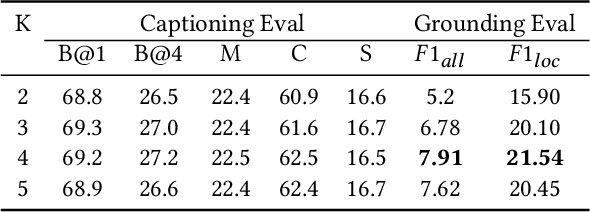
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
RGB-X Classification for Electronics Sorting
Sep 08, 2022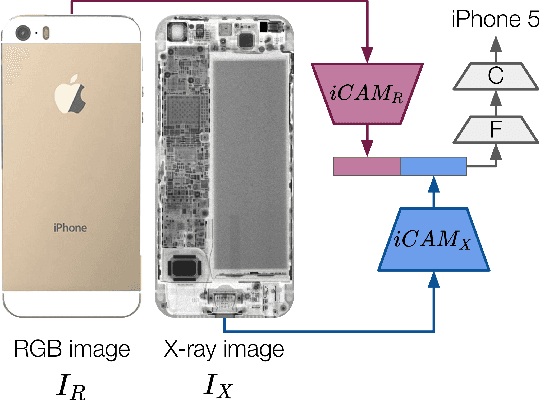

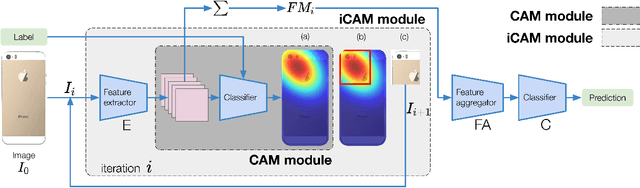
Effectively disassembling and recovering materials from waste electrical and electronic equipment (WEEE) is a critical step in moving global supply chains from carbon-intensive, mined materials to recycled and renewable ones. Conventional recycling processes rely on shredding and sorting waste streams, but for WEEE, which is comprised of numerous dissimilar materials, we explore targeted disassembly of numerous objects for improved material recovery. Many WEEE objects share many key features and therefore can look quite similar, but their material composition and internal component layout can vary, and thus it is critical to have an accurate classifier for subsequent disassembly steps for accurate material separation and recovery. This work introduces RGB-X, a multi-modal image classification approach, that utilizes key features from external RGB images with those generated from X-ray images to accurately classify electronic objects. More specifically, this work develops Iterative Class Activation Mapping (iCAM), a novel network architecture that explicitly focuses on the finer-details in the multi-modal feature maps that are needed for accurate electronic object classification. In order to train a classifier, electronic objects lack large and well annotated X-ray datasets due to expense and need of expert guidance. To overcome this issue, we present a novel way of creating a synthetic dataset using domain randomization applied to the X-ray domain. The combined RGB-X approach gives us an accuracy of 98.6% on 10 generations of modern smartphones, which is greater than their individual accuracies of 89.1% (RGB) and 97.9% (X-ray) independently. We provide experimental results3 to corroborate our results.
Multi-View Image-to-Image Translation Supervised by 3D Pose
Apr 12, 2021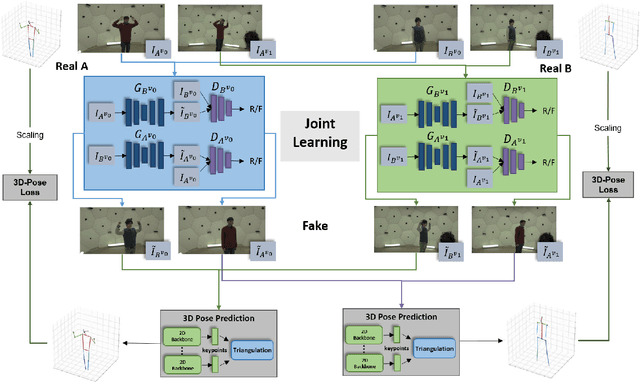



We address the task of multi-view image-to-image translation for person image generation. The goal is to synthesize photo-realistic multi-view images with pose-consistency across all views. Our proposed end-to-end framework is based on a joint learning of multiple unpaired image-to-image translation models, one per camera viewpoint. The joint learning is imposed by constraints on the shared 3D human pose in order to encourage the 2D pose projections in all views to be consistent. Experimental results on the CMU-Panoptic dataset demonstrate the effectiveness of the suggested framework in generating photo-realistic images of persons with new poses that are more consistent across all views in comparison to a standard Image-to-Image baseline. The code is available at: https://github.com/sony-si/MultiView-Img2Img
Semantic Clustering based Deduction Learning for Image Recognition and Classification
Dec 25, 2021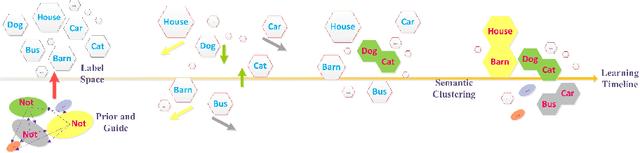
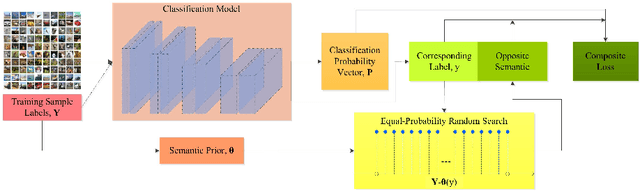
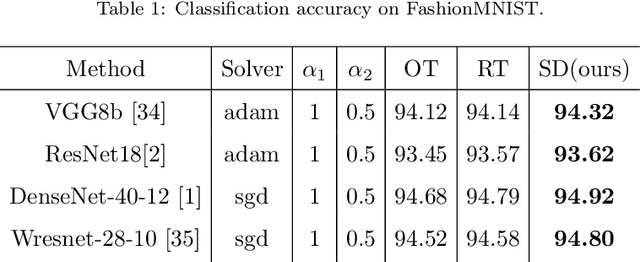
The paper proposes a semantic clustering based deduction learning by mimicking the learning and thinking process of human brains. Human beings can make judgments based on experience and cognition, and as a result, no one would recognize an unknown animal as a car. Inspired by this observation, we propose to train deep learning models using the clustering prior that can guide the models to learn with the ability of semantic deducing and summarizing from classification attributes, such as a cat belonging to animals while a car pertaining to vehicles. %Specifically, if an image is labeled as a cat, then the model is trained to learn that "this image is totally not any random class that is the outlier of animal". The proposed approach realizes the high-level clustering in the semantic space, enabling the model to deduce the relations among various classes during the learning process. In addition, the paper introduces a semantic prior based random search for the opposite labels to ensure the smooth distribution of the clustering and the robustness of the classifiers. The proposed approach is supported theoretically and empirically through extensive experiments. We compare the performance across state-of-the-art classifiers on popular benchmarks, and the generalization ability is verified by adding noisy labeling to the datasets. Experimental results demonstrate the superiority of the proposed approach.
Dynamic Proposals for Efficient Object Detection
Jul 12, 2022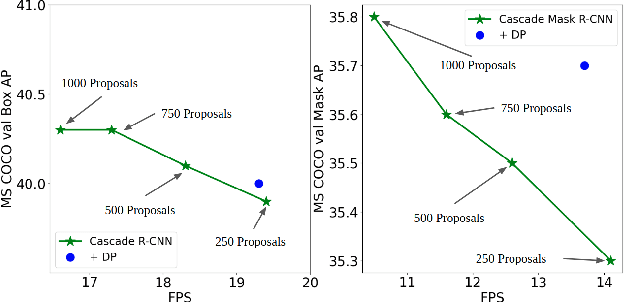
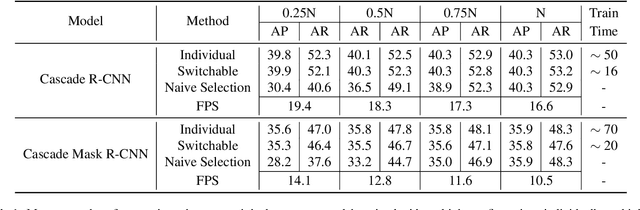
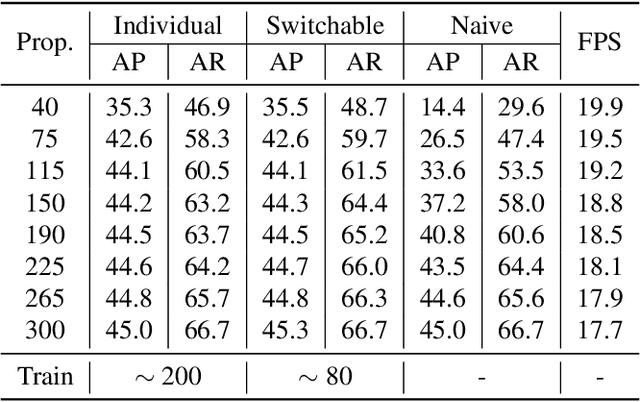
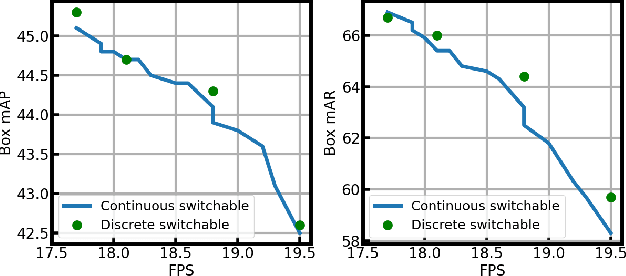
Object detection is a basic computer vision task to loccalize and categorize objects in a given image. Most state-of-the-art detection methods utilize a fixed number of proposals as an intermediate representation of object candidates, which is unable to adapt to different computational constraints during inference. In this paper, we propose a simple yet effective method which is adaptive to different computational resources by generating dynamic proposals for object detection. We first design a module to make a single query-based model to be able to inference with different numbers of proposals. Further, we extend it to a dynamic model to choose the number of proposals according to the input image, greatly reducing computational costs. Our method achieves significant speed-up across a wide range of detection models including two-stage and query-based models while obtaining similar or even better accuracy.
CNN-based fully automatic wrist cartilage volume quantification in MR Image
Jun 22, 2022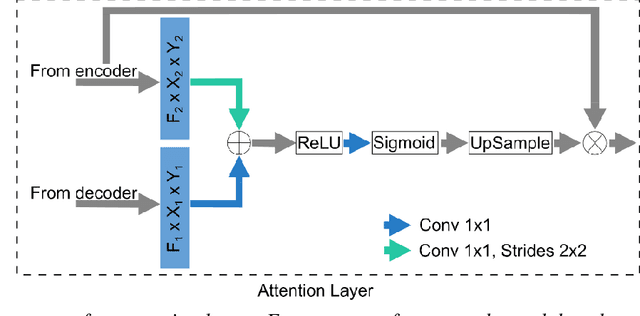

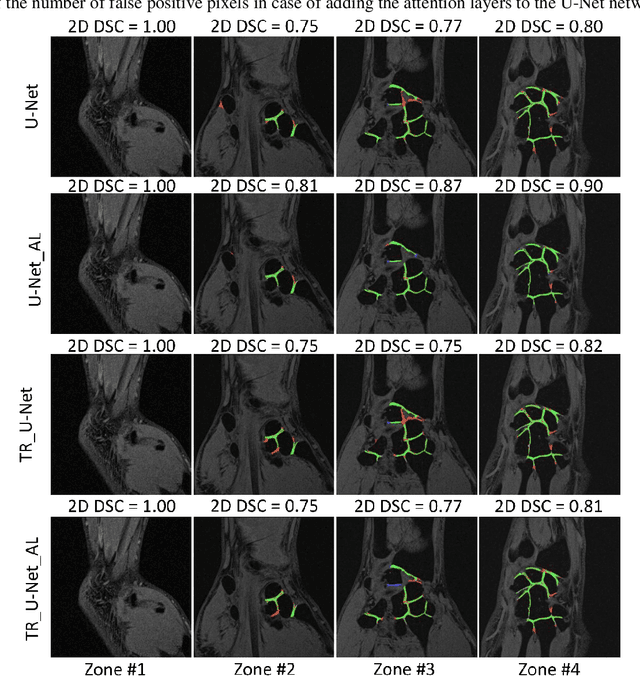
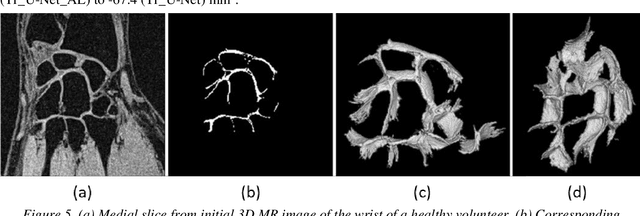
Detection of cartilage loss is crucial for the diagnosis of osteo- and rheumatoid arthritis. A large number of automatic segmentation tools have been reported so far for cartilage assessment in magnetic resonance images of large joints. As compared to knee or hip, wrist cartilage has a more complex structure so that automatic tools developed for large joints are not expected to be operational for wrist cartilage segmentation. In that respect, a fully automatic wrist cartilage segmentation method would be of high clinical interest. We assessed the performance of four optimized variants of the U-Net architecture with truncation of its depth and addition of attention layers (U-Net_AL). The corresponding results were compared to those from a patch-based convolutional neural network (CNN) we previously designed. The segmentation quality was assessed on the basis of a comparative analysis with manual segmentation using several morphological (2D DSC, 3D DSC, precision) and a volumetric metrics. The four networks outperformed the patch-based CNN in terms of segmentation homogeneity and quality. The median 3D DSC value computed with the U-Net_AL (0.817) was significantly larger than the corresponding DSC values computed with the other networks. In addition, the U-Net_AL CNN provided the lowest mean volume error (17%) and the highest Pearson correlation coefficient (0.765) with respect to the ground truth. Of interest, the reproducibility computed from using U-Net_AL was larger than the reproducibility of the manual segmentation. U-net convolutional neural network with additional attention layers provides the best wrist cartilage segmentation performance. In order to be used in clinical conditions, the trained network can be fine-tuned on a dataset representing a group of specific patients. The error of cartilage volume measurement should be assessed independently using a non-MRI method.
Distance-Aware Occlusion Detection with Focused Attention
Aug 23, 2022
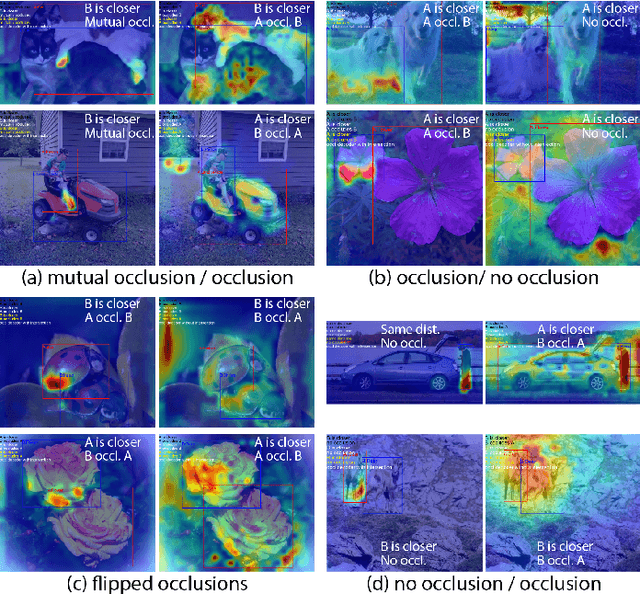
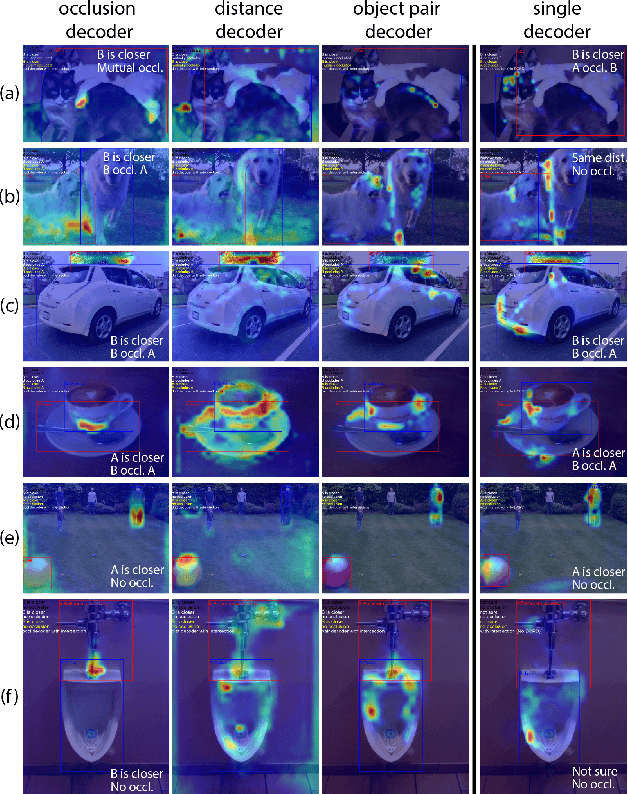
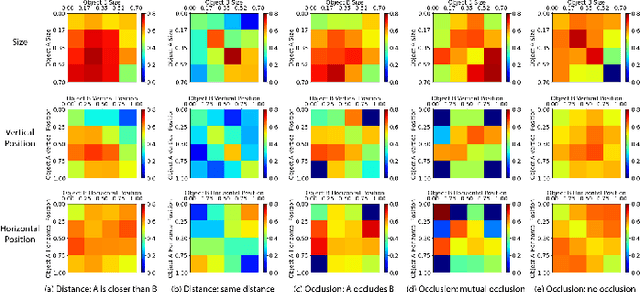
For humans, understanding the relationships between objects using visual signals is intuitive. For artificial intelligence, however, this task remains challenging. Researchers have made significant progress studying semantic relationship detection, such as human-object interaction detection and visual relationship detection. We take the study of visual relationships a step further from semantic to geometric. In specific, we predict relative occlusion and relative distance relationships. However, detecting these relationships from a single image is challenging. Enforcing focused attention to task-specific regions plays a critical role in successfully detecting these relationships. In this work, (1) we propose a novel three-decoder architecture as the infrastructure for focused attention; 2) we use the generalized intersection box prediction task to effectively guide our model to focus on occlusion-specific regions; 3) our model achieves a new state-of-the-art performance on distance-aware relationship detection. Specifically, our model increases the distance F1-score from 33.8% to 38.6% and boosts the occlusion F1-score from 34.4% to 41.2%. Our code is publicly available.
FADE: Fusing the Assets of Decoder and Encoder for Task-Agnostic Upsampling
Jul 21, 2022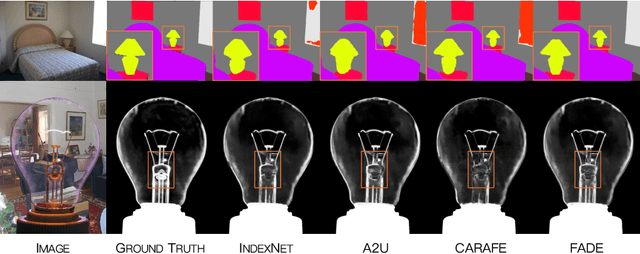
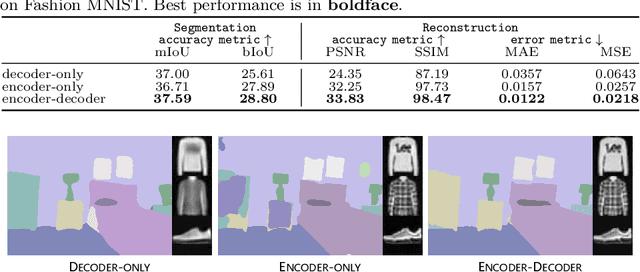
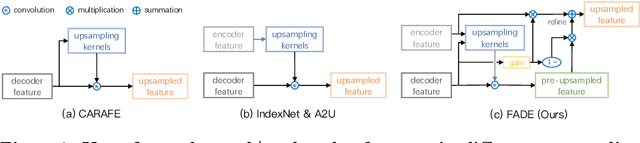

We consider the problem of task-agnostic feature upsampling in dense prediction where an upsampling operator is required to facilitate both region-sensitive tasks like semantic segmentation and detail-sensitive tasks such as image matting. Existing upsampling operators often can work well in either type of the tasks, but not both. In this work, we present FADE, a novel, plug-and-play, and task-agnostic upsampling operator. FADE benefits from three design choices: i) considering encoder and decoder features jointly in upsampling kernel generation; ii) an efficient semi-shift convolutional operator that enables granular control over how each feature point contributes to upsampling kernels; iii) a decoder-dependent gating mechanism for enhanced detail delineation. We first study the upsampling properties of FADE on toy data and then evaluate it on large-scale semantic segmentation and image matting. In particular, FADE reveals its effectiveness and task-agnostic characteristic by consistently outperforming recent dynamic upsampling operators in different tasks. It also generalizes well across convolutional and transformer architectures with little computational overhead. Our work additionally provides thoughtful insights on what makes for task-agnostic upsampling. Code is available at: http://lnkiy.in/fade_in