 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CRCNet: Few-shot Segmentation with Cross-Reference and Region-Global Conditional Networks
Aug 23, 2022
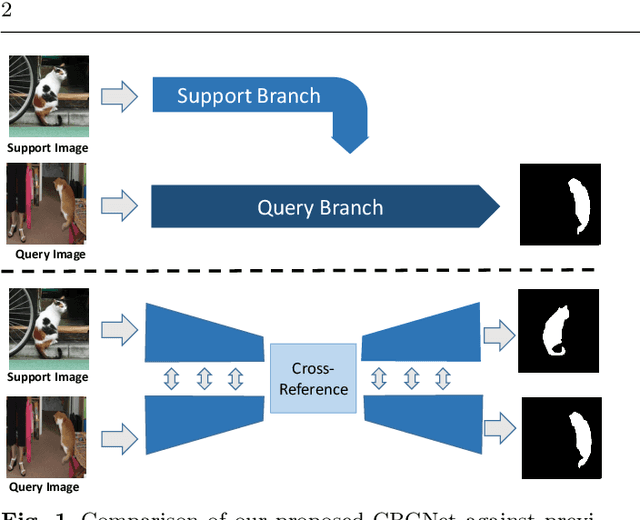

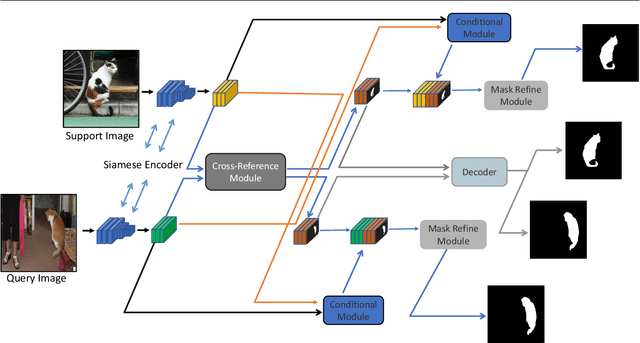

Few-shot segmentation aims to learn a segmentation model that can be generalized to novel classes with only a few training images. In this paper, we propose a Cross-Reference and Local-Global Conditional Networks (CRCNet) for few-shot segmentation. Unlike previous works that only predict the query image's mask, our proposed model concurrently makes predictions for both the support image and the query image. Our network can better find the co-occurrent objects in the two images with a cross-reference mechanism, thus helping the few-shot segmentation task. To further improve feature comparison, we develop a local-global conditional module to capture both global and local relations. We also develop a mask refinement module to refine the prediction of the foreground regions recurrently. Experiments on the PASCAL VOC 2012, MS COCO, and FSS-1000 datasets show that our network achieves new state-of-the-art performance.
Attention Augmented ConvNeXt UNet For Rectal Tumour Segmentation
Oct 01, 2022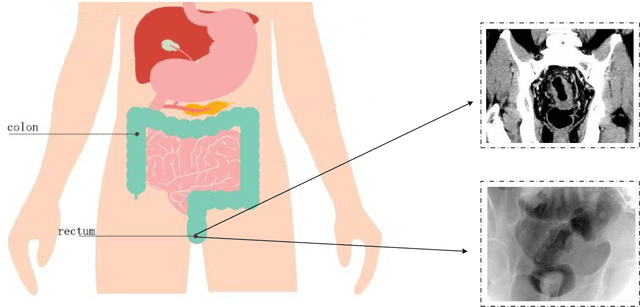

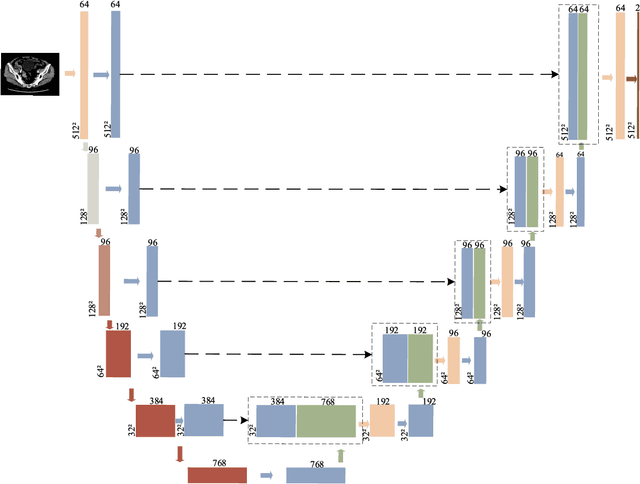
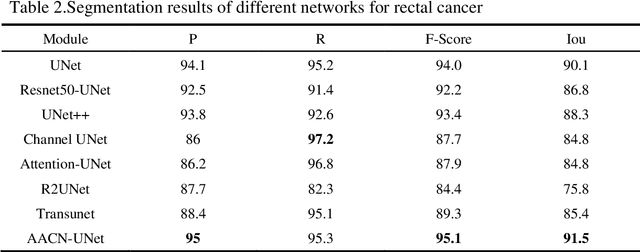
It is a challenge to segment the location and size of rectal cancer tumours through deep learning. In this paper, in order to improve the ability of extracting suffi-cient feature information in rectal tumour segmentation, attention enlarged ConvNeXt UNet (AACN-UNet), is proposed. The network mainly includes two improvements: 1) the encoder stage of UNet is changed to ConvNeXt structure for encoding operation, which can not only integrate multi-scale semantic information on a large scale, but al-so reduce information loss and extract more feature information from CT images; 2) CBAM attention mechanism is added to improve the connection of each feature in channel and space, which is conducive to extracting the effective feature of the target and improving the segmentation accuracy.The experiment with UNet and its variant network shows that AACN-UNet is 0.9% ,1.1% and 1.4% higher than the current best results in P, F1 and Miou.Compared with the training time, the number of parameters in UNet network is less. This shows that our proposed AACN-UNet has achieved ex-cellent results in CT image segmentation of rectal cancer.
LC-FDNet: Learned Lossless Image Compression with Frequency Decomposition Network
Dec 13, 2021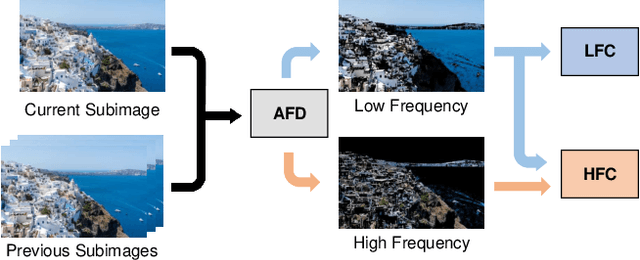
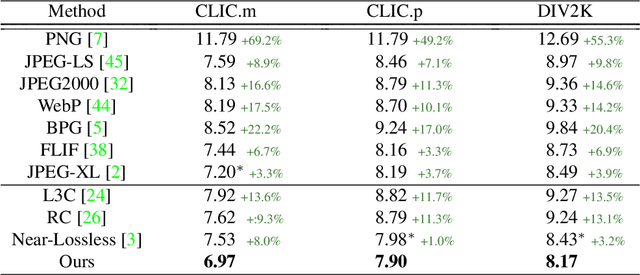
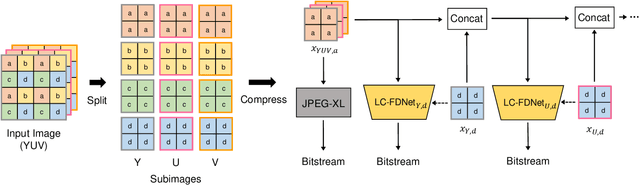
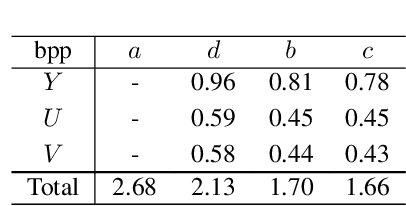
Recent learning-based lossless image compression methods encode an image in the unit of subimages and achieve comparable performances to conventional non-learning algorithms. However, these methods do not consider the performance drop in the high-frequency region, giving equal consideration to the low and high-frequency areas. In this paper, we propose a new lossless image compression method that proceeds the encoding in a coarse-to-fine manner to separate and process low and high-frequency regions differently. We initially compress the low-frequency components and then use them as additional input for encoding the remaining high-frequency region. The low-frequency components act as a strong prior in this case, which leads to improved estimation in the high-frequency area. In addition, we design the frequency decomposition process to be adaptive to color channel, spatial location, and image characteristics. As a result, our method derives an image-specific optimal ratio of low/high-frequency components. Experiments show that the proposed method achieves state-of-the-art performance for benchmark high-resolution datasets.
IDR: Self-Supervised Image Denoising via Iterative Data Refinement
Nov 29, 2021
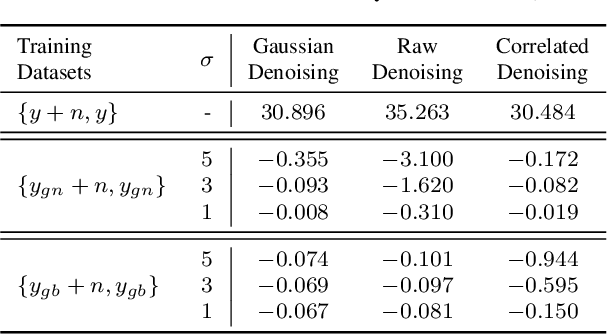
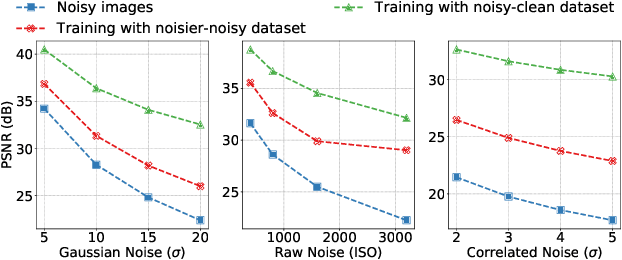
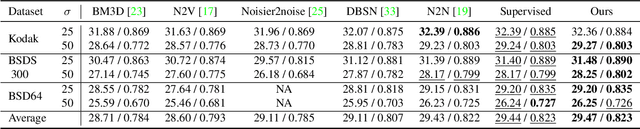
The lack of large-scale noisy-clean image pairs restricts supervised denoising methods' deployment in actual applications. While existing unsupervised methods are able to learn image denoising without ground-truth clean images, they either show poor performance or work under impractical settings (e.g., paired noisy images). In this paper, we present a practical unsupervised image denoising method to achieve state-of-the-art denoising performance. Our method only requires single noisy images and a noise model, which is easily accessible in practical raw image denoising. It performs two steps iteratively: (1) Constructing a noisier-noisy dataset with random noise from the noise model; (2) training a model on the noisier-noisy dataset and using the trained model to refine noisy images to obtain the targets used in the next round. We further approximate our full iterative method with a fast algorithm for more efficient training while keeping its original high performance. Experiments on real-world, synthetic, and correlated noise show that our proposed unsupervised denoising approach has superior performances over existing unsupervised methods and competitive performance with supervised methods. In addition, we argue that existing denoising datasets are of low quality and contain only a small number of scenes. To evaluate raw image denoising performance in real-world applications, we build a high-quality raw image dataset SenseNoise-500 that contains 500 real-life scenes. The dataset can serve as a strong benchmark for better evaluating raw image denoising. Code and dataset will be released at https://github.com/zhangyi-3/IDR
Turath-150K: Image Database of Arab Heritage
Jan 01, 2022
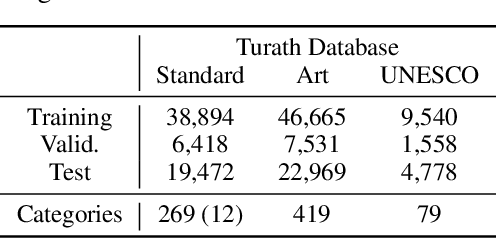
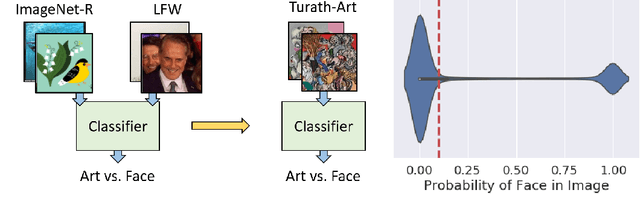
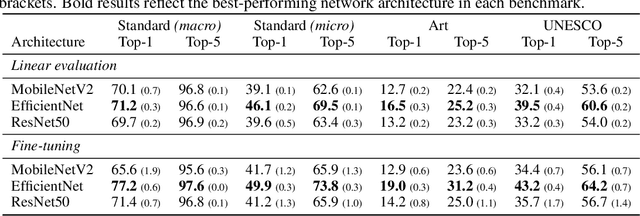
Large-scale image databases remain largely biased towards objects and activities encountered in a select few cultures. This absence of culturally-diverse images, which we refer to as the hidden tail, limits the applicability of pre-trained neural networks and inadvertently excludes researchers from under-represented regions. To begin remedying this issue, we curate Turath-150K, a database of images of the Arab world that reflect objects, activities, and scenarios commonly found there. In the process, we introduce three benchmark databases, Turath Standard, Art, and UNESCO, specialised subsets of the Turath dataset. After demonstrating the limitations of existing networks pre-trained on ImageNet when deployed on such benchmarks, we train and evaluate several networks on the task of image classification. As a consequence of Turath, we hope to engage machine learning researchers in under-represented regions, and to inspire the release of additional culture-focused databases. The database can be accessed here: danikiyasseh.github.io/Turath.
Dual Adversarial Adaptation for Cross-Device Real-World Image Super-Resolution
May 07, 2022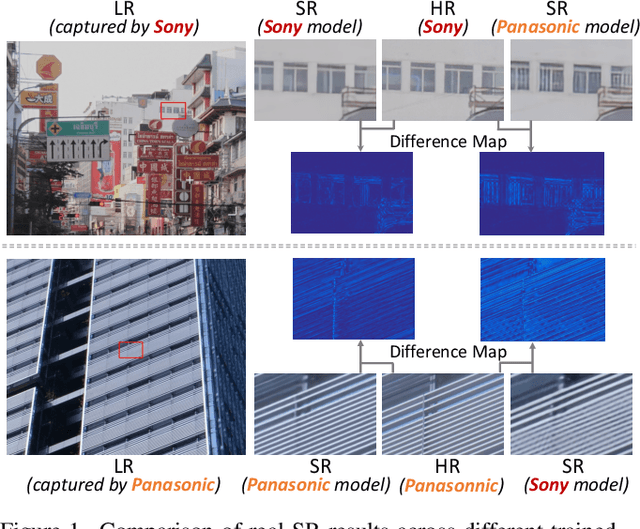
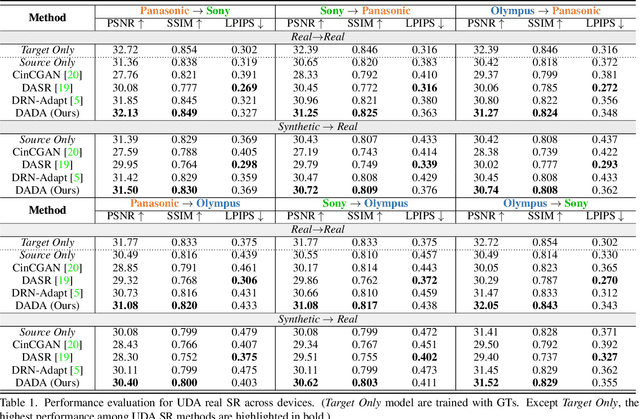
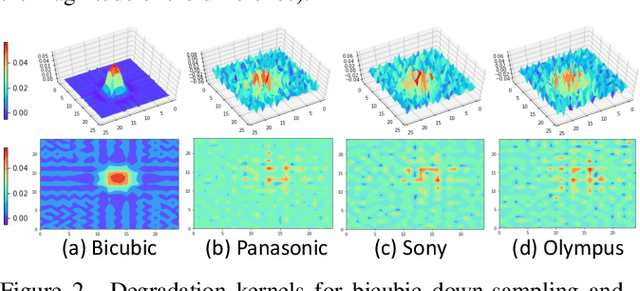
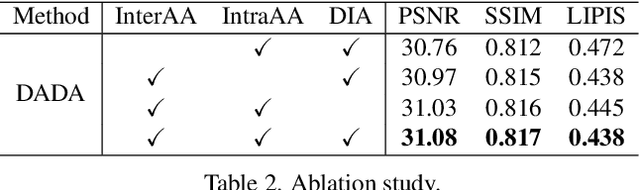
Due to the sophisticated imaging process, an identical scene captured by different cameras could exhibit distinct imaging patterns, introducing distinct proficiency among the super-resolution (SR) models trained on images from different devices. In this paper, we investigate a novel and practical task coded cross-device SR, which strives to adapt a real-world SR model trained on the paired images captured by one camera to low-resolution (LR) images captured by arbitrary target devices. The proposed task is highly challenging due to the absence of paired data from various imaging devices. To address this issue, we propose an unsupervised domain adaptation mechanism for real-world SR, named Dual ADversarial Adaptation (DADA), which only requires LR images in the target domain with available real paired data from a source camera. DADA employs the Domain-Invariant Attention (DIA) module to establish the basis of target model training even without HR supervision. Furthermore, the dual framework of DADA facilitates an Inter-domain Adversarial Adaptation (InterAA) in one branch for two LR input images from two domains, and an Intra-domain Adversarial Adaptation (IntraAA) in two branches for an LR input image. InterAA and IntraAA together improve the model transferability from the source domain to the target. We empirically conduct experiments under six Real to Real adaptation settings among three different cameras, and achieve superior performance compared with existing state-of-the-art approaches. We also evaluate the proposed DADA to address the adaptation to the video camera, which presents a promising research topic to promote the wide applications of real-world super-resolution. Our source code is publicly available at https://github.com/lonelyhope/DADA.git.
ManiFest: Manifold Deformation for Few-shot Image Translation
Nov 26, 2021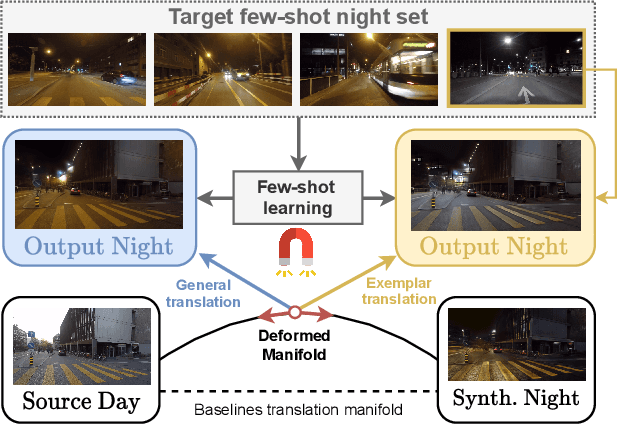
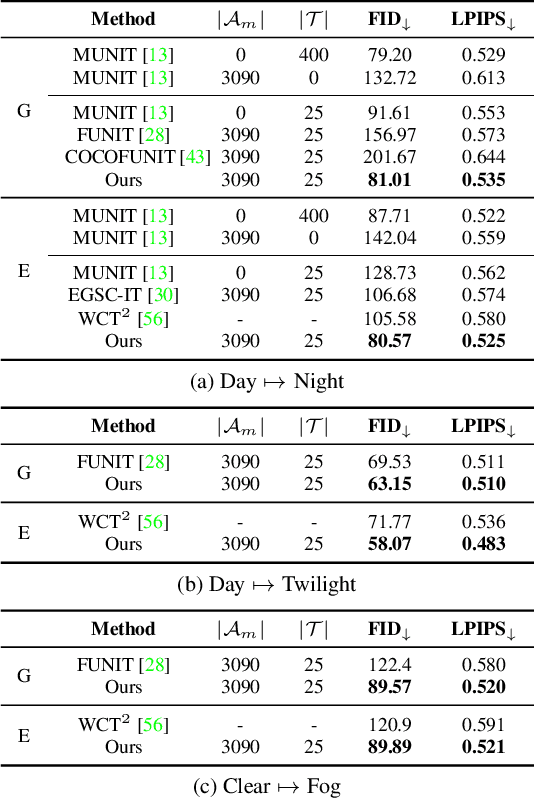
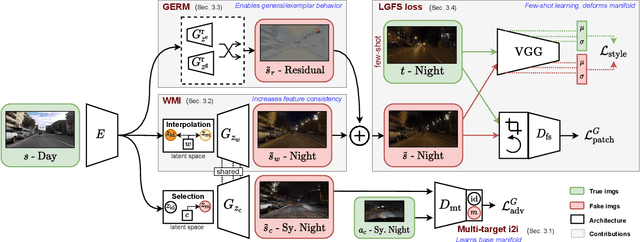
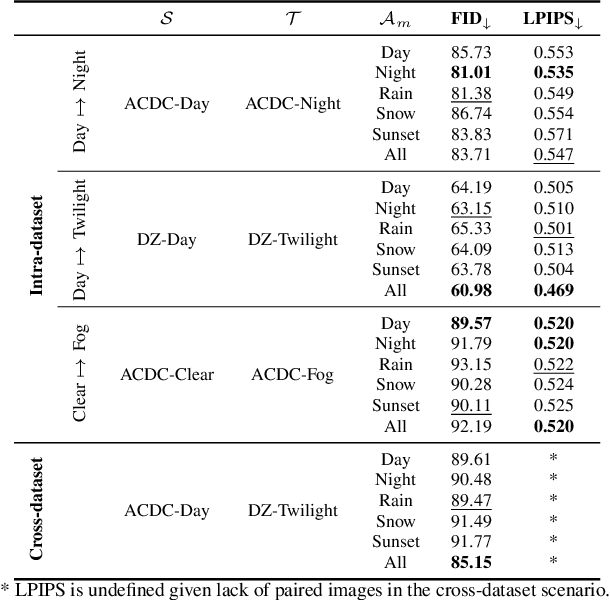
Most image-to-image translation methods require a large number of training images, which restricts their applicability. We instead propose ManiFest: a framework for few-shot image translation that learns a context-aware representation of a target domain from a few images only. To enforce feature consistency, our framework learns a style manifold between source and proxy anchor domains (assumed to be composed of large numbers of images). The learned manifold is interpolated and deformed towards the few-shot target domain via patch-based adversarial and feature statistics alignment losses. All of these components are trained simultaneously during a single end-to-end loop. In addition to the general few-shot translation task, our approach can alternatively be conditioned on a single exemplar image to reproduce its specific style. Extensive experiments demonstrate the efficacy of ManiFest on multiple tasks, outperforming the state-of-the-art on all metrics and in both the general- and exemplar-based scenarios. Our code will be open source.
On the Road to Online Adaptation for Semantic Image Segmentation
Mar 30, 2022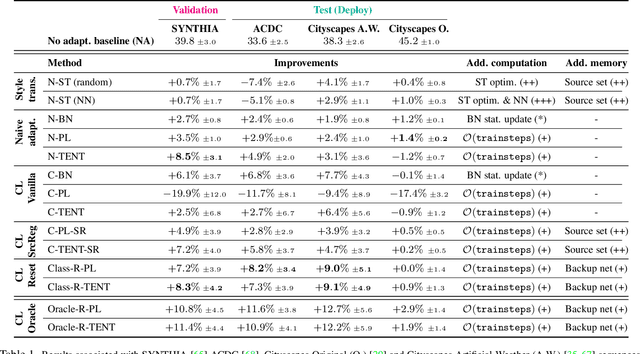

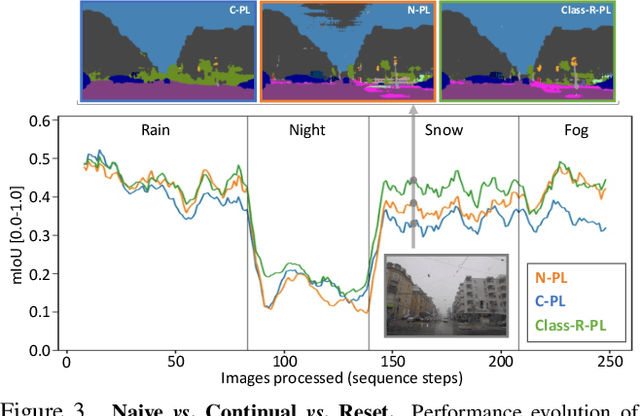
We propose a new problem formulation and a corresponding evaluation framework to advance research on unsupervised domain adaptation for semantic image segmentation. The overall goal is fostering the development of adaptive learning systems that will continuously learn, without supervision, in ever-changing environments. Typical protocols that study adaptation algorithms for segmentation models are limited to few domains, adaptation happens offline, and human intervention is generally required, at least to annotate data for hyper-parameter tuning. We argue that such constraints are incompatible with algorithms that can continuously adapt to different real-world situations. To address this, we propose a protocol where models need to learn online, from sequences of temporally correlated images, requiring continuous, frame-by-frame adaptation. We accompany this new protocol with a variety of baselines to tackle the proposed formulation, as well as an extensive analysis of their behaviors, which can serve as a starting point for future research.
Bridged Transformer for Vision and Point Cloud 3D Object Detection
Oct 04, 2022

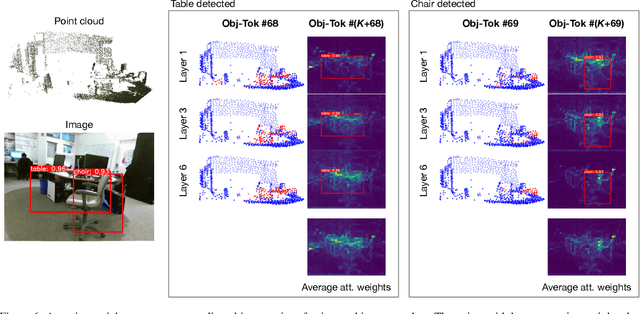
3D object detection is a crucial research topic in computer vision, which usually uses 3D point clouds as input in conventional setups. Recently, there is a trend of leveraging multiple sources of input data, such as complementing the 3D point cloud with 2D images that often have richer color and fewer noises. However, due to the heterogeneous geometrics of the 2D and 3D representations, it prevents us from applying off-the-shelf neural networks to achieve multimodal fusion. To that end, we propose Bridged Transformer (BrT), an end-to-end architecture for 3D object detection. BrT is simple and effective, which learns to identify 3D and 2D object bounding boxes from both points and image patches. A key element of BrT lies in the utilization of object queries for bridging 3D and 2D spaces, which unifies different sources of data representations in Transformer. We adopt a form of feature aggregation realized by point-to-patch projections which further strengthen the correlations between images and points. Moreover, BrT works seamlessly for fusing the point cloud with multi-view images. We experimentally show that BrT surpasses state-of-the-art methods on SUN RGB-D and ScanNetV2 datasets.
Data drift correction via time-varying importance weight estimator
Oct 04, 2022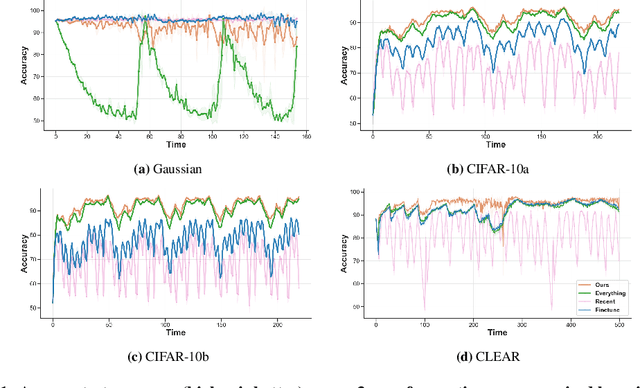

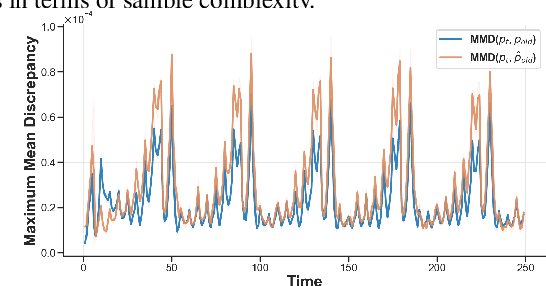
Real-world deployment of machine learning models is challenging when data evolves over time. And data does evolve over time. While no model can work when data evolves in an arbitrary fashion, if there is some pattern to these changes, we might be able to design methods to address it. This paper addresses situations when data evolves gradually. We introduce a novel time-varying importance weight estimator that can detect gradual shifts in the distribution of data. Such an importance weight estimator allows the training method to selectively sample past data -- not just similar data from the past like a standard importance weight estimator would but also data that evolved in a similar fashion in the past. Our time-varying importance weight is quite general. We demonstrate different ways of implementing it that exploit some known structure in the evolution of data. We demonstrate and evaluate this approach on a variety of problems ranging from supervised learning tasks (multiple image classification datasets) where the data undergoes a sequence of gradual shifts of our design to reinforcement learning tasks (robotic manipulation and continuous control) where data undergoes a shift organically as the policy or the task changes.