 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableMTL: Repurposing Latent Diffusion Models for Multi-Task Learning from Partially Annotated Synthetic Datasets
Jun 09, 2025



Multi-task learning for dense prediction is limited by the need for extensive annotation for every task, though recent works have explored training with partial task labels. Leveraging the generalization power of diffusion models, we extend the partial learning setup to a zero-shot setting, training a multi-task model on multiple synthetic datasets, each labeled for only a subset of tasks. Our method, StableMTL, repurposes image generators for latent regression. Adapting a denoising framework with task encoding, per-task conditioning and a tailored training scheme. Instead of per-task losses requiring careful balancing, a unified latent loss is adopted, enabling seamless scaling to more tasks. To encourage inter-task synergy, we introduce a multi-stream model with a task-attention mechanism that converts N-to-N task interactions into efficient 1-to-N attention, promoting effective cross-task sharing. StableMTL outperforms baselines on 7 tasks across 8 benchmarks.
LiDPM: Rethinking Point Diffusion for Lidar Scene Completion
Apr 24, 2025Training diffusion models that work directly on lidar points at the scale of outdoor scenes is challenging due to the difficulty of generating fine-grained details from white noise over a broad field of view. The latest works addressing scene completion with diffusion models tackle this problem by reformulating the original DDPM as a local diffusion process. It contrasts with the common practice of operating at the level of objects, where vanilla DDPMs are currently used. In this work, we close the gap between these two lines of work. We identify approximations in the local diffusion formulation, show that they are not required to operate at the scene level, and that a vanilla DDPM with a well-chosen starting point is enough for completion. Finally, we demonstrate that our method, LiDPM, leads to better results in scene completion on SemanticKITTI. The project page is https://astra-vision.github.io/LiDPM .
FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
Apr 14, 2025



Recent Open-Vocabulary Semantic Segmentation (OVSS) models extend the CLIP model to segmentation while maintaining the use of multiple templates (e.g., a photo of <class>, a sketch of a <class>, etc.) for constructing class-wise averaged text embeddings, acting as a classifier. In this paper, we challenge this status quo and investigate the impact of templates for OVSS. Empirically, we observe that for each class, there exist single-template classifiers significantly outperforming the conventional averaged classifier. We refer to them as class-experts. Given access to unlabeled images and without any training involved, we estimate these experts by leveraging the class-wise prediction entropy of single-template classifiers, selecting as class-wise experts those which yield the lowest entropy. All experts, each specializing in a specific class, collaborate in a newly proposed fusion method to generate more accurate OVSS predictions. Our plug-and-play method, coined FLOSS, is orthogonal and complementary to existing OVSS methods, offering a ''free lunch'' to systematically improve OVSS without labels and additional training. Extensive experiments demonstrate that FLOSS consistently boosts state-of-the-art methods on various OVSS benchmarks. Moreover, the selected expert templates can generalize well from one dataset to others sharing the same semantic categories, yet exhibiting distribution shifts. Additionally, we obtain satisfactory improvements under a low-data regime, where only a few unlabeled images are available. Our code is available at https://github.com/yasserben/FLOSS .
MatSwap: Light-aware material transfers in images
Feb 11, 2025



We present MatSwap, a method to transfer materials to designated surfaces in an image photorealistically. Such a task is non-trivial due to the large entanglement of material appearance, geometry, and lighting in a photograph. In the literature, material editing methods typically rely on either cumbersome text engineering or extensive manual annotations requiring artist knowledge and 3D scene properties that are impractical to obtain. In contrast, we propose to directly learn the relationship between the input material -- as observed on a flat surface -- and its appearance within the scene, without the need for explicit UV mapping. To achieve this, we rely on a custom light- and geometry-aware diffusion model. We fine-tune a large-scale pre-trained text-to-image model for material transfer using our synthetic dataset, preserving its strong priors to ensure effective generalization to real images. As a result, our method seamlessly integrates a desired material into the target location in the photograph while retaining the identity of the scene. We evaluate our method on synthetic and real images and show that it compares favorably to recent work both qualitatively and quantitatively. We will release our code and data upon publication.
Material Transforms from Disentangled NeRF Representations
Nov 12, 2024



In this paper, we first propose a novel method for transferring material transformations across different scenes. Building on disentangled Neural Radiance Field (NeRF) representations, our approach learns to map Bidirectional Reflectance Distribution Functions (BRDF) from pairs of scenes observed in varying conditions, such as dry and wet. The learned transformations can then be applied to unseen scenes with similar materials, therefore effectively rendering the transformation learned with an arbitrary level of intensity. Extensive experiments on synthetic scenes and real-world objects validate the effectiveness of our approach, showing that it can learn various transformations such as wetness, painting, coating, etc. Our results highlight not only the versatility of our method but also its potential for practical applications in computer graphics. We publish our method implementation, along with our synthetic/real datasets on https://github.com/astra-vision/BRDFTransform
Domain Adaptation with a Single Vision-Language Embedding
Oct 28, 2024



Domain adaptation has been extensively investigated in computer vision but still requires access to target data at the training time, which might be difficult to obtain in some uncommon conditions. In this paper, we present a new framework for domain adaptation relying on a single Vision-Language (VL) latent embedding instead of full target data. First, leveraging a contrastive language-image pre-training model (CLIP), we propose prompt/photo-driven instance normalization (PIN). PIN is a feature augmentation method that mines multiple visual styles using a single target VL latent embedding, by optimizing affine transformations of low-level source features. The VL embedding can come from a language prompt describing the target domain, a partially optimized language prompt, or a single unlabeled target image. Second, we show that these mined styles (i.e., augmentations) can be used for zero-shot (i.e., target-free) and one-shot unsupervised domain adaptation. Experiments on semantic segmentation demonstrate the effectiveness of the proposed method, which outperforms relevant baselines in the zero-shot and one-shot settings.
LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
Oct 10, 2024



Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
Fine-Tuning CLIP's Last Visual Projector: A Few-Shot Cornucopia
Oct 07, 2024



We consider the problem of adapting a contrastively pretrained vision-language model like CLIP (Radford et al., 2021) for few-shot classification. The existing literature addresses this problem by learning a linear classifier of the frozen visual features, optimizing word embeddings, or learning external feature adapters. This paper introduces an alternative way for CLIP adaptation without adding 'external' parameters to optimize. We find that simply fine-tuning the last projection matrix of the vision encoder leads to strong performance compared to the existing baselines. Furthermore, we show that regularizing training with the distance between the fine-tuned and pretrained matrices adds reliability for adapting CLIP through this layer. Perhaps surprisingly, this approach, coined ProLIP, yields performances on par or better than state of the art on 11 few-shot classification benchmarks, few-shot domain generalization, cross-dataset transfer and test-time adaptation. Code will be made available at https://github.com/astra-vision/ProLIP .
UMBRAE: Unified Multimodal Decoding of Brain Signals
Apr 10, 2024
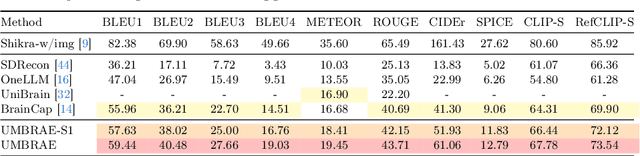
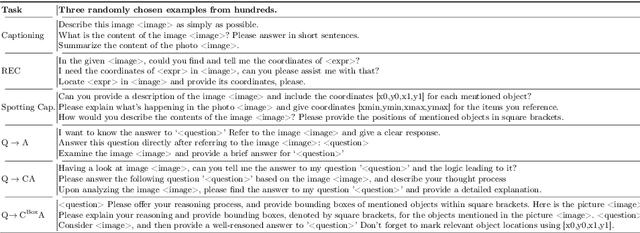
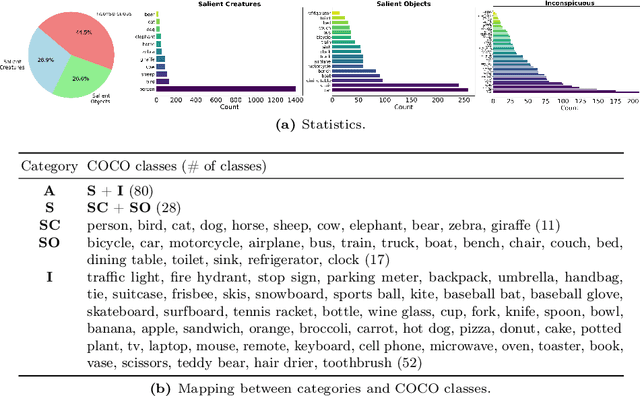
We address prevailing challenges of the brain-powered research, departing from the observation that the literature hardly recover accurate spatial information and require subject-specific models. To address these challenges, we propose UMBRAE, a unified multimodal decoding of brain signals. First, to extract instance-level conceptual and spatial details from neural signals, we introduce an efficient universal brain encoder for multimodal-brain alignment and recover object descriptions at multiple levels of granularity from subsequent multimodal large language model (MLLM). Second, we introduce a cross-subject training strategy mapping subject-specific features to a common feature space. This allows a model to be trained on multiple subjects without extra resources, even yielding superior results compared to subject-specific models. Further, we demonstrate this supports weakly-supervised adaptation to new subjects, with only a fraction of the total training data. Experiments demonstrate that UMBRAE not only achieves superior results in the newly introduced tasks but also outperforms methods in well established tasks. To assess our method, we construct and share with the community a comprehensive brain understanding benchmark BrainHub. Our code and benchmark are available at https://weihaox.github.io/UMBRAE.
PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
Dec 04, 2023



We propose the task of Panoptic Scene Completion (PSC) which extends the recently popular Semantic Scene Completion (SSC) task with instance-level information to produce a richer understanding of the 3D scene. Our PSC proposal utilizes a hybrid mask-based technique on the non-empty voxels from sparse multi-scale completions. Whereas the SSC literature overlooks uncertainty which is critical for robotics applications, we instead propose an efficient ensembling to estimate both voxel-wise and instance-wise uncertainties along PSC. This is achieved by building on a multi-input multi-output (MIMO) strategy, while improving performance and yielding better uncertainty for little additional compute. Additionally, we introduce a technique to aggregate permutation-invariant mask predictions. Our experiments demonstrate that our method surpasses all baselines in both Panoptic Scene Completion and uncertainty estimation on three large-scale autonomous driving datasets. Our code and data are available at https://astra-vision.github.io/PaSCo .