 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SliceMatch: Geometry-guided Aggregation for Cross-View Pose Estimation
Nov 26, 2022
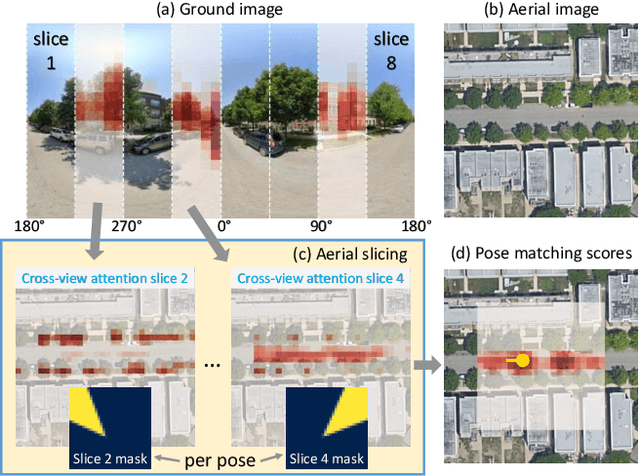
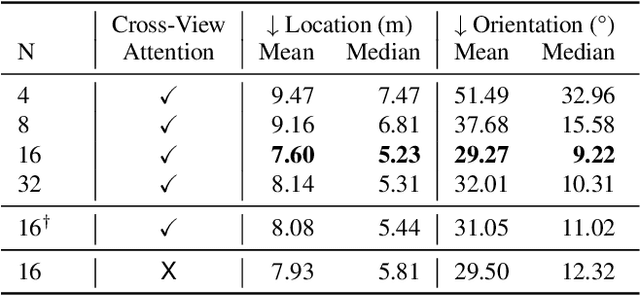
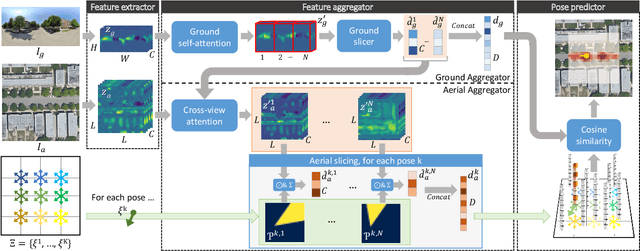
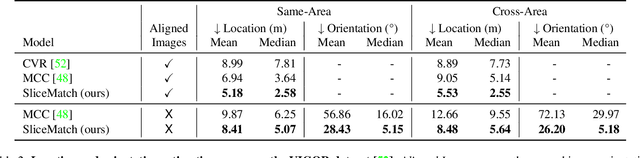
This work addresses cross-view camera pose estimation, i.e., determining the 3-DoF camera pose of a given ground-level image w.r.t. an aerial image of the local area. We propose SliceMatch, which consists of ground and aerial feature extractors, feature aggregators, and a pose predictor. The feature extractors extract dense features from the ground and aerial images. Given a set of candidate camera poses, the feature aggregators construct a single ground descriptor and a set of rotational equivariant pose-dependent aerial descriptors. Notably, our novel aerial feature aggregator has a cross-view attention module for ground-view guided aerial feature selection, and utilizes the geometric projection of the ground camera's viewing frustum on the aerial image to pool features. The efficient construction of aerial descriptors is achieved by using precomputed masks and by re-assembling the aerial descriptors for rotated poses. SliceMatch is trained using contrastive learning and pose estimation is formulated as a similarity comparison between the ground descriptor and the aerial descriptors. SliceMatch outperforms the state-of-the-art by 19% and 62% in median localization error on the VIGOR and KITTI datasets, with 3x FPS of the fastest baseline.
Iterative Optimization of Pseudo Ground-Truth Face Image Quality Labels
Aug 31, 2022While recent face recognition (FR) systems achieve excellent results in many deployment scenarios, their performance in challenging real-world settings is still under question. For this reason, face image quality assessment (FIQA) techniques aim to support FR systems, by providing them with sample quality information that can be used to reject poor quality data unsuitable for recognition purposes. Several groups of FIQA methods relying on different concepts have been proposed in the literature, all of which can be used for generating quality scores of facial images that can serve as pseudo ground-truth (quality) labels and can be exploited for training (regression-based) quality estimation models. Several FIQA appro\-aches show that a significant amount of sample-quality information can be extracted from mated similarity-score distributions generated with some face matcher. Based on this insight, we propose in this paper a quality label optimization approach, which incorporates sample-quality information from mated-pair similarities into quality predictions of existing off-the-shelf FIQA techniques. We evaluate the proposed approach using three state-of-the-art FIQA methods over three diverse datasets. The results of our experiments show that the proposed optimization procedure heavily depends on the number of executed optimization iterations. At ten iterations, the approach seems to perform the best, consistently outperforming the base quality scores of the three FIQA methods, chosen for the experiments.
Improving Zero-shot Generalization and Robustness of Multi-modal Models
Dec 04, 2022
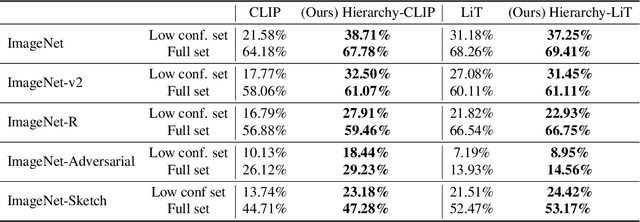
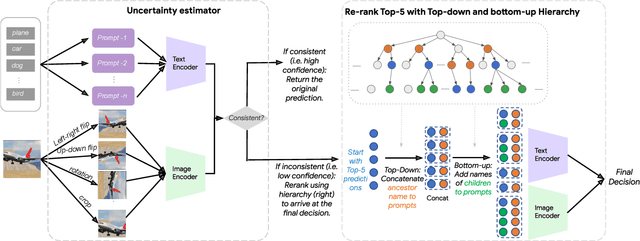
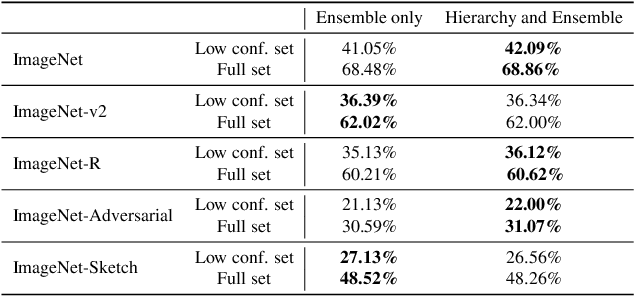
Multi-modal image-text models such as CLIP and LiT have demonstrated impressive performance on image classification benchmarks and their zero-shot generalization ability is particularly exciting. While the top-5 zero-shot accuracies of these models are very high, the top-1 accuracies are much lower (over 25% gap in some cases). We investigate the reasons for this performance gap and find that many of the failure cases are caused by ambiguity in the text prompts. First, we develop a simple and efficient zero-shot post-hoc method to identify images whose top-1 prediction is likely to be incorrect, by measuring consistency of the predictions w.r.t. multiple prompts and image transformations. We show that our procedure better predicts mistakes, outperforming the popular max logit baseline on selective prediction tasks. Next, we propose a simple and efficient way to improve accuracy on such uncertain images by making use of the WordNet hierarchy; specifically we augment the original class by incorporating its parent and children from the semantic label hierarchy, and plug the augmentation into text promts. We conduct experiments on both CLIP and LiT models with five different ImageNet-based datasets. For CLIP, our method improves the top-1 accuracy by 17.13% on the uncertain subset and 3.6% on the entire ImageNet validation set. We also show that our method improves across ImageNet shifted datasets and other model architectures such as LiT. Our proposed method is hyperparameter-free, requires no additional model training and can be easily scaled to other large multi-modal architectures.
Minimum Noticeable Difference based Adversarial Privacy Preserving Image Generation
Jun 17, 2022
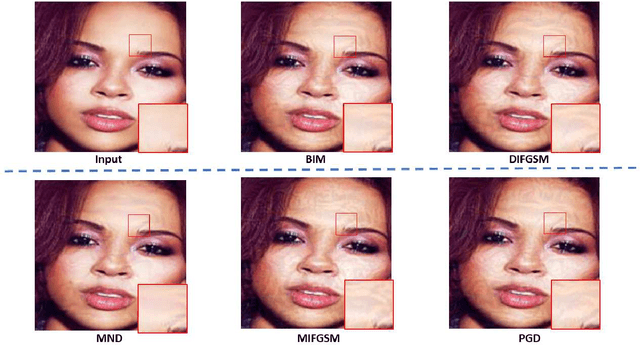
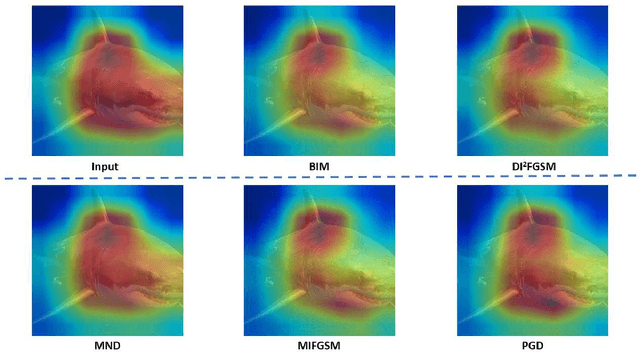

Deep learning models are found to be vulnerable to adversarial examples, as wrong predictions can be caused by small perturbation in input for deep learning models. Most of the existing works of adversarial image generation try to achieve attacks for most models, while few of them make efforts on guaranteeing the perceptual quality of the adversarial examples. High quality adversarial examples matter for many applications, especially for the privacy preserving. In this work, we develop a framework based on the Minimum Noticeable Difference (MND) concept to generate adversarial privacy preserving images that have minimum perceptual difference from the clean ones but are able to attack deep learning models. To achieve this, an adversarial loss is firstly proposed to make the deep learning models attacked by the adversarial images successfully. Then, a perceptual quality-preserving loss is developed by taking the magnitude of perturbation and perturbation-caused structural and gradient changes into account, which aims to preserve high perceptual quality for adversarial image generation. To the best of our knowledge, this is the first work on exploring quality-preserving adversarial image generation based on the MND concept for privacy preserving. To evaluate its performance in terms of perceptual quality, the deep models on image classification and face recognition are tested with the proposed method and several anchor methods in this work. Extensive experimental results demonstrate that the proposed MND framework is capable of generating adversarial images with remarkably improved performance metrics (e.g., PSNR, SSIM, and MOS) than that generated with the anchor methods.
Data-aware customization of activation functions reduces neural network error
Jan 16, 2023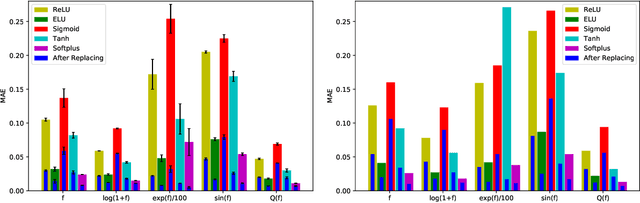
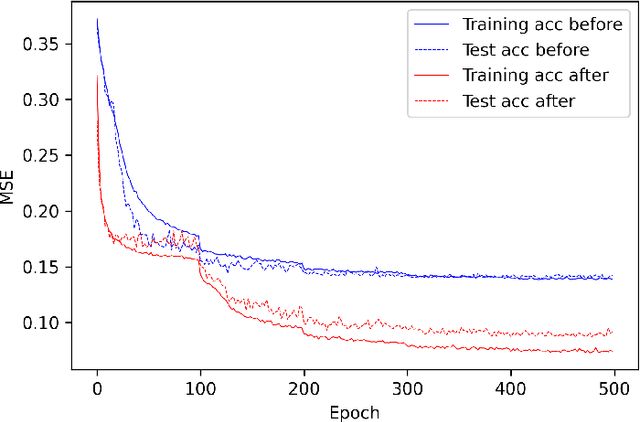
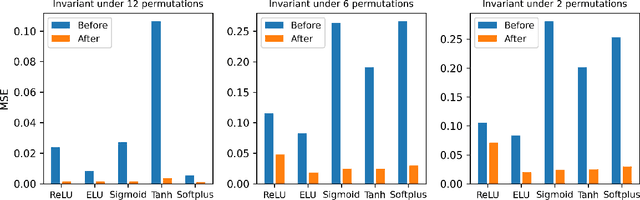
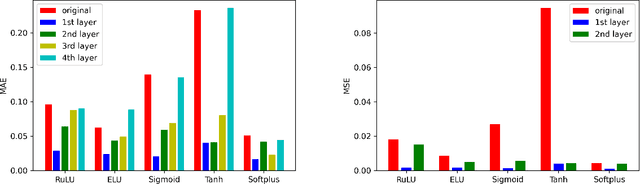
Activation functions play critical roles in neural networks, yet current off-the-shelf neural networks pay little attention to the specific choice of activation functions used. Here we show that data-aware customization of activation functions can result in striking reductions in neural network error. We first give a simple linear algebraic explanation of the role of activation functions in neural networks; then, through connection with the Diaconis-Shahshahani Approximation Theorem, we propose a set of criteria for good activation functions. As a case study, we consider regression tasks with a partially exchangeable target function, \emph{i.e.} $f(u,v,w)=f(v,u,w)$ for $u,v\in \mathbb{R}^d$ and $w\in \mathbb{R}^k$, and prove that for such a target function, using an even activation function in at least one of the layers guarantees that the prediction preserves partial exchangeability for best performance. Since even activation functions are seldom used in practice, we designed the ``seagull'' even activation function $\log(1+x^2)$ according to our criteria. Empirical testing on over two dozen 9-25 dimensional examples with different local smoothness, curvature, and degree of exchangeability revealed that a simple substitution with the ``seagull'' activation function in an already-refined neural network can lead to an order-of-magnitude reduction in error. This improvement was most pronounced when the activation function substitution was applied to the layer in which the exchangeable variables are connected for the first time. While the improvement is greatest for low-dimensional data, experiments on the CIFAR10 image classification dataset showed that use of ``seagull'' can reduce error even for high-dimensional cases. These results collectively highlight the potential of customizing activation functions as a general approach to improve neural network performance.
Evaluating the Practicality of Learned Image Compression
Jul 29, 2022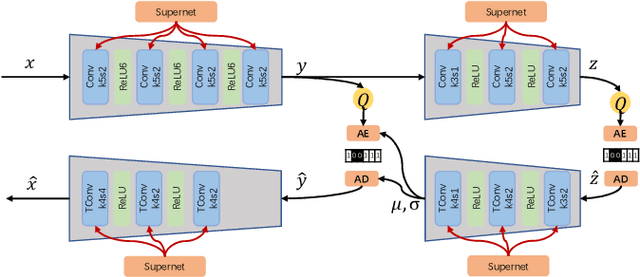
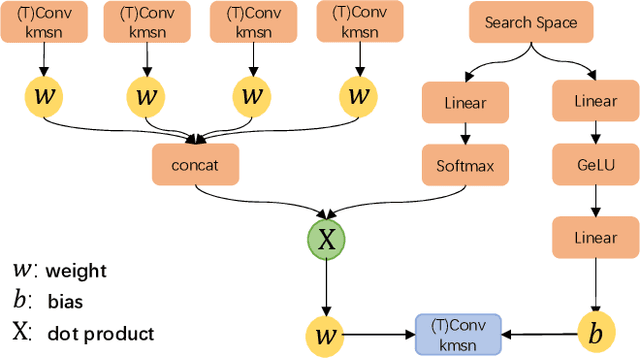
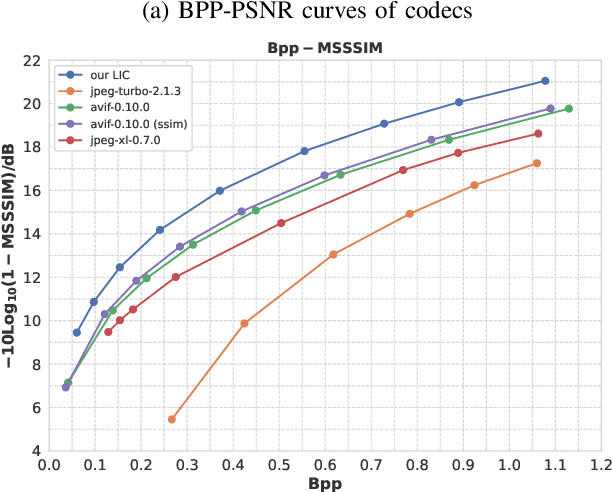
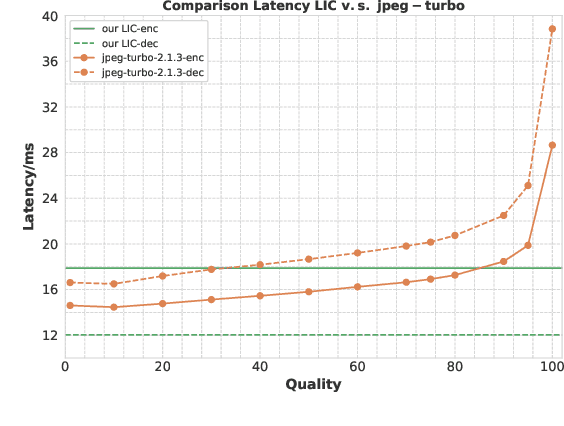
Learned image compression has achieved extraordinary rate-distortion performance in PSNR and MS-SSIM compared to traditional methods. However, it suffers from intensive computation, which is intolerable for real-world applications and leads to its limited industrial application for now. In this paper, we introduce neural architecture search (NAS) to designing more efficient networks with lower latency, and leverage quantization to accelerate the inference process. Meanwhile, efforts in engineering like multi-threading and SIMD have been made to improve efficiency. Optimized using a hybrid loss of PSNR and MS-SSIM for better visual quality, we obtain much higher MS-SSIM than JPEG, JPEG XL and AVIF over all bit rates, and PSNR between that of JPEG XL and AVIF. Our software implementation of LIC achieves comparable or even faster inference speed compared to jpeg-turbo while being multiple times faster than JPEG XL and AVIF. Besides, our implementation of LIC reaches stunning throughput of 145 fps for encoding and 208 fps for decoding on a Tesla T4 GPU for 1080p images. On CPU, the latency of our implementation is comparable with JPEG XL.
Decay2Distill: Leveraging spatial perturbation and regularization for self-supervised image denoising
Aug 04, 2022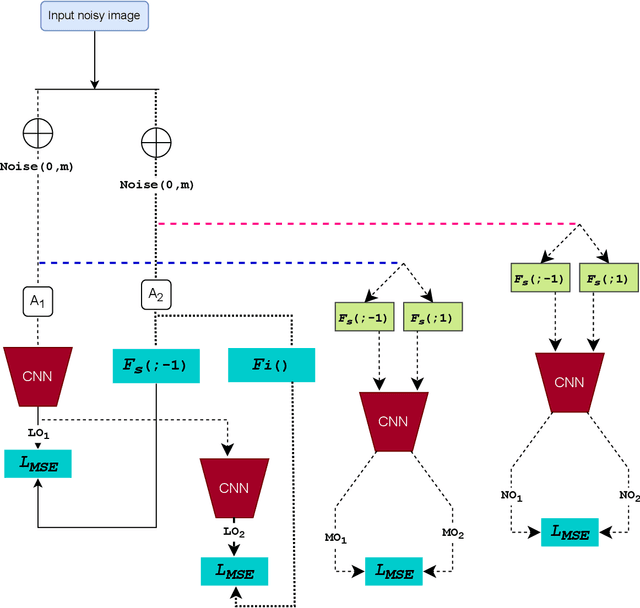
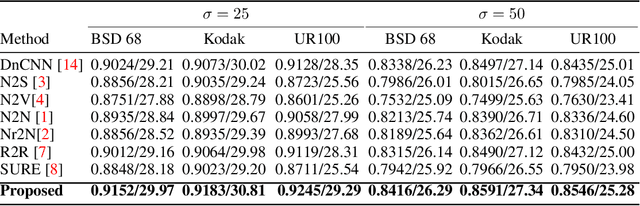

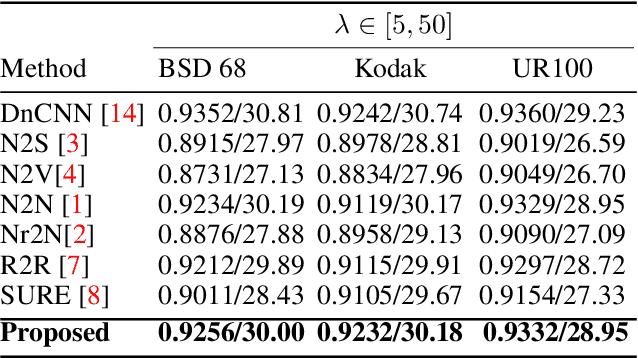
Unpaired image denoising has achieved promising development over the last few years. Regardless of the performance, methods tend to heavily rely on underlying noise properties or any assumption which is not always practical. Alternatively, if we can ground the problem from a structural perspective rather than noise statistics, we can achieve a more robust solution. with such motivation, we propose a self-supervised denoising scheme that is unpaired and relies on spatial degradation followed by a regularized refinement. Our method shows considerable improvement over previous methods and exhibited consistent performance over different data domains.
Semi-Supervised Domain Adaptation for Semantic Segmentation of Roads from Satellite Images
Dec 26, 2022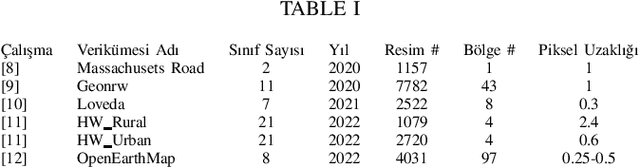
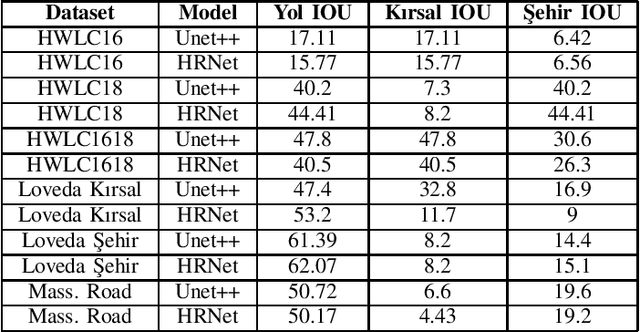
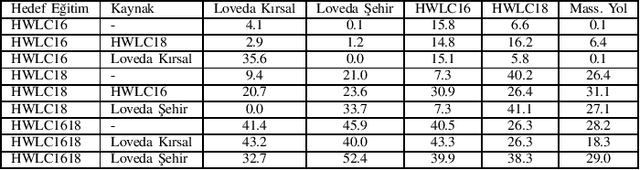
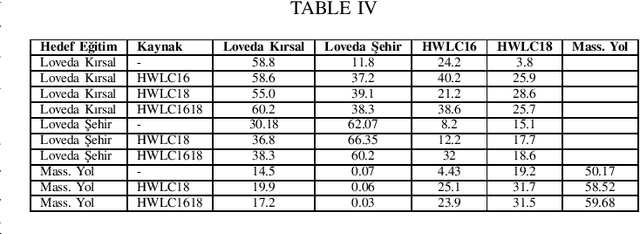
This paper presents the preliminary findings of a semi-supervised segmentation method for extracting roads from sattelite images. Artificial Neural Networks and image segmentation methods are among the most successful methods for extracting road data from satellite images. However, these models require large amounts of training data from different regions to achieve high accuracy rates. In cases where this data needs to be of more quantity or quality, it is a standard method to train deep neural networks by transferring knowledge from annotated data obtained from different sources. This study proposes a method that performs path segmentation with semi-supervised learning methods. A semi-supervised field adaptation method based on pseudo-labeling and Minimum Class Confusion method has been proposed, and it has been observed to increase performance in targeted datasets.
FRIH: Fine-grained Region-aware Image Harmonization
May 13, 2022

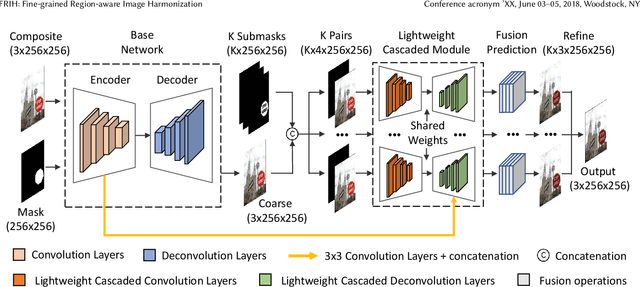
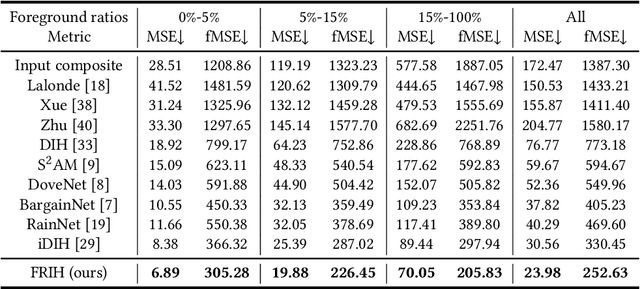
Image harmonization aims to generate a more realistic appearance of foreground and background for a composite image. Existing methods perform the same harmonization process for the whole foreground. However, the implanted foreground always contains different appearance patterns. All the existing solutions ignore the difference of each color block and losing some specific details. Therefore, we propose a novel global-local two stages framework for Fine-grained Region-aware Image Harmonization (FRIH), which is trained end-to-end. In the first stage, the whole input foreground mask is used to make a global coarse-grained harmonization. In the second stage, we adaptively cluster the input foreground mask into several submasks by the corresponding pixel RGB values in the composite image. Each submask and the coarsely adjusted image are concatenated respectively and fed into a lightweight cascaded module, adjusting the global harmonization performance according to the region-aware local feature. Moreover, we further designed a fusion prediction module by fusing features from all the cascaded decoder layers together to generate the final result, which could utilize the different degrees of harmonization results comprehensively. Without bells and whistles, our FRIH algorithm achieves the best performance on iHarmony4 dataset (PSNR is 38.19 dB) with a lightweight model. The parameters for our model are only 11.98 M, far below the existing methods.
On Learning the Structure of Clusters in Graphs
Dec 29, 2022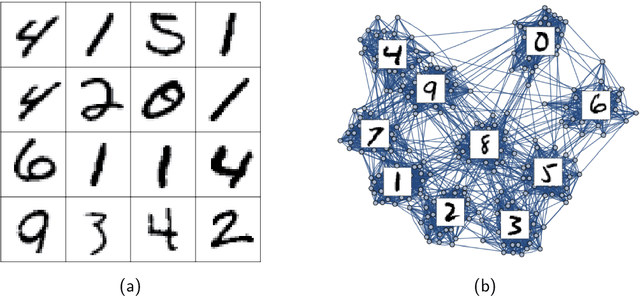

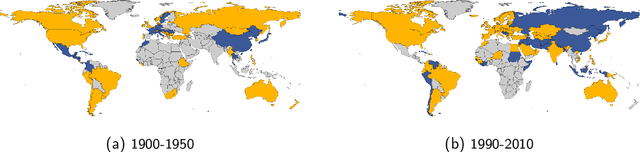
Graph clustering is a fundamental problem in unsupervised learning, with numerous applications in computer science and in analysing real-world data. In many real-world applications, we find that the clusters have a significant high-level structure. This is often overlooked in the design and analysis of graph clustering algorithms which make strong simplifying assumptions about the structure of the graph. This thesis addresses the natural question of whether the structure of clusters can be learned efficiently and describes four new algorithmic results for learning such structure in graphs and hypergraphs. All of the presented theoretical results are extensively evaluated on both synthetic and real-word datasets of different domains, including image classification and segmentation, migration networks, co-authorship networks, and natural language processing. These experimental results demonstrate that the newly developed algorithms are practical, effective, and immediately applicable for learning the structure of clusters in real-world data.