 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Satellite Imagery and Planimetric Maps for Cross-View Localization
Jun 08, 2026Current cross-view localization methods predominantly rely on satellite imagery as the aerial modality. Although recent work explores planimetric maps (e.g., OpenStreetMap tiles), these approaches often lag in performance. Yet both modalities are widely available and possess complementary properties. Satellite images are closer to ground-level camera imagery, offering finer detail, whereas planimetric maps contain annotated objects (e.g., streetlamps) and remain informative in areas where the ground is occluded, such as by foliage. Despite this, only one prior work provides an end-to-end method to fuse the two modalities, and it does not demonstrate their potential within state-of-the-art methods. To combine the strengths of both modalities, we propose a new fusion module that augments standard encoders and demonstrates that integrating satellite imagery with planimetric maps improves state-of-the-art single-modality methods. The module comprises (i) cross-modal conditioning, which processes each modality's encoding with awareness of the other, and (ii) a patch-level fusion rule that controls the granularity of information exchange. We achieve state-of-the-art results, reducing the mean localization error by 30.13\%. Qualitatively, the fusion adaptively selects the more informative modality, improving overall accuracy.
Drift-Resistant Navigation World Model with Anchored Epipolar Guidance
May 23, 2026We propose Drift-Resistant Navigation World Model, a generative model that mitigates both perceptual drift and geometric drift in conventional rollout-based navigation world models. Existing methods recursively feed generated content into subsequent steps, causing noise accumulation and degraded predictions, i.e., perceptual drift. Meanwhile, their predictions often deviate from the agent's motion, resulting in geometry drift. We address both types of drift by redesigning world-model prediction as an anchor-guided rollout. Instead of rolling out every frame sequentially, we first predict sparse future anchors that serve as stable long-range targets, and then generate intermediate frames within each chunk conditioned on both past context and future anchors. Importantly, these sparse anchors also provide geometric constraints, supported by bidirectional epipolar geometry, to localize where corresponding content should appear in the intermediate frames. Experiments on four benchmarks demonstrate consistent improvements over strong baselines in long-horizon visual quality, geometric consistency, and multi-view coherence. These gains further translate into improved downstream planning performance under the same planners, highlighting the importance of drift-resistant, geometry-aware prediction for reliable navigation world models.
Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
May 14, 2026Generating a street-level 3D scene from a single satellite image is a crucial yet challenging task. Current methods present a stark trade-off: geometry-colorization models achieve high geometric fidelity but are typically building-focused and lack semantic diversity. In contrast, proxy-based models use feed-forward image-to-3D frameworks to generate holistic scenes by jointly learning geometry and texture, a process that yields rich content but coarse and unstable geometry. We attribute these geometric failures to the extreme viewpoint gap and sparse, inconsistent supervision inherent in satellite-to-street data. We introduce Sat3DGen to address these fundamental challenges, which embodies a geometry-first methodology. This methodology enhances the feed-forward paradigm by integrating novel geometric constraints with a perspective-view training strategy, explicitly countering the primary sources of geometric error. This geometry-centric strategy yields a dramatic leap in both 3D accuracy and photorealism. For validation, we first constructed a new benchmark by pairing the VIGOR-OOD test set with high-resolution DSM data. On this benchmark, our method improves geometric RMSE from 6.76m to 5.20m. Crucially, this geometric leap also boosts photorealism, reducing the Fréchet Inception Distance (FID) from $\sim$40 to 19 against the leading method, Sat2Density++, despite using no extra tailored image-quality modules. We demonstrate the versatility of our high-quality 3D assets through diverse downstream applications, including semantic-map-to-3D synthesis, multi-camera video generation, large-scale meshing, and unsupervised single-image Digital Surface Model (DSM) estimation. The code has been released on https://github.com/qianmingduowan/Sat3DGen.
A Vehicle System for Navigating Among Vulnerable Road Users Including Remote Operation
May 08, 2025



We present a vehicle system capable of navigating safely and efficiently around Vulnerable Road Users (VRUs), such as pedestrians and cyclists. The system comprises key modules for environment perception, localization and mapping, motion planning, and control, integrated into a prototype vehicle. A key innovation is a motion planner based on Topology-driven Model Predictive Control (T-MPC). The guidance layer generates multiple trajectories in parallel, each representing a distinct strategy for obstacle avoidance or non-passing. The underlying trajectory optimization constrains the joint probability of collision with VRUs under generic uncertainties. To address extraordinary situations ("edge cases") that go beyond the autonomous capabilities - such as construction zones or encounters with emergency responders - the system includes an option for remote human operation, supported by visual and haptic guidance. In simulation, our motion planner outperforms three baseline approaches in terms of safety and efficiency. We also demonstrate the full system in prototype vehicle tests on a closed track, both in autonomous and remotely operated modes.
CoMatcher: Multi-View Collaborative Feature Matching
Apr 02, 2025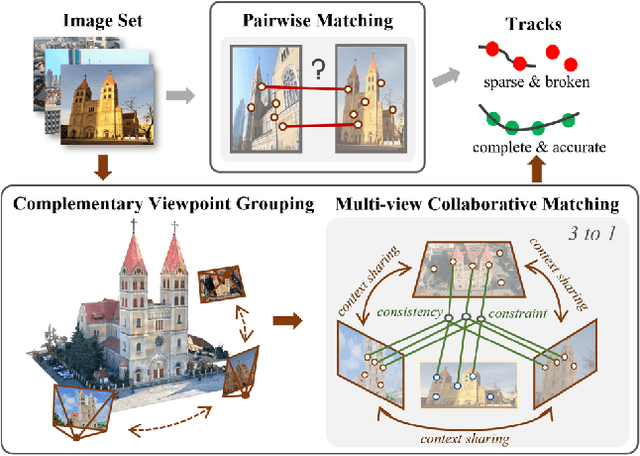



This paper proposes a multi-view collaborative matching strategy for reliable track construction in complex scenarios. We observe that the pairwise matching paradigms applied to image set matching often result in ambiguous estimation when the selected independent pairs exhibit significant occlusions or extreme viewpoint changes. This challenge primarily stems from the inherent uncertainty in interpreting intricate 3D structures based on limited two-view observations, as the 3D-to-2D projection leads to significant information loss. To address this, we introduce CoMatcher, a deep multi-view matcher to (i) leverage complementary context cues from different views to form a holistic 3D scene understanding and (ii) utilize cross-view projection consistency to infer a reliable global solution. Building on CoMatcher, we develop a groupwise framework that fully exploits cross-view relationships for large-scale matching tasks. Extensive experiments on various complex scenarios demonstrate the superiority of our method over the mainstream two-view matching paradigm.
* 15 pages, 7 figures, to be published in CVPR 2025
FG$^2$: Fine-Grained Cross-View Localization by Fine-Grained Feature Matching
Mar 24, 2025We propose a novel fine-grained cross-view localization method that estimates the 3 Degrees of Freedom pose of a ground-level image in an aerial image of the surroundings by matching fine-grained features between the two images. The pose is estimated by aligning a point plane generated from the ground image with a point plane sampled from the aerial image. To generate the ground points, we first map ground image features to a 3D point cloud. Our method then learns to select features along the height dimension to pool the 3D points to a Bird's-Eye-View (BEV) plane. This selection enables us to trace which feature in the ground image contributes to the BEV representation. Next, we sample a set of sparse matches from computed point correspondences between the two point planes and compute their relative pose using Procrustes alignment. Compared to the previous state-of-the-art, our method reduces the mean localization error by 28% on the VIGOR cross-area test set. Qualitative results show that our method learns semantically consistent matches across ground and aerial views through weakly supervised learning from the camera pose.
Adapting Fine-Grained Cross-View Localization to Areas without Fine Ground Truth
Jun 01, 2024Given a ground-level query image and a geo-referenced aerial image that covers the query's local surroundings, fine-grained cross-view localization aims to estimate the location of the ground camera inside the aerial image. Recent works have focused on developing advanced networks trained with accurate ground truth (GT) locations of ground images. However, the trained models always suffer a performance drop when applied to images in a new target area that differs from training. In most deployment scenarios, acquiring fine GT, i.e. accurate GT locations, for target-area images to re-train the network can be expensive and sometimes infeasible. In contrast, collecting images with noisy GT with errors of tens of meters is often easy. Motivated by this, our paper focuses on improving the performance of a trained model in a new target area by leveraging only the target-area images without fine GT. We propose a weakly supervised learning approach based on knowledge self-distillation. This approach uses predictions from a pre-trained model as pseudo GT to supervise a copy of itself. Our approach includes a mode-based pseudo GT generation for reducing uncertainty in pseudo GT and an outlier filtering method to remove unreliable pseudo GT. Our approach is validated using two recent state-of-the-art models on two benchmarks. The results demonstrate that it consistently and considerably boosts the localization accuracy in the target area.
Convolutional Cross-View Pose Estimation
Mar 09, 2023We propose a novel end-to-end method for cross-view pose estimation. Given a ground-level query image and an aerial image that covers the query's local neighborhood, the 3 Degrees-of-Freedom camera pose of the query is estimated by matching its image descriptor to descriptors of local regions within the aerial image. The orientation-aware descriptors are obtained by using a translational equivariant convolutional ground image encoder and contrastive learning. The Localization Decoder produces a dense probability distribution in a coarse-to-fine manner with a novel Localization Matching Upsampling module. A smaller Orientation Decoder produces a vector field to condition the orientation estimate on the localization. Our method is validated on the VIGOR and KITTI datasets, where it surpasses the state-of-the-art baseline by 72% and 36% in median localization error for comparable orientation estimation accuracy. The predicted probability distribution can represent localization ambiguity, and enables rejecting possible erroneous predictions. Without re-training, the model can infer on ground images with different field of views and utilize orientation priors if available. On the Oxford RobotCar dataset, our method can reliably estimate the ego-vehicle's pose over time, achieving a median localization error under 1 meter and a median orientation error of around 1 degree at 14 FPS.
SliceMatch: Geometry-guided Aggregation for Cross-View Pose Estimation
Dec 05, 2022



This work addresses cross-view camera pose estimation, i.e., determining the 3-DoF camera pose of a given ground-level image w.r.t. an aerial image of the local area. We propose SliceMatch, which consists of ground and aerial feature extractors, feature aggregators, and a pose predictor. The feature extractors extract dense features from the ground and aerial images. Given a set of candidate camera poses, the feature aggregators construct a single ground descriptor and a set of rotational equivariant pose-dependent aerial descriptors. Notably, our novel aerial feature aggregator has a cross-view attention module for ground-view guided aerial feature selection, and utilizes the geometric projection of the ground camera's viewing frustum on the aerial image to pool features. The efficient construction of aerial descriptors is achieved by using precomputed masks and by re-assembling the aerial descriptors for rotated poses. SliceMatch is trained using contrastive learning and pose estimation is formulated as a similarity comparison between the ground descriptor and the aerial descriptors. SliceMatch outperforms the state-of-the-art by 19% and 62% in median localization error on the VIGOR and KITTI datasets, with 3x FPS of the fastest baseline.
Visual Cross-View Metric Localization with Dense Uncertainty Estimates
Aug 17, 2022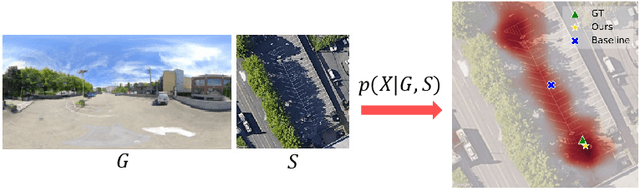

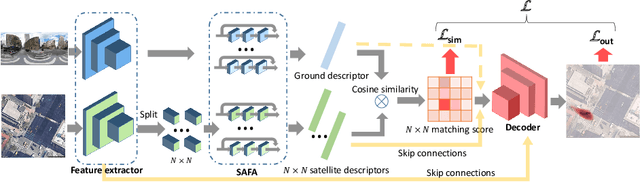
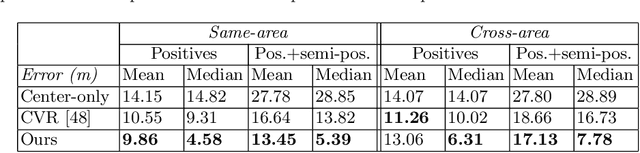
This work addresses visual cross-view metric localization for outdoor robotics. Given a ground-level color image and a satellite patch that contains the local surroundings, the task is to identify the location of the ground camera within the satellite patch. Related work addressed this task for range-sensors (LiDAR, Radar), but for vision, only as a secondary regression step after an initial cross-view image retrieval step. Since the local satellite patch could also be retrieved through any rough localization prior (e.g. from GPS/GNSS, temporal filtering), we drop the image retrieval objective and focus on the metric localization only. We devise a novel network architecture with denser satellite descriptors, similarity matching at the bottleneck (rather than at the output as in image retrieval), and a dense spatial distribution as output to capture multi-modal localization ambiguities. We compare against a state-of-the-art regression baseline that uses global image descriptors. Quantitative and qualitative experimental results on the recently proposed VIGOR and the Oxford RobotCar datasets validate our design. The produced probabilities are correlated with localization accuracy, and can even be used to roughly estimate the ground camera's heading when its orientation is unknown. Overall, our method reduces the median metric localization error by 51%, 37%, and 28% compared to the state-of-the-art when generalizing respectively in the same area, across areas, and across time.