 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Score-Guided Diffusion for 3D Human Recovery
Mar 14, 2024
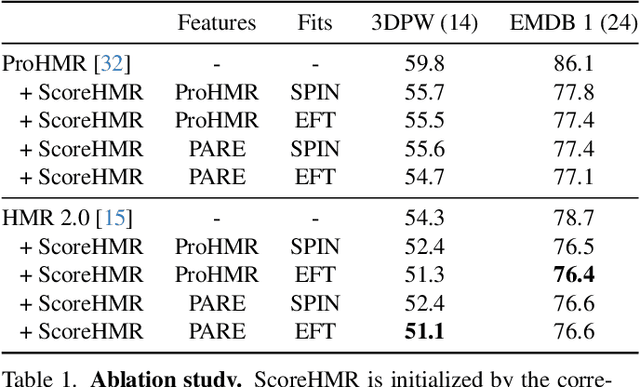
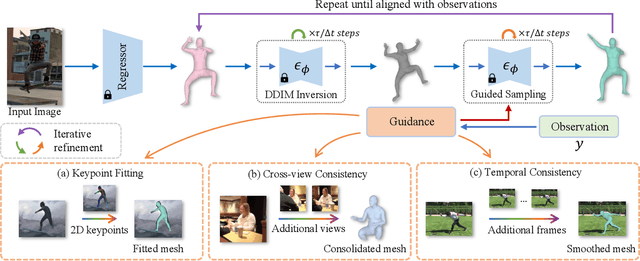
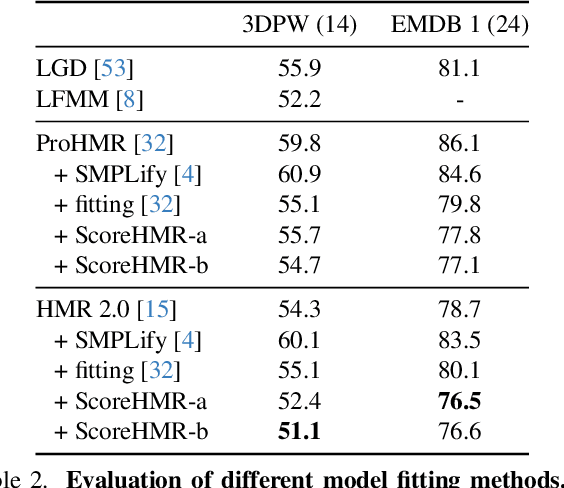
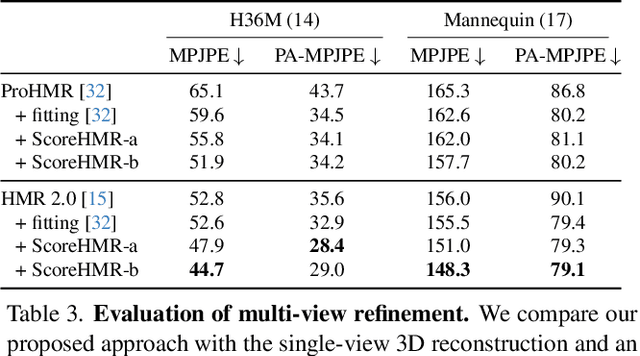
We present Score-Guided Human Mesh Recovery (ScoreHMR), an approach for solving inverse problems for 3D human pose and shape reconstruction. These inverse problems involve fitting a human body model to image observations, traditionally solved through optimization techniques. ScoreHMR mimics model fitting approaches, but alignment with the image observation is achieved through score guidance in the latent space of a diffusion model. The diffusion model is trained to capture the conditional distribution of the human model parameters given an input image. By guiding its denoising process with a task-specific score, ScoreHMR effectively solves inverse problems for various applications without the need for retraining the task-agnostic diffusion model. We evaluate our approach on three settings/applications. These are: (i) single-frame model fitting; (ii) reconstruction from multiple uncalibrated views; (iii) reconstructing humans in video sequences. ScoreHMR consistently outperforms all optimization baselines on popular benchmarks across all settings. We make our code and models available at the https://statho.github.io/ScoreHMR.
ProMark: Proactive Diffusion Watermarking for Causal Attribution
Mar 14, 2024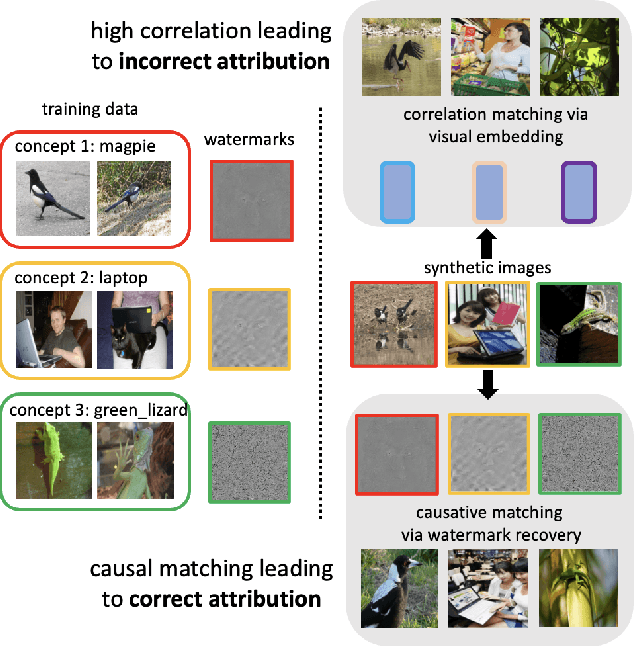
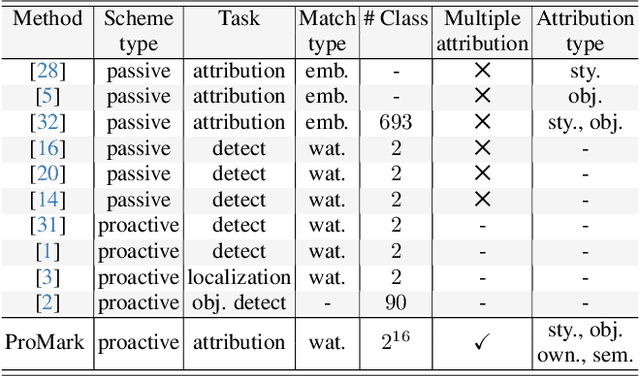
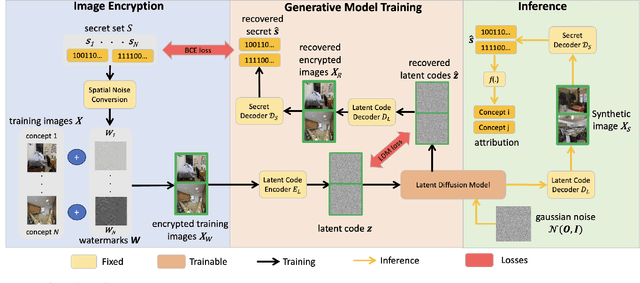
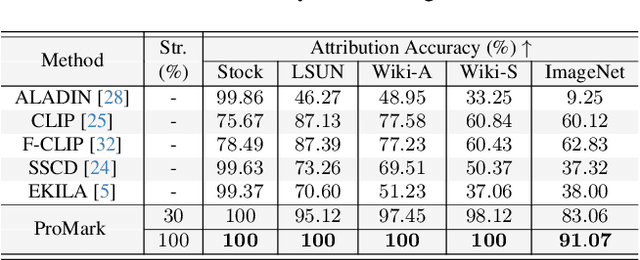
Generative AI (GenAI) is transforming creative workflows through the capability to synthesize and manipulate images via high-level prompts. Yet creatives are not well supported to receive recognition or reward for the use of their content in GenAI training. To this end, we propose ProMark, a causal attribution technique to attribute a synthetically generated image to its training data concepts like objects, motifs, templates, artists, or styles. The concept information is proactively embedded into the input training images using imperceptible watermarks, and the diffusion models (unconditional or conditional) are trained to retain the corresponding watermarks in generated images. We show that we can embed as many as $2^{16}$ unique watermarks into the training data, and each training image can contain more than one watermark. ProMark can maintain image quality whilst outperforming correlation-based attribution. Finally, several qualitative examples are presented, providing the confidence that the presence of the watermark conveys a causative relationship between training data and synthetic images.
Using evolutionary computation to optimize task performance of unclocked, recurrent Boolean circuits in FPGAs
Mar 19, 2024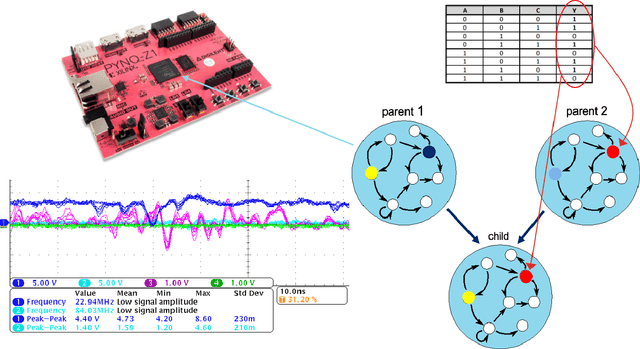
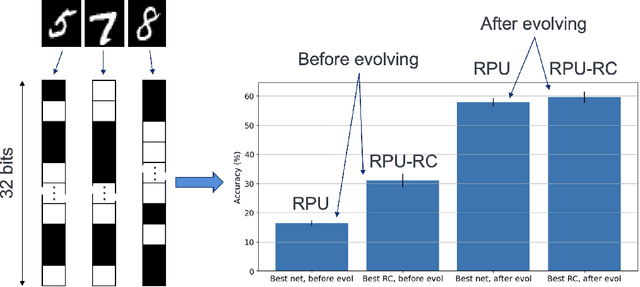
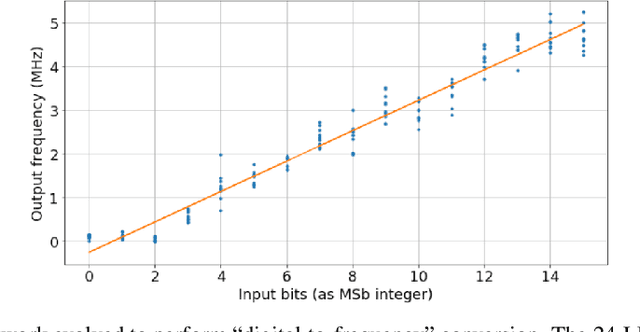
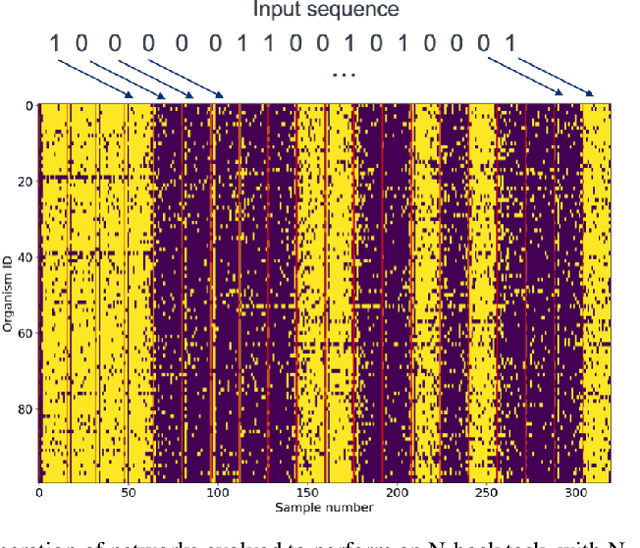
It has been shown that unclocked, recurrent networks of Boolean gates in FPGAs can be used for low-SWaP reservoir computing. In such systems, topology and node functionality of the network are randomly initialized. To create a network that solves a task, weights are applied to output nodes and learning is achieved by adjusting those weights with conventional machine learning methods. However, performance is often limited compared to networks where all parameters are learned. Herein, we explore an alternative learning approach for unclocked, recurrent networks in FPGAs. We use evolutionary computation to evolve the Boolean functions of network nodes. In one type of implementation the output nodes are used directly to perform a task and all learning is via evolution of the network's node functions. In a second type of implementation a back-end classifier is used as in traditional reservoir computing. In that case, both evolution of node functions and adjustment of output node weights contribute to learning. We demonstrate the practicality of node function evolution, obtaining an accuracy improvement of ~30% on an image classification task while processing at a rate of over three million samples per second. We additionally demonstrate evolvability of network memory and dynamic output signals.
Eye-gaze Guided Multi-modal Alignment Framework for Radiology
Mar 19, 2024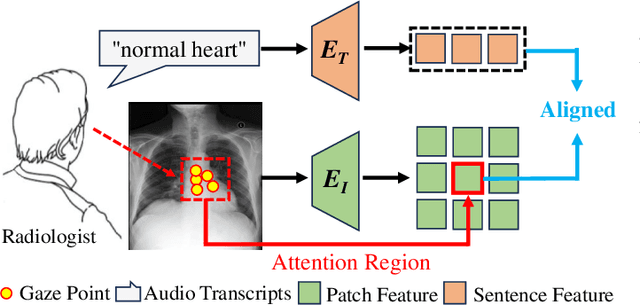
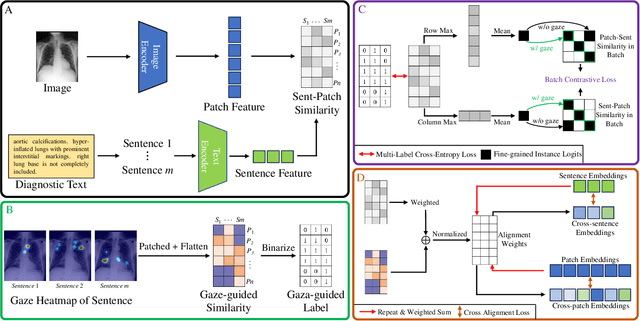
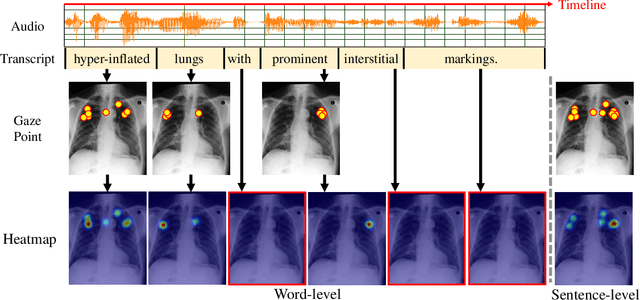
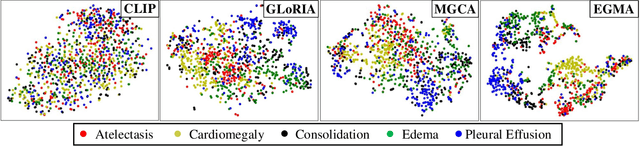
In multi-modal frameworks, the alignment of cross-modal features presents a significant challenge. The predominant approach in multi-modal pre-training emphasizes either global or local alignment between modalities, utilizing extensive datasets. This bottom-up driven method often suffers from a lack of interpretability, a critical concern in radiology. Previous studies have integrated high-level labels in medical images or text, but these still rely on manual annotation, a costly and labor-intensive process. Our work introduces a novel approach by using eye-gaze data, collected synchronously by radiologists during diagnostic evaluations. This data, indicating radiologists' focus areas, naturally links chest X-rays to diagnostic texts. We propose the Eye-gaze Guided Multi-modal Alignment (EGMA) framework to harness eye-gaze data for better alignment of image and text features, aiming to reduce reliance on manual annotations and thus cut training costs. Our model demonstrates robust performance, outperforming other state-of-the-art methods in zero-shot classification and retrieval tasks. The incorporation of easily-obtained eye-gaze data during routine radiological diagnoses signifies a step towards minimizing manual annotation dependency. Additionally, we explore the impact of varying amounts of eye-gaze data on model performance, highlighting the feasibility and utility of integrating this auxiliary data into multi-modal pre-training.
Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
Mar 19, 2024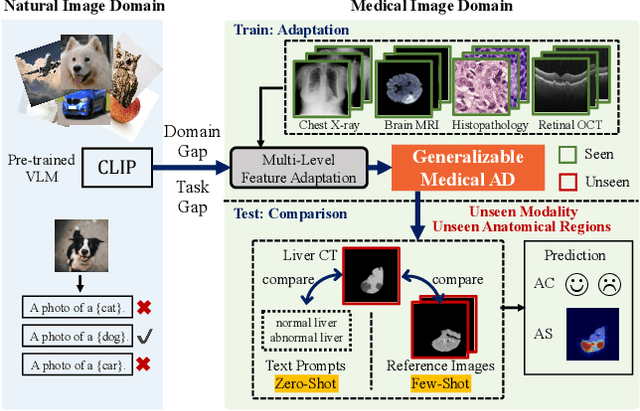
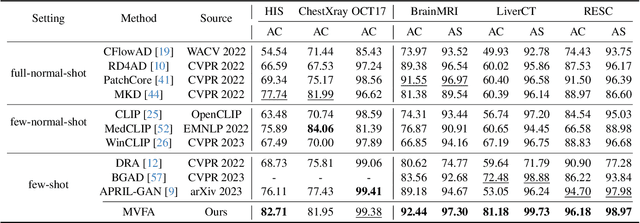
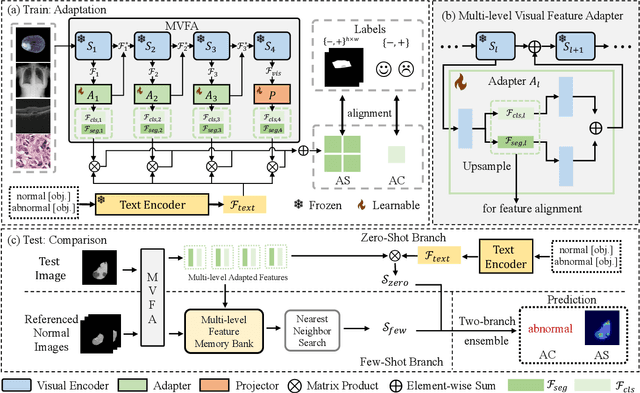
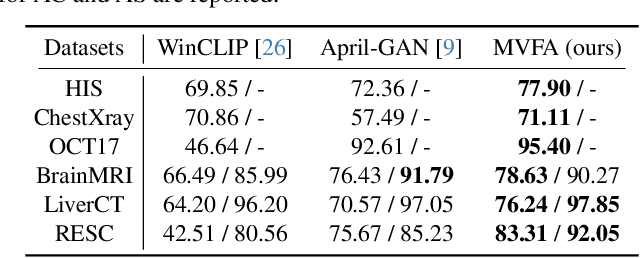
Recent advancements in large-scale visual-language pre-trained models have led to significant progress in zero-/few-shot anomaly detection within natural image domains. However, the substantial domain divergence between natural and medical images limits the effectiveness of these methodologies in medical anomaly detection. This paper introduces a novel lightweight multi-level adaptation and comparison framework to repurpose the CLIP model for medical anomaly detection. Our approach integrates multiple residual adapters into the pre-trained visual encoder, enabling a stepwise enhancement of visual features across different levels. This multi-level adaptation is guided by multi-level, pixel-wise visual-language feature alignment loss functions, which recalibrate the model's focus from object semantics in natural imagery to anomaly identification in medical images. The adapted features exhibit improved generalization across various medical data types, even in zero-shot scenarios where the model encounters unseen medical modalities and anatomical regions during training. Our experiments on medical anomaly detection benchmarks demonstrate that our method significantly surpasses current state-of-the-art models, with an average AUC improvement of 6.24% and 7.33% for anomaly classification, 2.03% and 2.37% for anomaly segmentation, under the zero-shot and few-shot settings, respectively. Source code is available at: https://github.com/MediaBrain-SJTU/MVFA-AD
Semantics, Distortion, and Style Matter: Towards Source-free UDA for Panoramic Segmentation
Mar 19, 2024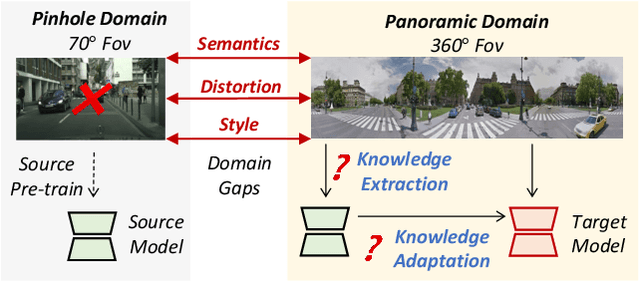
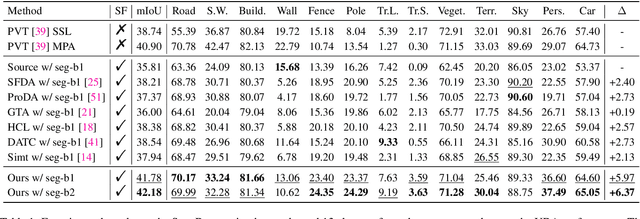
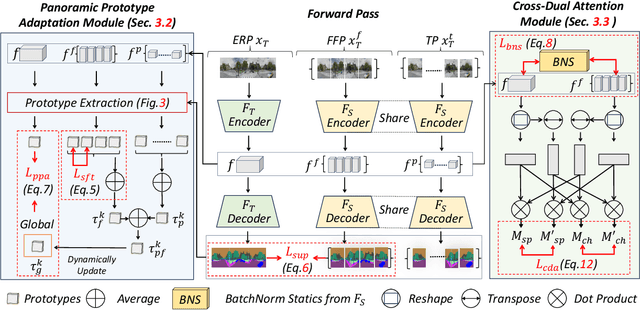
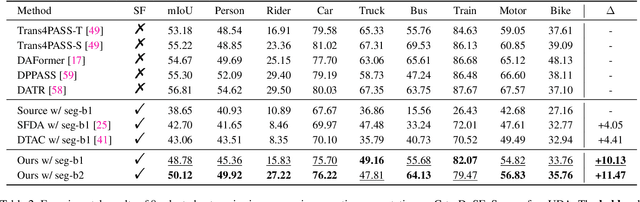
This paper addresses an interesting yet challenging problem -- source-free unsupervised domain adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation -- given only a pinhole image-trained model (i.e., source) and unlabeled panoramic images (i.e., target). Tackling this problem is nontrivial due to the semantic mismatches, style discrepancies, and inevitable distortion of panoramic images. To this end, we propose a novel method that utilizes Tangent Projection (TP) as it has less distortion and meanwhile slits the equirectangular projection (ERP) with a fixed FoV to mimic the pinhole images. Both projections are shown effective in extracting knowledge from the source model. However, the distinct projection discrepancies between source and target domains impede the direct knowledge transfer; thus, we propose a panoramic prototype adaptation module (PPAM) to integrate panoramic prototypes from the extracted knowledge for adaptation. We then impose the loss constraints on both predictions and prototypes and propose a cross-dual attention module (CDAM) at the feature level to better align the spatial and channel characteristics across the domains and projections. Both knowledge extraction and transfer processes are synchronously updated to reach the best performance. Extensive experiments on the synthetic and real-world benchmarks, including outdoor and indoor scenarios, demonstrate that our method achieves significantly better performance than prior SFUDA methods for pinhole-to-panoramic adaptation.
SC-Diff: 3D Shape Completion with Latent Diffusion Models
Mar 19, 2024
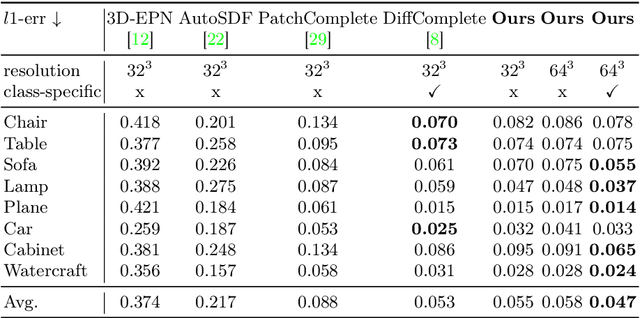
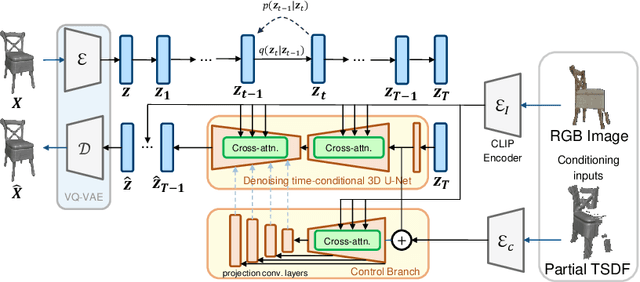
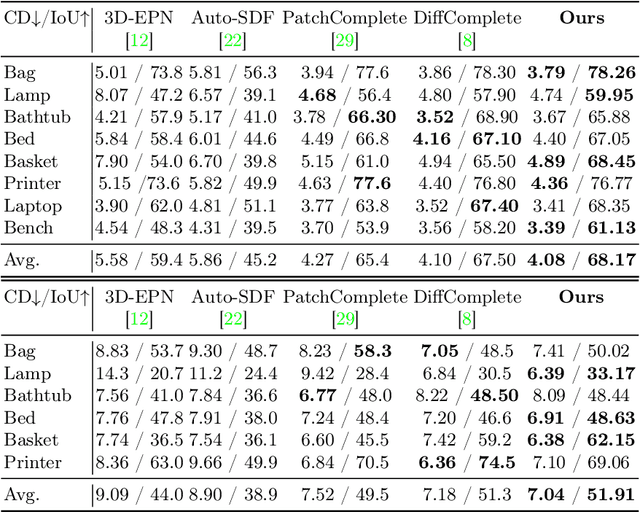
This paper introduces a 3D shape completion approach using a 3D latent diffusion model optimized for completing shapes, represented as Truncated Signed Distance Functions (TSDFs), from partial 3D scans. Our method combines image-based conditioning through cross-attention and spatial conditioning through the integration of 3D features from captured partial scans. This dual guidance enables high-fidelity, realistic shape completions at superior resolutions. At the core of our approach is the compression of 3D data into a low-dimensional latent space using an auto-encoder inspired by 2D latent diffusion models. This compression facilitates the processing of higher-resolution shapes and allows us to apply our model across multiple object classes, a significant improvement over other existing diffusion-based shape completion methods, which often require a separate diffusion model for each class. We validated our approach against two common benchmarks in the field of shape completion, demonstrating competitive performance in terms of accuracy and realism and performing on par with state-of-the-art methods despite operating at a higher resolution with a single model for all object classes. We present a comprehensive evaluation of our model, showcasing its efficacy in handling diverse shape completion challenges, even on unseen object classes. The code will be released upon acceptance.
CarbonNet: How Computer Vision Plays a Role in Climate Change? Application: Learning Geomechanics from Subsurface Geometry of CCS to Mitigate Global Warming
Mar 19, 2024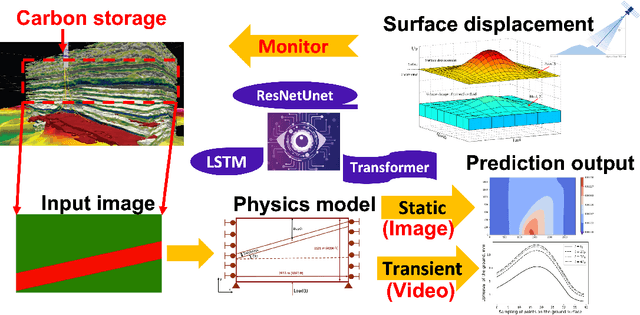

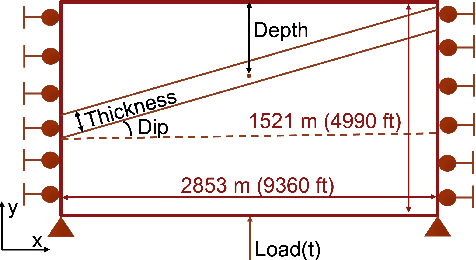
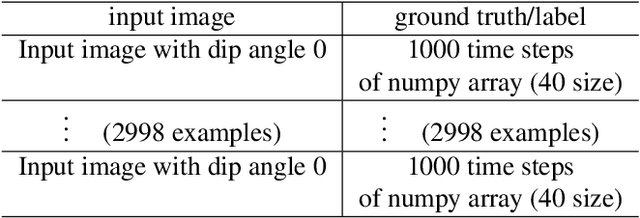
We introduce a new approach using computer vision to predict the land surface displacement from subsurface geometry images for Carbon Capture and Sequestration (CCS). CCS has been proved to be a key component for a carbon neutral society. However, scientists see there are challenges along the way including the high computational cost due to the large model scale and limitations to generalize a pre-trained model with complex physics. We tackle those challenges by training models directly from the subsurface geometry images. The goal is to understand the respons of land surface displacement due to carbon injection and utilize our trained models to inform decision making in CCS projects. We implement multiple models (CNN, ResNet, and ResNetUNet) for static mechanics problem, which is a image prediction problem. Next, we use the LSTM and transformer for transient mechanics scenario, which is a video prediction problem. It shows ResNetUNet outperforms the others thanks to its architecture in static mechanics problem, and LSTM shows comparable performance to transformer in transient problem. This report proceeds by outlining our dataset in detail followed by model descriptions in method section. Result and discussion state the key learning, observations, and conclusion with future work rounds out the paper.
Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
Mar 19, 2024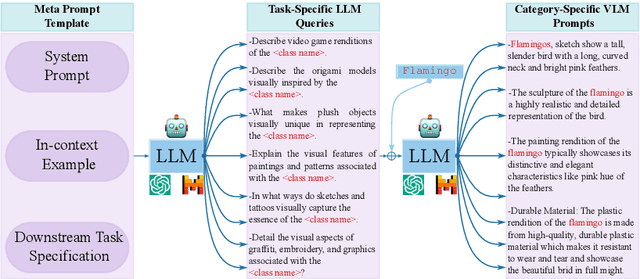
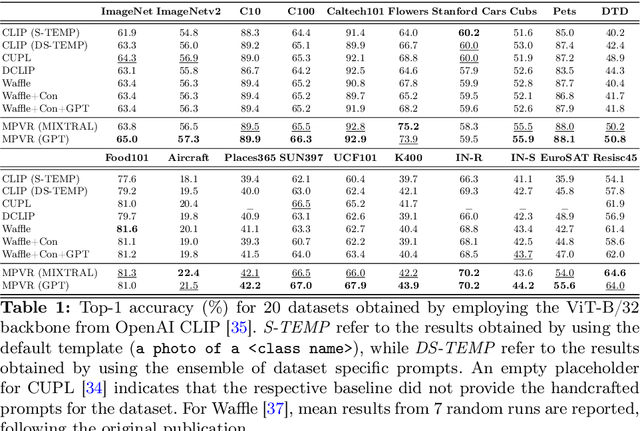
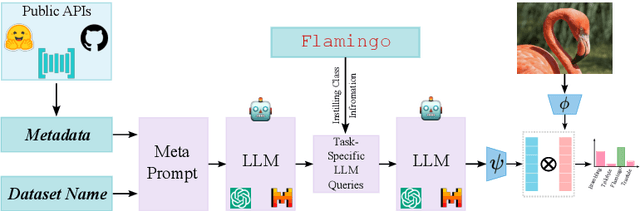
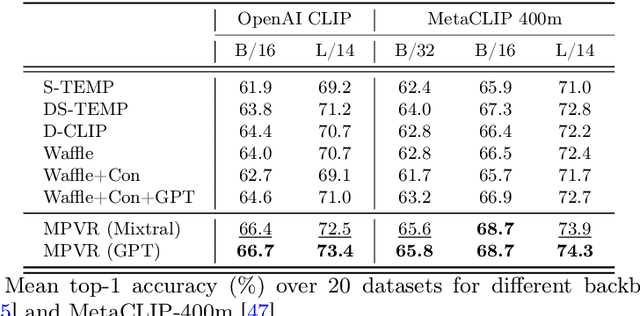
Prompt ensembling of Large Language Model (LLM) generated category-specific prompts has emerged as an effective method to enhance zero-shot recognition ability of Vision-Language Models (VLMs). To obtain these category-specific prompts, the present methods rely on hand-crafting the prompts to the LLMs for generating VLM prompts for the downstream tasks. However, this requires manually composing these task-specific prompts and still, they might not cover the diverse set of visual concepts and task-specific styles associated with the categories of interest. To effectively take humans out of the loop and completely automate the prompt generation process for zero-shot recognition, we propose Meta-Prompting for Visual Recognition (MPVR). Taking as input only minimal information about the target task, in the form of its short natural language description, and a list of associated class labels, MPVR automatically produces a diverse set of category-specific prompts resulting in a strong zero-shot classifier. MPVR generalizes effectively across various popular zero-shot image recognition benchmarks belonging to widely different domains when tested with multiple LLMs and VLMs. For example, MPVR obtains a zero-shot recognition improvement over CLIP by up to 19.8% and 18.2% (5.0% and 4.5% on average over 20 datasets) leveraging GPT and Mixtral LLMs, respectively
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Mar 18, 2024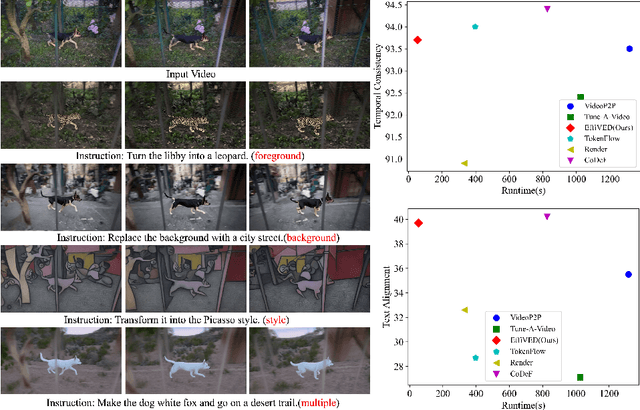
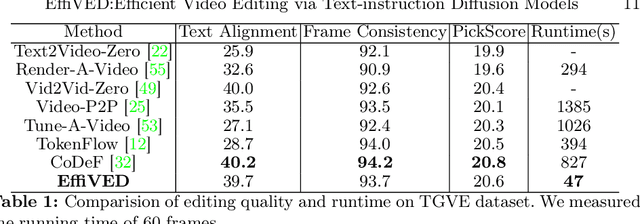
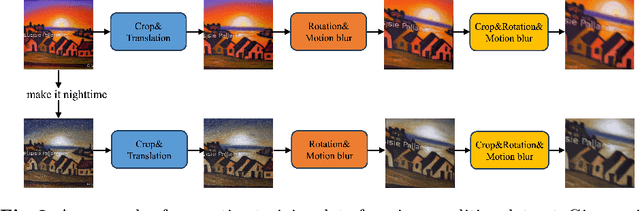
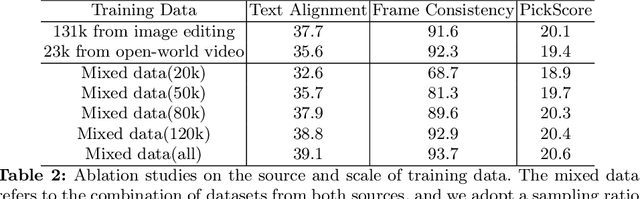
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. The datasets will be made publicly available upon publication.