 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Medical Image Fusion Method based on MDLatLRRv2
Jul 02, 2022
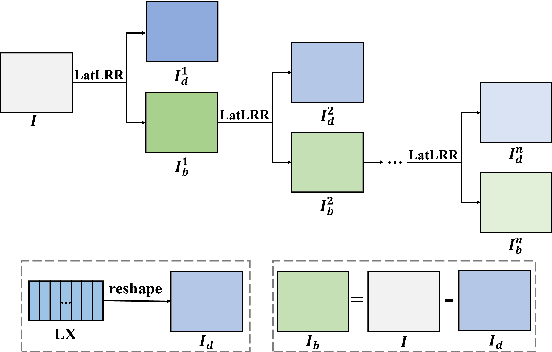
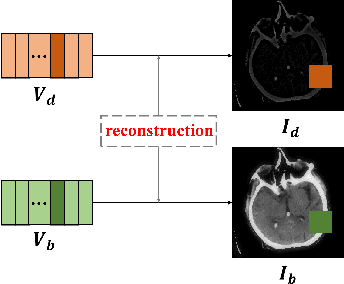
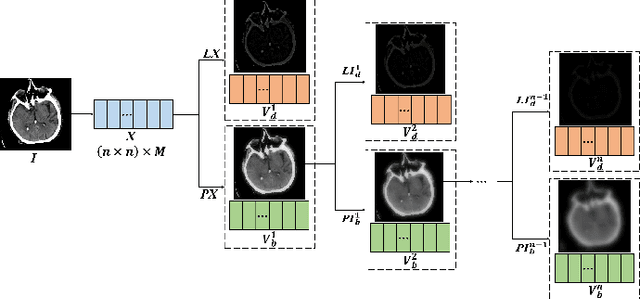
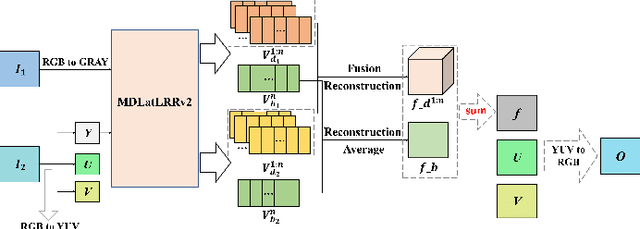
Since MDLatLRR only considers detailed parts (salient features) of input images extracted by latent low-rank representation (LatLRR), it doesn't use base parts (principal features) extracted by LatLRR effectively. Therefore, we proposed an improved multi-level decomposition method called MDLatLRRv2 which effectively analyzes and utilizes all the image features obtained by LatLRR. Then we apply MDLatLRRv2 to medical image fusion. The base parts are fused by average strategy and the detail parts are fused by nuclear-norm operation. The comparison with the existing methods demonstrates that the proposed method can achieve state-of-the-art fusion performance in objective and subjective assessment.
Unsupervised Linear and Iterative Combinations of Patches for Image Denoising
Dec 01, 2022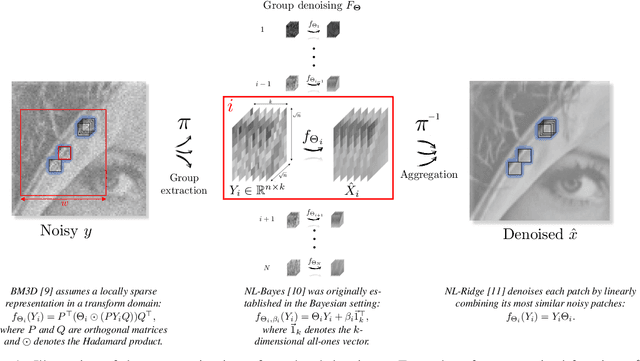
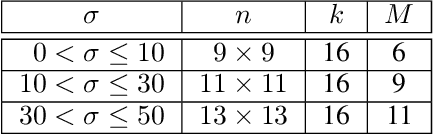
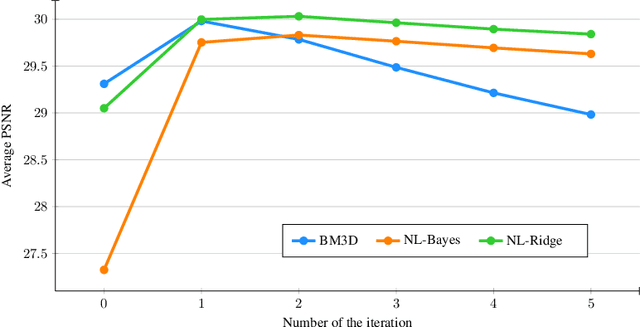
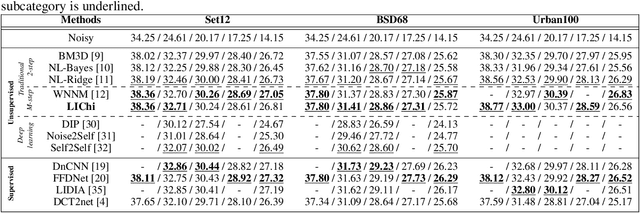
We introduce a parametric view of non-local two-step denoisers, for which BM3D is a major representative, where quadratic risk minimization is leveraged for unsupervised optimization. Within this paradigm, we propose to extend the underlying mathematical parametric formulation by iteration. This generalization can be expected to further improve the denoising performance, somehow curbed by the impracticality of repeating the second stage for all two-step denoisers. The resulting formulation involves estimating an even larger amount of parameters in a unsupervised manner which is all the more challenging. Focusing on the parameterized form of NL-Ridge, the simplest but also most efficient non-local two-step denoiser, we propose a progressive scheme to approximate the parameters minimizing the risk. In the end, the denoised images are made up of iterative linear combinations of patches. Experiments on artificially noisy images but also on real-world noisy images demonstrate that our method compares favorably with the very best unsupervised denoisers such as WNNM, outperforming the recent deep-learning-based approaches, while being much faster.
CLIP2Point: Transfer CLIP to Point Cloud Classification with Image-Depth Pre-training
Oct 03, 2022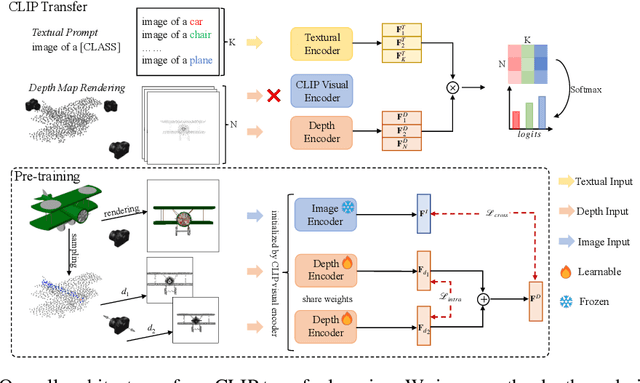

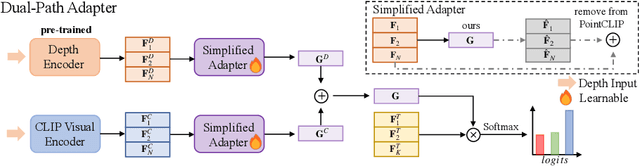

Pre-training across 3D vision and language remains under development because of limited training data. Recent works attempt to transfer vision-language pre-training models to 3D vision. PointCLIP converts point cloud data to multi-view depth maps, adopting CLIP for shape classification. However, its performance is restricted by the domain gap between rendered depth maps and images, as well as the diversity of depth distributions. To address this issue, we propose CLIP2Point, an image-depth pre-training method by contrastive learning to transfer CLIP to the 3D domain, and adapt it to point cloud classification. We introduce a new depth rendering setting that forms a better visual effect, and then render 52,460 pairs of images and depth maps from ShapeNet for pre-training. The pre-training scheme of CLIP2Point combines cross-modality learning to enforce the depth features for capturing expressive visual and textual features and intra-modality learning to enhance the invariance of depth aggregation. Additionally, we propose a novel Dual-Path Adapter (DPA) module, i.e., a dual-path structure with simplified adapters for few-shot learning. The dual-path structure allows the joint use of CLIP and CLIP2Point, and the simplified adapter can well fit few-shot tasks without post-search. Experimental results show that CLIP2Point is effective in transferring CLIP knowledge to 3D vision. Our CLIP2Point outperforms PointCLIP and other self-supervised 3D networks, achieving state-of-the-art results on zero-shot and few-shot classification.
Fine-Grained Entity Segmentation
Nov 12, 2022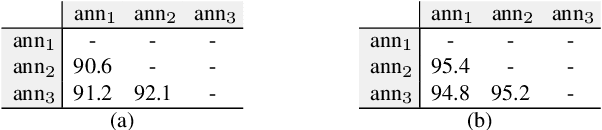
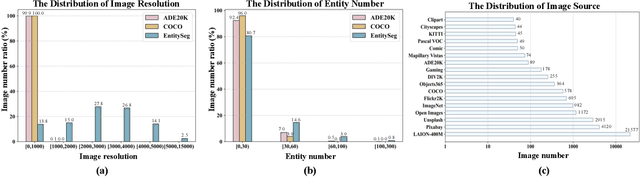

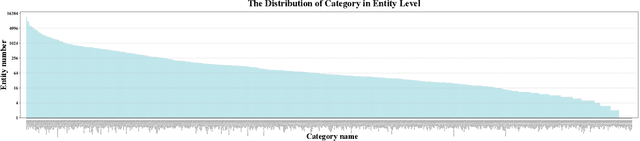
In dense image segmentation tasks (e.g., semantic, panoptic), existing methods can hardly generalize well to unseen image domains, predefined classes, and image resolution & quality variations. Motivated by these observations, we construct a large-scale entity segmentation dataset to explore fine-grained entity segmentation, with a strong focus on open-world and high-quality dense segmentation. The dataset contains images spanning diverse image domains and resolutions, along with high-quality mask annotations for training and testing. Given the high-quality and -resolution nature of the dataset, we propose CropFormer for high-quality segmentation, which can improve mask prediction using high-res image crops that provide more fine-grained image details than the full image. CropFormer is the first query-based Transformer architecture that can effectively ensemble mask predictions from multiple image crops, by learning queries that can associate the same entities across the full image and its crop. With CropFormer, we achieve a significant AP gain of $1.9$ on the challenging fine-grained entity segmentation task. The dataset and code will be released at http://luqi.info/entityv2.github.io/.
InstaFormer: Instance-Aware Image-to-Image Translation with Transformer
Mar 30, 2022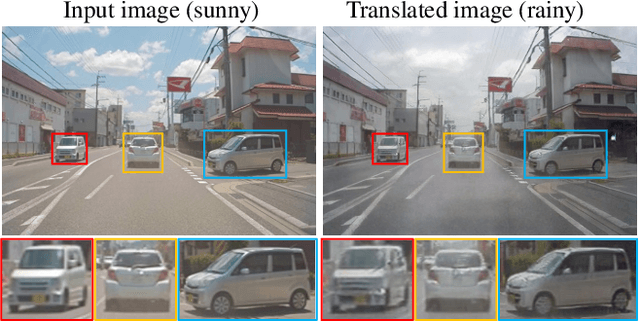

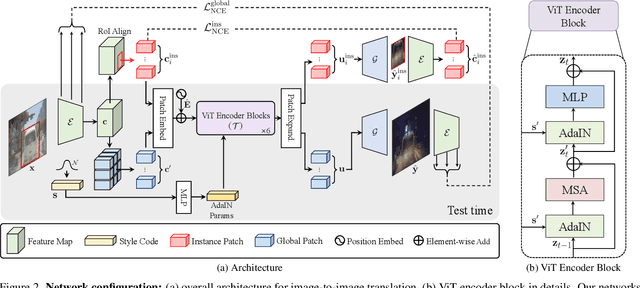
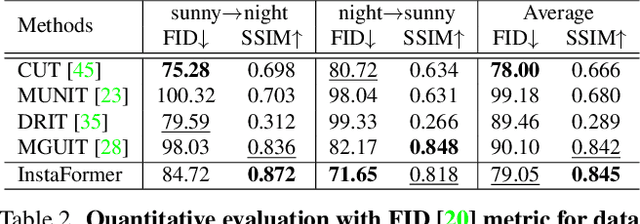
We present a novel Transformer-based network architecture for instance-aware image-to-image translation, dubbed InstaFormer, to effectively integrate global- and instance-level information. By considering extracted content features from an image as tokens, our networks discover global consensus of content features by considering context information through a self-attention module in Transformers. By augmenting such tokens with an instance-level feature extracted from the content feature with respect to bounding box information, our framework is capable of learning an interaction between object instances and the global image, thus boosting the instance-awareness. We replace layer normalization (LayerNorm) in standard Transformers with adaptive instance normalization (AdaIN) to enable a multi-modal translation with style codes. In addition, to improve the instance-awareness and translation quality at object regions, we present an instance-level content contrastive loss defined between input and translated image. We conduct experiments to demonstrate the effectiveness of our InstaFormer over the latest methods and provide extensive ablation studies.
GPTR: Gestalt-Perception Transformer for Diagram Object Detection
Dec 29, 2022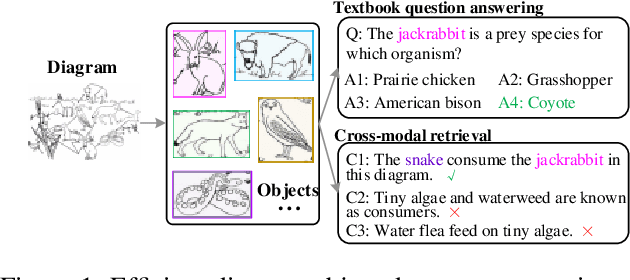
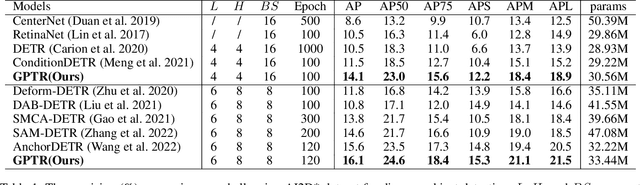
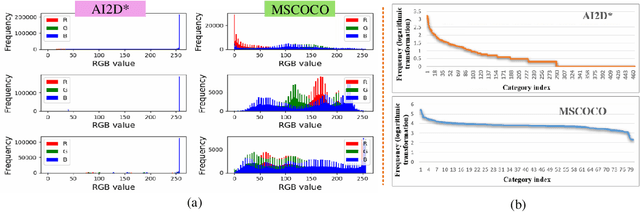
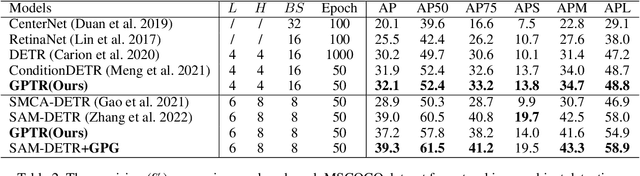
Diagram object detection is the key basis of practical applications such as textbook question answering. Because the diagram mainly consists of simple lines and color blocks, its visual features are sparser than those of natural images. In addition, diagrams usually express diverse knowledge, in which there are many low-frequency object categories in diagrams. These lead to the fact that traditional data-driven detection model is not suitable for diagrams. In this work, we propose a gestalt-perception transformer model for diagram object detection, which is based on an encoder-decoder architecture. Gestalt perception contains a series of laws to explain human perception, that the human visual system tends to perceive patches in an image that are similar, close or connected without abrupt directional changes as a perceptual whole object. Inspired by these thoughts, we build a gestalt-perception graph in transformer encoder, which is composed of diagram patches as nodes and the relationships between patches as edges. This graph aims to group these patches into objects via laws of similarity, proximity, and smoothness implied in these edges, so that the meaningful objects can be effectively detected. The experimental results demonstrate that the proposed GPTR achieves the best results in the diagram object detection task. Our model also obtains comparable results over the competitors in natural image object detection.
Extracting Semantic Knowledge from GANs with Unsupervised Learning
Nov 30, 2022


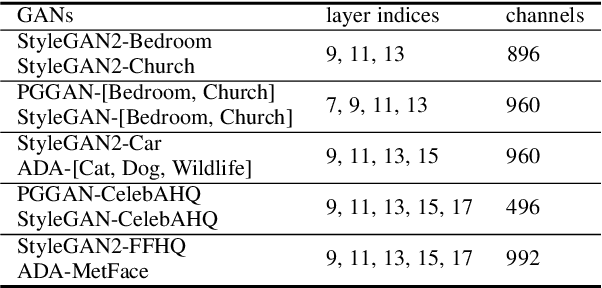
Recently, unsupervised learning has made impressive progress on various tasks. Despite the dominance of discriminative models, increasing attention is drawn to representations learned by generative models and in particular, Generative Adversarial Networks (GANs). Previous works on the interpretation of GANs reveal that GANs encode semantics in feature maps in a linearly separable form. In this work, we further find that GAN's features can be well clustered with the linear separability assumption. We propose a novel clustering algorithm, named KLiSH, which leverages the linear separability to cluster GAN's features. KLiSH succeeds in extracting fine-grained semantics of GANs trained on datasets of various objects, e.g., car, portrait, animals, and so on. With KLiSH, we can sample images from GANs along with their segmentation masks and synthesize paired image-segmentation datasets. Using the synthesized datasets, we enable two downstream applications. First, we train semantic segmentation networks on these datasets and test them on real images, realizing unsupervised semantic segmentation. Second, we train image-to-image translation networks on the synthesized datasets, enabling semantic-conditional image synthesis without human annotations.
On the Effects of Image Quality Degradation on Minutiae- and Ridge-Based Automatic Fingerprint Recognition
Jul 12, 2022

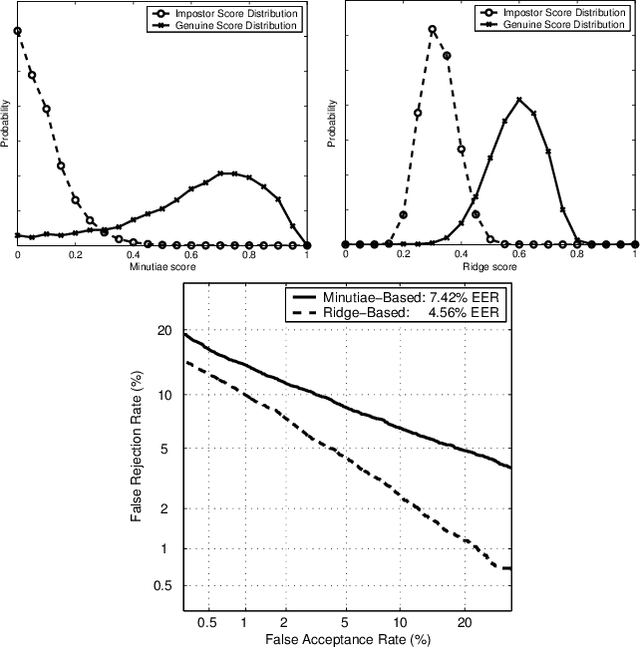

The effect of image quality degradation on the verification performance of automatic fingerprint recognition is investigated. We study the performance of two fingerprint matchers based on minutiae and ridge information under varying fingerprint image quality. The ridge-based system is found to be more robust to image quality degradation than the minutiae-based system for a number of different image quality criteria.
Rank-Enhanced Low-Dimensional Convolution Set for Hyperspectral Image Denoising
Jul 09, 2022
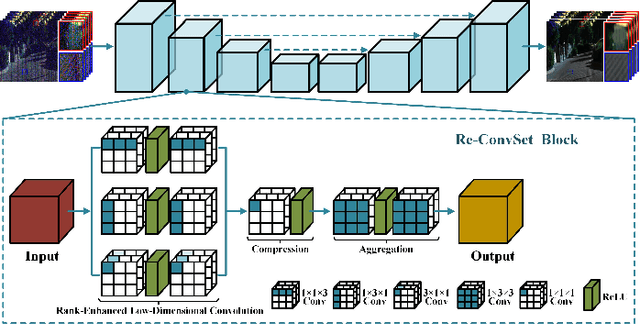
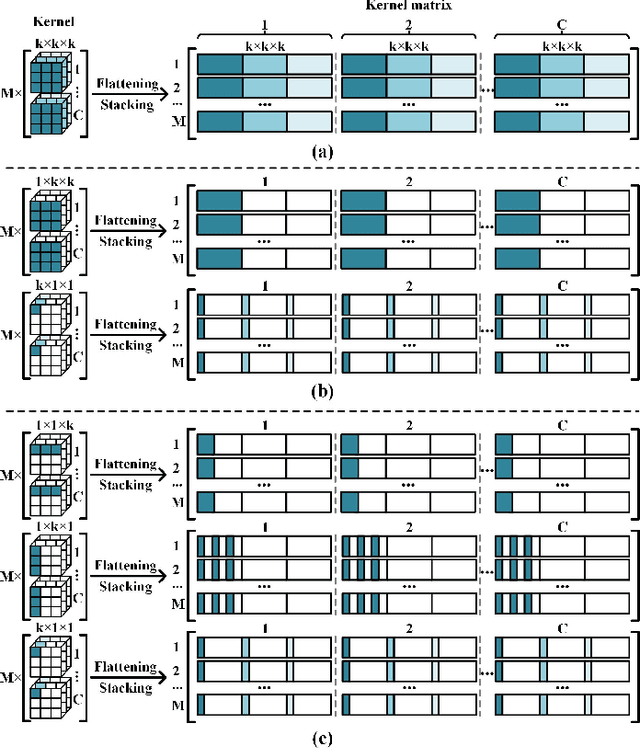
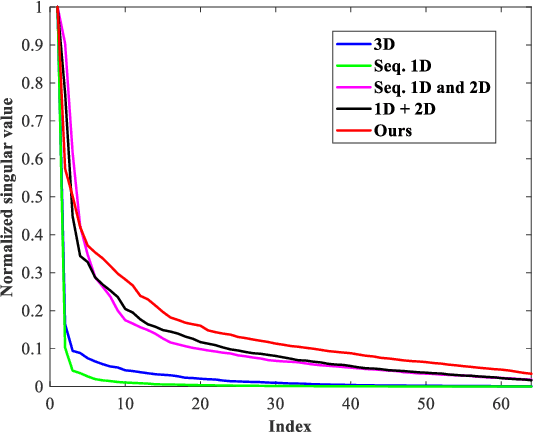
This paper tackles the challenging problem of hyperspectral (HS) image denoising. Unlike existing deep learning-based methods usually adopting complicated network architectures or empirically stacking off-the-shelf modules to pursue performance improvement, we focus on the efficient and effective feature extraction manner for capturing the high-dimensional characteristics of HS images. To be specific, based on the theoretical analysis that increasing the rank of the matrix formed by the unfolded convolutional kernels can promote feature diversity, we propose rank-enhanced low-dimensional convolution set (Re-ConvSet), which separately performs 1-D convolution along the three dimensions of an HS image side-by-side, and then aggregates the resulting spatial-spectral embeddings via a learnable compression layer. Re-ConvSet not only learns the diverse spatial-spectral features of HS images, but also reduces the parameters and complexity of the network. We then incorporate Re-ConvSet into the widely-used U-Net architecture to construct an HS image denoising method. Surprisingly, we observe such a concise framework outperforms the most recent method to a large extent in terms of quantitative metrics, visual results, and efficiency. We believe our work may shed light on deep learning-based HS image processing and analysis.
Gaussian Blur and Relative Edge Response
Jan 02, 2023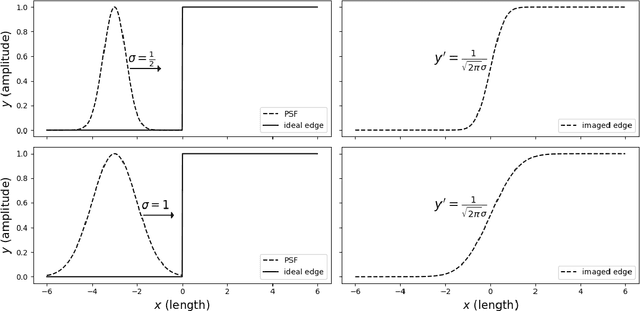


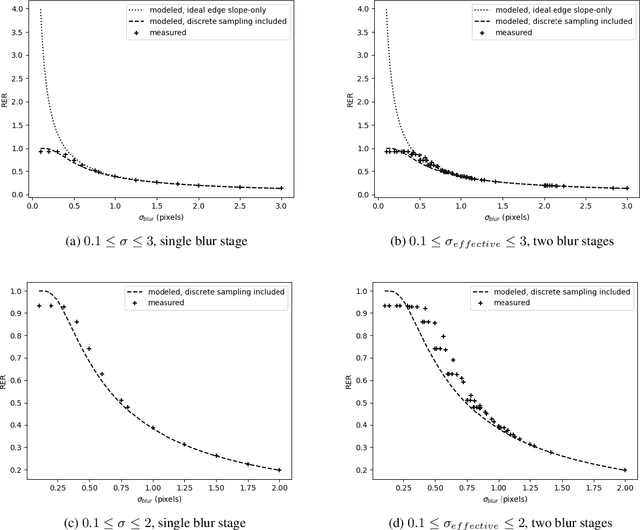
It is often convenient to use Gaussian blur in studying image quality or in data augmentation pipelines for training convoluional neural networks. Because of their convenience, Guassians are sometimes used as first order approximations of optical point spread functions. Here, we derive and evaluate closed form relationships between Gaussian blur parameters and relative edge response, finding good agreement with measured results. Additionally, we evaluate the extent to which Gaussian approximations of optical point spread functions can be used to predict relative edge response, finding that Gaussian relationships provide a reasonable approximation in limited circumstances but not across a wide range of optical parameters.