 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Multi-View Hallucination in Large Vision-Language Models
Mar 25, 2026Large vision-language models (LVLMs) are increasingly being applied to multi-view image inputs captured from diverse viewpoints. However, despite this growing use, current LVLMs often confuse or mismatch visual information originating from different instances or viewpoints, a phenomenon we term multi-view hallucination. To systematically analyze this problem, we construct MVH-Bench, a benchmark comprising 4.8k question-answer pairs targeting two types of hallucination: cross-instance and cross-view. Empirical results show that recent LVLMs struggle to correctly associate visual evidence with its corresponding instance or viewpoint. To overcome this limitation, we propose Reference Shift Contrastive Decoding (RSCD), a training-free decoding technique that suppresses visual interference by generating negative logits through attention masking. Experiments on MVH-Bench with Qwen2.5-VL and LLaVA-OneVision demonstrate that RSCD consistently improves performance by up to 21.1 and 34.6 points over existing hallucination mitigation methods, highlighting the effectiveness of our approach.
Subtractive Training for Music Stem Insertion using Latent Diffusion Models
Jun 27, 2024We present Subtractive Training, a simple and novel method for synthesizing individual musical instrument stems given other instruments as context. This method pairs a dataset of complete music mixes with 1) a variant of the dataset lacking a specific stem, and 2) LLM-generated instructions describing how the missing stem should be reintroduced. We then fine-tune a pretrained text-to-audio diffusion model to generate the missing instrument stem, guided by both the existing stems and the text instruction. Our results demonstrate Subtractive Training's efficacy in creating authentic drum stems that seamlessly blend with the existing tracks. We also show that we can use the text instruction to control the generation of the inserted stem in terms of rhythm, dynamics, and genre, allowing us to modify the style of a single instrument in a full song while keeping the remaining instruments the same. Lastly, we extend this technique to MIDI formats, successfully generating compatible bass, drum, and guitar parts for incomplete arrangements.
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
May 07, 2024



We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Panoramic Image-to-Image Translation
Apr 11, 2023



In this paper, we tackle the challenging task of Panoramic Image-to-Image translation (Pano-I2I) for the first time. This task is difficult due to the geometric distortion of panoramic images and the lack of a panoramic image dataset with diverse conditions, like weather or time. To address these challenges, we propose a panoramic distortion-aware I2I model that preserves the structure of the panoramic images while consistently translating their global style referenced from a pinhole image. To mitigate the distortion issue in naive 360 panorama translation, we adopt spherical positional embedding to our transformer encoders, introduce a distortion-free discriminator, and apply sphere-based rotation for augmentation and its ensemble. We also design a content encoder and a style encoder to be deformation-aware to deal with a large domain gap between panoramas and pinhole images, enabling us to work on diverse conditions of pinhole images. In addition, considering the large discrepancy between panoramas and pinhole images, our framework decouples the learning procedure of the panoramic reconstruction stage from the translation stage. We show distinct improvements over existing I2I models in translating the StreetLearn dataset in the daytime into diverse conditions. The code will be publicly available online for our community.
Robust Camera Pose Refinement for Multi-Resolution Hash Encoding
Feb 03, 2023



Multi-resolution hash encoding has recently been proposed to reduce the computational cost of neural renderings, such as NeRF. This method requires accurate camera poses for the neural renderings of given scenes. However, contrary to previous methods jointly optimizing camera poses and 3D scenes, the naive gradient-based camera pose refinement method using multi-resolution hash encoding severely deteriorates performance. We propose a joint optimization algorithm to calibrate the camera pose and learn a geometric representation using efficient multi-resolution hash encoding. Showing that the oscillating gradient flows of hash encoding interfere with the registration of camera poses, our method addresses the issue by utilizing smooth interpolation weighting to stabilize the gradient oscillation for the ray samplings across hash grids. Moreover, the curriculum training procedure helps to learn the level-wise hash encoding, further increasing the pose refinement. Experiments on the novel-view synthesis datasets validate that our learning frameworks achieve state-of-the-art performance and rapid convergence of neural rendering, even when initial camera poses are unknown.
LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
Aug 31, 2022
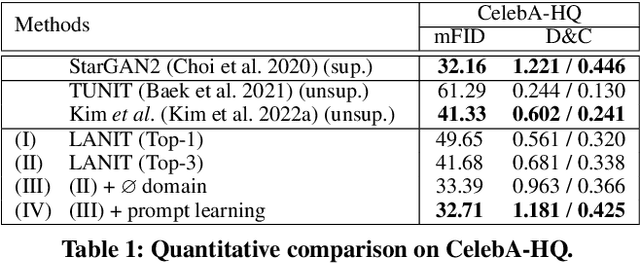
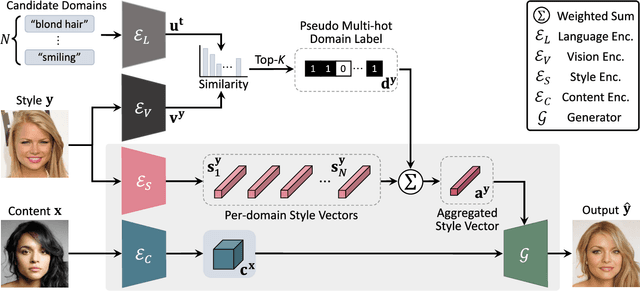
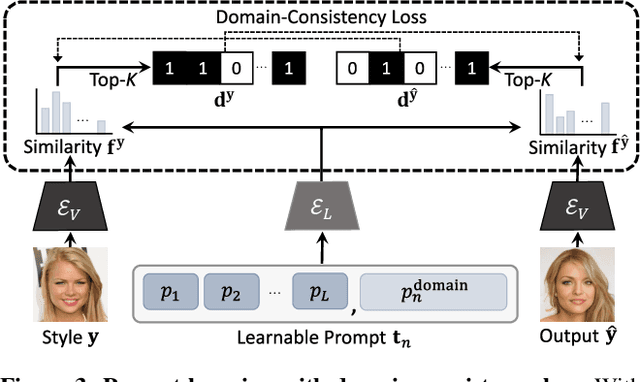
Existing techniques for image-to-image translation commonly have suffered from two critical problems: heavy reliance on per-sample domain annotation and/or inability of handling multiple attributes per image. Recent methods adopt clustering approaches to easily provide per-sample annotations in an unsupervised manner. However, they cannot account for the real-world setting; one sample may have multiple attributes. In addition, the semantics of the clusters are not easily coupled to human understanding. To overcome these, we present a LANguage-driven Image-to-image Translation model, dubbed LANIT. We leverage easy-to-obtain candidate domain annotations given in texts for a dataset and jointly optimize them during training. The target style is specified by aggregating multi-domain style vectors according to the multi-hot domain assignments. As the initial candidate domain texts might be inaccurate, we set the candidate domain texts to be learnable and jointly fine-tune them during training. Furthermore, we introduce a slack domain to cover samples that are not covered by the candidate domains. Experiments on several standard benchmarks demonstrate that LANIT achieves comparable or superior performance to the existing model.
InstaFormer: Instance-Aware Image-to-Image Translation with Transformer
Mar 30, 2022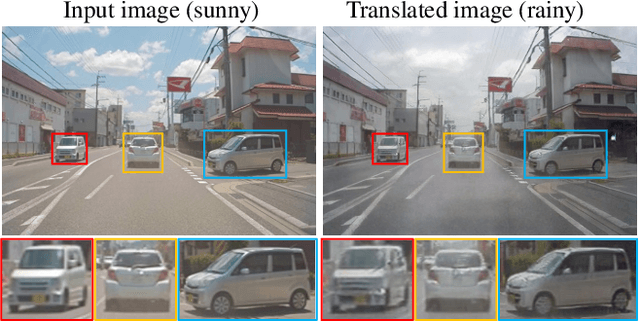

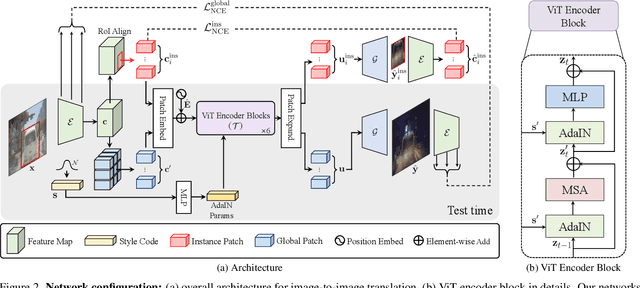
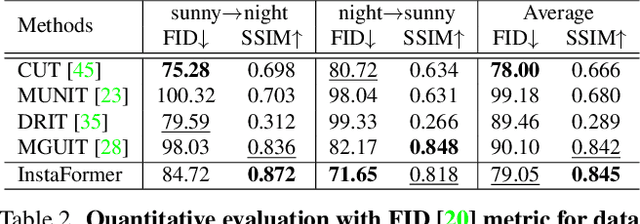
We present a novel Transformer-based network architecture for instance-aware image-to-image translation, dubbed InstaFormer, to effectively integrate global- and instance-level information. By considering extracted content features from an image as tokens, our networks discover global consensus of content features by considering context information through a self-attention module in Transformers. By augmenting such tokens with an instance-level feature extracted from the content feature with respect to bounding box information, our framework is capable of learning an interaction between object instances and the global image, thus boosting the instance-awareness. We replace layer normalization (LayerNorm) in standard Transformers with adaptive instance normalization (AdaIN) to enable a multi-modal translation with style codes. In addition, to improve the instance-awareness and translation quality at object regions, we present an instance-level content contrastive loss defined between input and translated image. We conduct experiments to demonstrate the effectiveness of our InstaFormer over the latest methods and provide extensive ablation studies.
Deep Translation Prior: Test-time Training for Photorealistic Style Transfer
Dec 12, 2021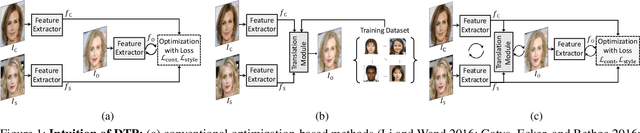
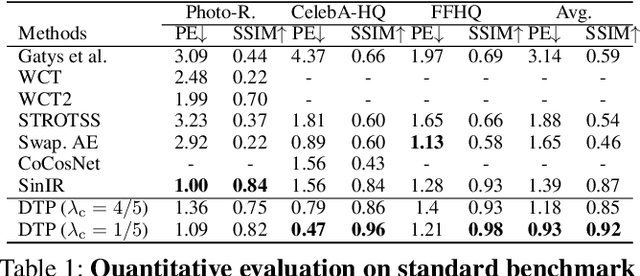
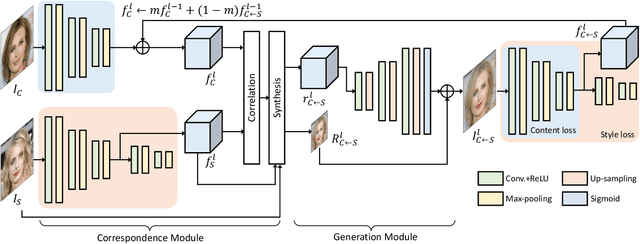
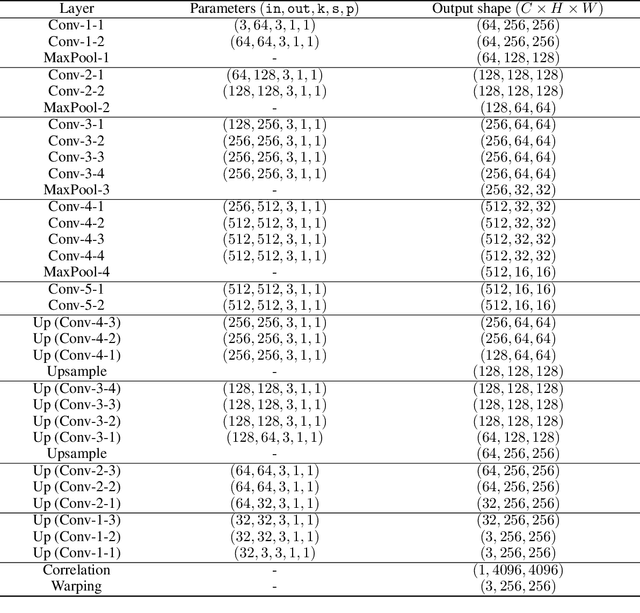
Recent techniques to solve photorealistic style transfer within deep convolutional neural networks (CNNs) generally require intensive training from large-scale datasets, thus having limited applicability and poor generalization ability to unseen images or styles. To overcome this, we propose a novel framework, dubbed Deep Translation Prior (DTP), to accomplish photorealistic style transfer through test-time training on given input image pair with untrained networks, which learns an image pair-specific translation prior and thus yields better performance and generalization. Tailored for such test-time training for style transfer, we present novel network architectures, with two sub-modules of correspondence and generation modules, and loss functions consisting of contrastive content, style, and cycle consistency losses. Our framework does not require offline training phase for style transfer, which has been one of the main challenges in existing methods, but the networks are to be solely learned during test-time. Experimental results prove that our framework has a better generalization ability to unseen image pairs and even outperforms the state-of-the-art methods.
Correlate-and-Excite: Real-Time Stereo Matching via Guided Cost Volume Excitation
Aug 12, 2021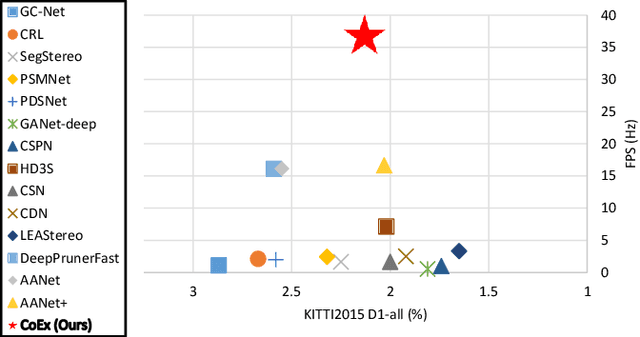
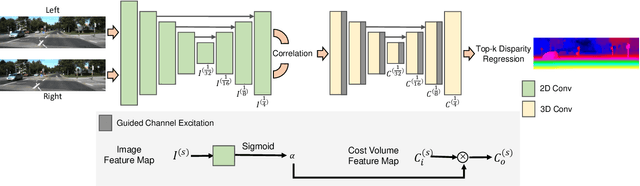

Volumetric deep learning approach towards stereo matching aggregates a cost volume computed from input left and right images using 3D convolutions. Recent works showed that utilization of extracted image features and a spatially varying cost volume aggregation complements 3D convolutions. However, existing methods with spatially varying operations are complex, cost considerable computation time, and cause memory consumption to increase. In this work, we construct Guided Cost volume Excitation (GCE) and show that simple channel excitation of cost volume guided by image can improve performance considerably. Moreover, we propose a novel method of using top-k selection prior to soft-argmin disparity regression for computing the final disparity estimate. Combining our novel contributions, we present an end-to-end network that we call Correlate-and-Excite (CoEx). Extensive experiments of our model on the SceneFlow, KITTI 2012, and KITTI 2015 datasets demonstrate the effectiveness and efficiency of our model and show that our model outperforms other speed-based algorithms while also being competitive to other state-of-the-art algorithms. Codes will be made available at https://github.com/antabangun/coex.
Online Exemplar Fine-Tuning for Image-to-Image Translation
Nov 18, 2020
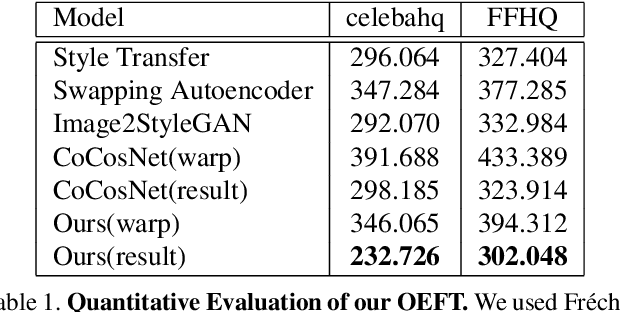
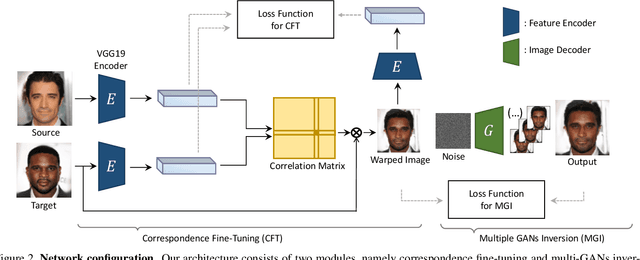
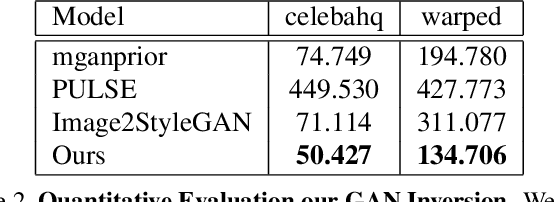
Existing techniques to solve exemplar-based image-to-image translation within deep convolutional neural networks (CNNs) generally require a training phase to optimize the network parameters on domain-specific and task-specific benchmarks, thus having limited applicability and generalization ability. In this paper, we propose a novel framework, for the first time, to solve exemplar-based translation through an online optimization given an input image pair, called online exemplar fine-tuning (OEFT), in which we fine-tune the off-the-shelf and general-purpose networks to the input image pair themselves. We design two sub-networks, namely correspondence fine-tuning and multiple GAN inversion, and optimize these network parameters and latent codes, starting from the pre-trained ones, with well-defined loss functions. Our framework does not require the off-line training phase, which has been the main challenge of existing methods, but the pre-trained networks to enable optimization in online. Experimental results prove that our framework is effective in having a generalization power to unseen image pairs and clearly even outperforms the state-of-the-arts needing the intensive training phase.