 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023
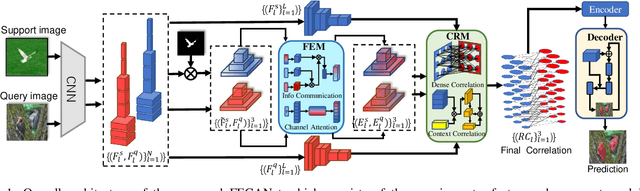
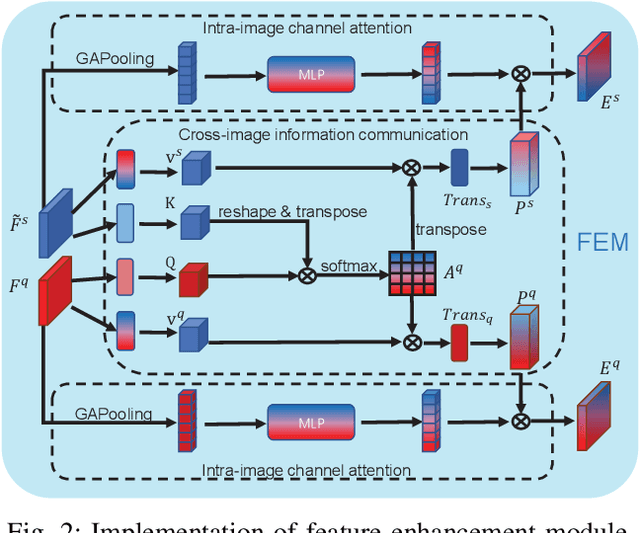
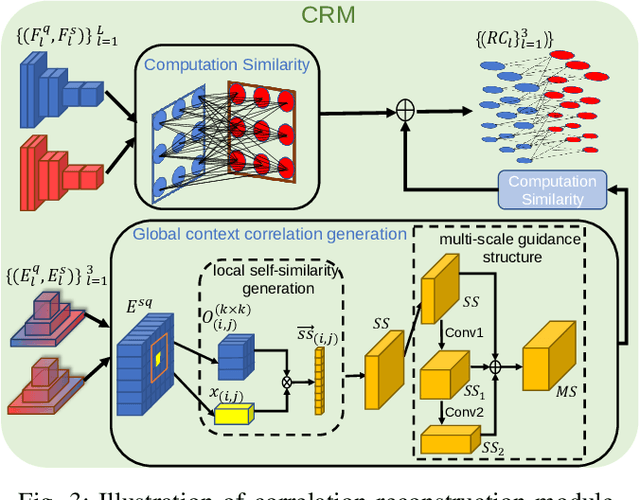

Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
On the Mathematics of Diffusion Models
Jan 25, 2023This paper attempts to present the stochastic differential equations of diffusion models in a manner that is accessible to a broad audience. The diffusion process is defined over a population density in R^d. Of particular interest is a population of images. In a diffusion model one first defines a diffusion process that takes a sample from the population and gradually adds noise until only noise remains. The fundamental idea is to sample from the population by a reverse-diffusion process mapping pure noise to a population sample. The diffusion process is defined independent of any ``interpretation'' but can be analyzed using the mathematics of variational auto-encoders (the ``VAE interpretation'') or the Fokker-Planck equation (the ``score-matching intgerpretation''). Both analyses yield reverse-diffusion methods involving the score function. The Fokker-Planck analysis yields a family of reverse-diffusion SDEs parameterized by any desired level of reverse-diffusion noise including zero (deterministic reverse-diffusion). The VAE analysis yields the reverse-diffusion SDE at the same noise level as the diffusion SDE. The VAE analysis also yields a useful expression for computing the population probabilities of a given point (image). This formula for the probability of a given point does not seem to follow naturally from the Fokker-Planck analysis. Much, but apparently not all, of the mathematics presented here can be found in the literature. Attributions are given at the end of the paper.
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023
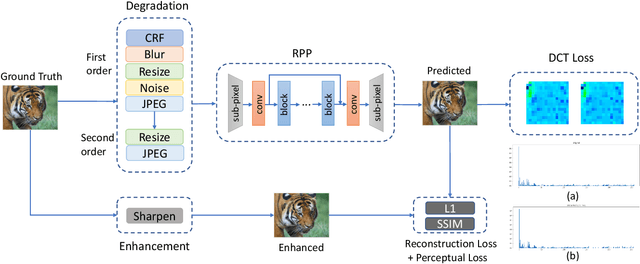

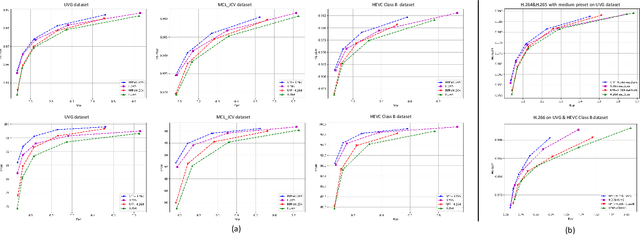
In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
M-GenSeg: Domain Adaptation For Target Modality Tumor Segmentation With Annotation-Efficient Supervision
Dec 14, 2022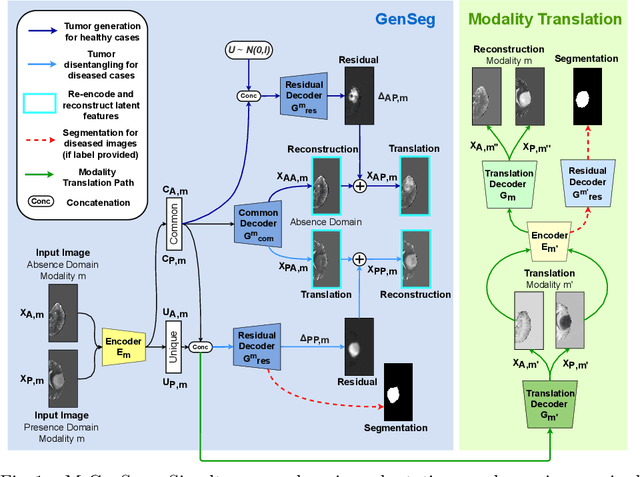
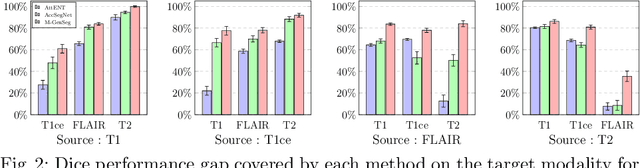
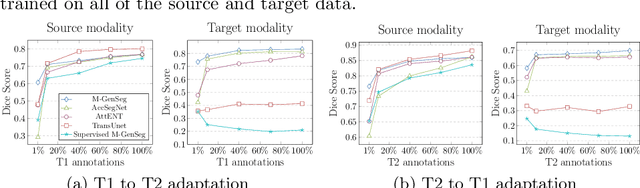
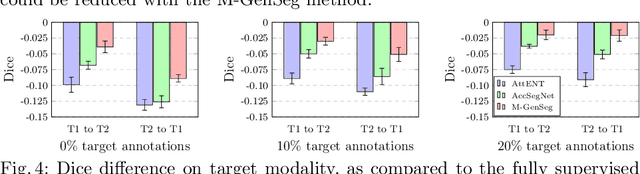
Automated medical image segmentation using deep neural networks typically requires substantial supervised training. However, these models fail to generalize well across different imaging modalities. This shortcoming, amplified by the limited availability of annotated data, has been hampering the deployment of such methods at a larger scale across modalities. To address these issues, we propose M-GenSeg, a new semi-supervised training strategy for accurate cross-modality tumor segmentation on unpaired bi-modal datasets. Based on image-level labels, a first unsupervised objective encourages the model to perform diseased to healthy translation by disentangling tumors from the background, which encompasses the segmentation task. Then, teaching the model to translate between image modalities enables the synthesis of target images from a source modality, thus leveraging the pixel-level annotations from the source modality to enforce generalization to the target modality images. We evaluated the performance on a brain tumor segmentation datasets composed of four different contrast sequences from the public BraTS 2020 challenge dataset. We report consistent improvement in Dice scores on both source and unannotated target modalities. On all twelve distinct domain adaptation experiments, the proposed model shows a clear improvement over state-of-the-art domain-adaptive baselines, with absolute Dice gains on the target modality reaching 0.15.
ExReg: Wide-range Photo Exposure Correction via a Multi-dimensional Regressor with Attention
Dec 14, 2022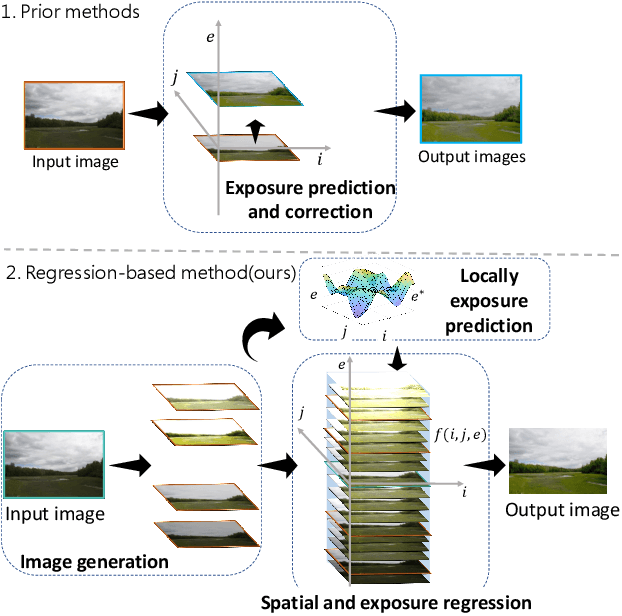
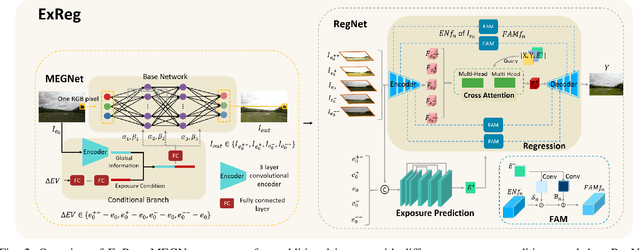
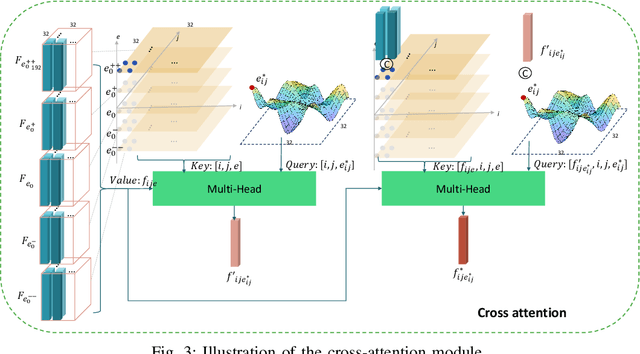

Photo exposure correction is widely investigated, but fewer studies focus on correcting under and over-exposed images simultaneously. Three issues remain open to handle and correct under and over-exposed images in a unified way. First, a locally-adaptive exposure adjustment may be more flexible instead of learning a global mapping. Second, it is an ill-posed problem to determine the suitable exposure values locally. Third, photos with the same content but different exposures may not reach consistent adjustment results. To this end, we proposed a novel exposure correction network, ExReg, to address the challenges by formulating exposure correction as a multi-dimensional regression process. Given an input image, a compact multi-exposure generation network is introduced to generate images with different exposure conditions for multi-dimensional regression and exposure correction in the next stage. An auxiliary module is designed to predict the region-wise exposure values, guiding the mainly proposed Encoder-Decoder ANP (Attentive Neural Processes) to regress the final corrected image. The experimental results show that ExReg can generate well-exposed results and outperform the SOTA method by 1.3dB in PSNR for extensive exposure problems. In addition, given the same image but under various exposure for testing, the corrected results are more visually consistent and physically accurate.
Cross Attention Based Style Distribution for Controllable Person Image Synthesis
Aug 01, 2022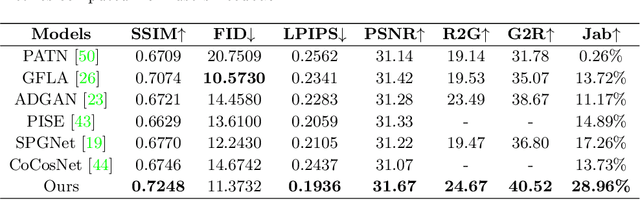
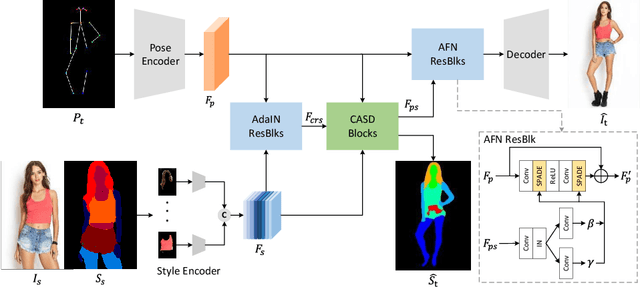
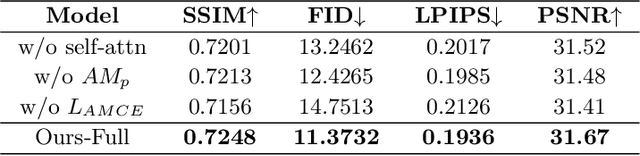
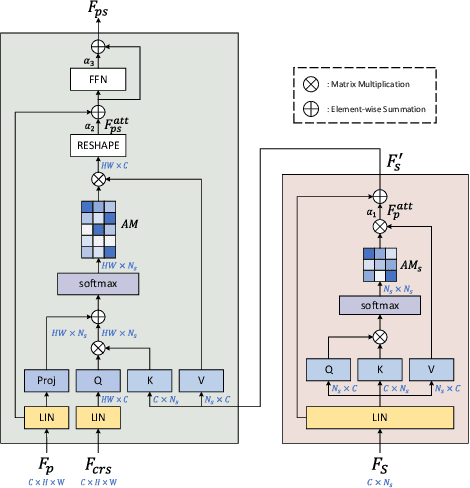
Controllable person image synthesis task enables a wide range of applications through explicit control over body pose and appearance. In this paper, we propose a cross attention based style distribution module that computes between the source semantic styles and target pose for pose transfer. The module intentionally selects the style represented by each semantic and distributes them according to the target pose. The attention matrix in cross attention expresses the dynamic similarities between the target pose and the source styles for all semantics. Therefore, it can be utilized to route the color and texture from the source image, and is further constrained by the target parsing map to achieve a clearer objective. At the same time, to encode the source appearance accurately, the self attention among different semantic styles is also added. The effectiveness of our model is validated quantitatively and qualitatively on pose transfer and virtual try-on tasks.
Distributed Parallel Image Signal Extrapolation Framework using Message Passing Interface
Jul 01, 2022
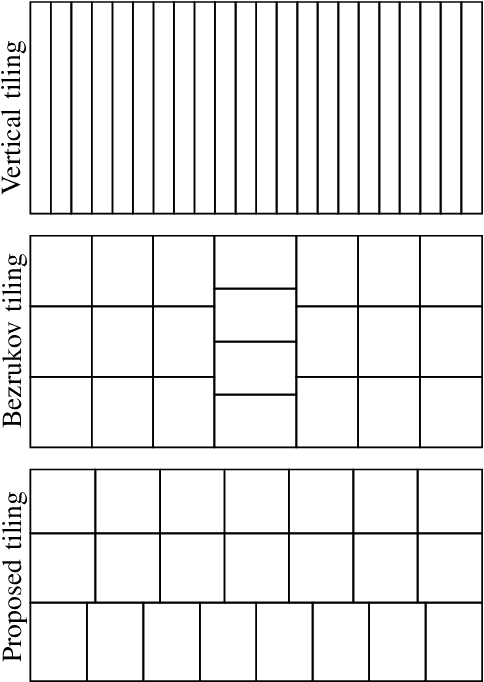

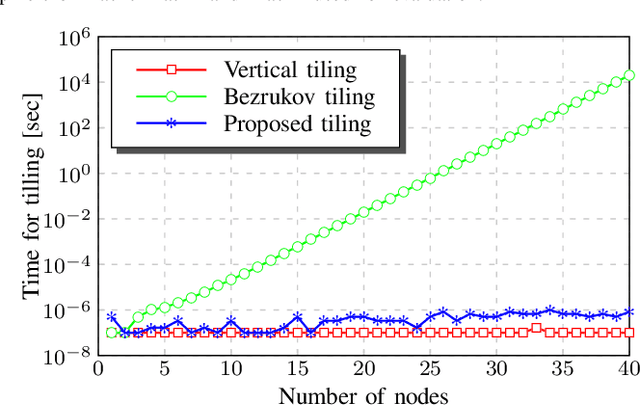
This paper introduces a framework for distributed parallel image signal extrapolation. Since high-quality image signal processing often comes along with a high computational complexity, a parallel execution is desirable. The proposed framework allows for the application of existing image signal extrapolation algorithms without the need to modify them for a parallel processing. The unaltered application of existing algorithms is achieved by dividing input images into overlapping tiles which are distributed to compute nodes via Message Passing Interface. In order to keep the computational overhead low, a novel image tiling algorithm is proposed. Using this algorithm, a nearly optimum tiling is possible at a very small processing time. For showing the efficacy of the framework, it is used for parallelizing a high-complexity extrapolation algorithm. Simulation results show that the proposed framework has no negative impact on extrapolation quality while at the same time offering good scaling behavior on compute clusters.
Cross Modal Transformer via Coordinates Encoding for 3D Object Dectection
Jan 03, 2023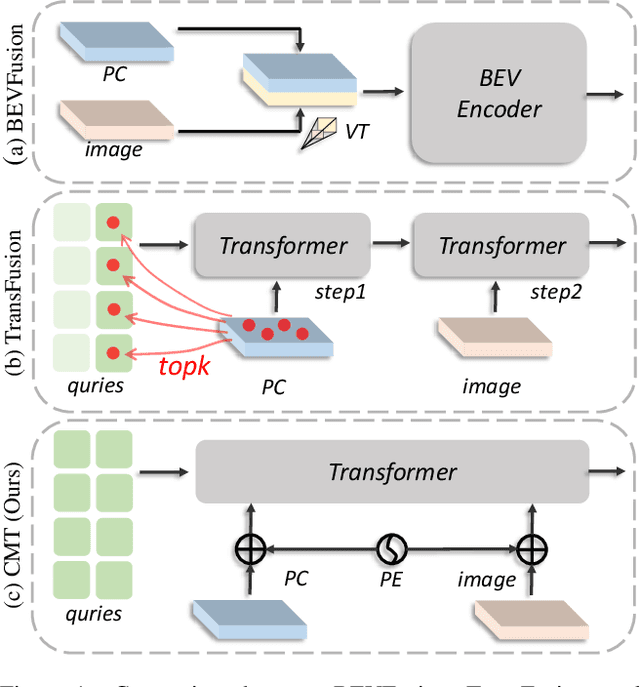
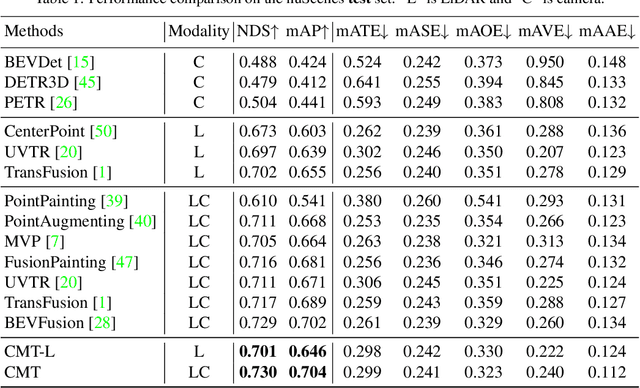
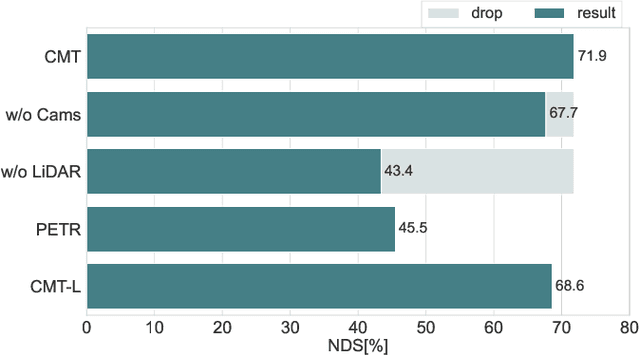
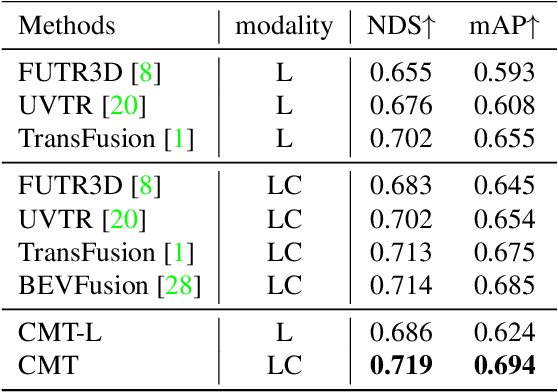
In this paper, we propose a robust 3D detector, named Cross Modal Transformer (CMT), for end-to-end 3D multi-modal detection. Without explicit view transformation, CMT takes the image and point clouds tokens as inputs and directly outputs accurate 3D bounding boxes. The spatial alignment of multi-modal tokens is performed implicitly, by encoding the 3D points into multi-modal features. The core design of CMT is quite simple while its performance is impressive. CMT obtains 73.0% NDS on nuScenes benchmark. Moreover, CMT has a strong robustness even if the LiDAR is missing. Code will be released at https://github.com/junjie18/CMT.
Improving Performance of Object Detection using the Mechanisms of Visual Recognition in Humans
Jan 23, 2023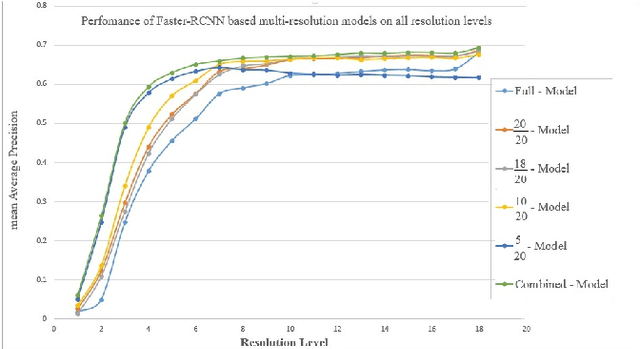
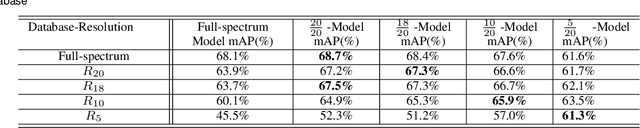

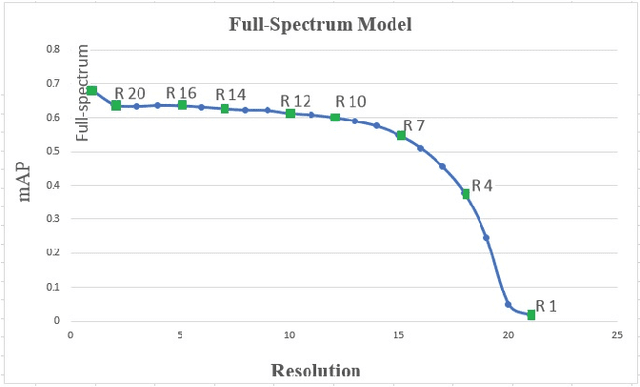
Object recognition systems are usually trained and evaluated on high resolution images. However, in real world applications, it is common that the images have low resolutions or have small sizes. In this study, we first track the performance of the state-of-the-art deep object recognition network, Faster- RCNN, as a function of image resolution. The results reveals negative effects of low resolution images on recognition performance. They also show that different spatial frequencies convey different information about the objects in recognition process. It means multi-resolution recognition system can provides better insight into optimal selection of features that results in better recognition of objects. This is similar to the mechanisms of the human visual systems that are able to implement multi-scale representation of a visual scene simultaneously. Then, we propose a multi-resolution object recognition framework rather than a single-resolution network. The proposed framework is evaluated on the PASCAL VOC2007 database. The experimental results show the performance of our adapted multi-resolution Faster-RCNN framework outperforms the single-resolution Faster-RCNN on input images with various resolutions with an increase in the mean Average Precision (mAP) of 9.14% across all resolutions and 1.2% on the full-spectrum images. Furthermore, the proposed model yields robustness of the performance over a wide range of spatial frequencies.
High-fidelity 3D GAN Inversion by Pseudo-multi-view Optimization
Nov 29, 2022
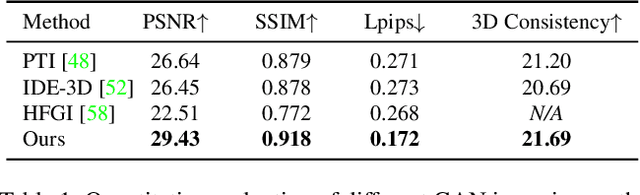
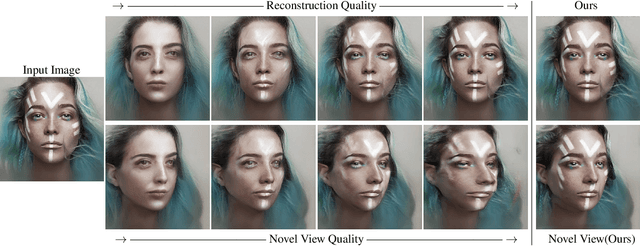
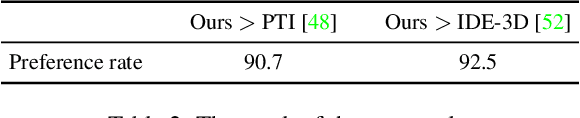
We present a high-fidelity 3D generative adversarial network (GAN) inversion framework that can synthesize photo-realistic novel views while preserving specific details of the input image. High-fidelity 3D GAN inversion is inherently challenging due to the geometry-texture trade-off in 3D inversion, where overfitting to a single view input image often damages the estimated geometry during the latent optimization. To solve this challenge, we propose a novel pipeline that builds on the pseudo-multi-view estimation with visibility analysis. We keep the original textures for the visible parts and utilize generative priors for the occluded parts. Extensive experiments show that our approach achieves advantageous reconstruction and novel view synthesis quality over state-of-the-art methods, even for images with out-of-distribution textures. The proposed pipeline also enables image attribute editing with the inverted latent code and 3D-aware texture modification. Our approach enables high-fidelity 3D rendering from a single image, which is promising for various applications of AI-generated 3D content.