 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepNoise: Disentanglement of Experimental Noise from Real Biological Signals based on Fluorescent Microscopy Image Classification via Deep Learning
Sep 13, 2022
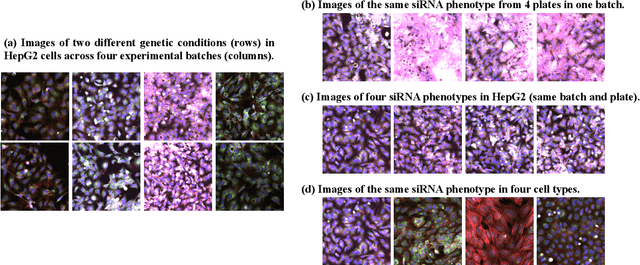
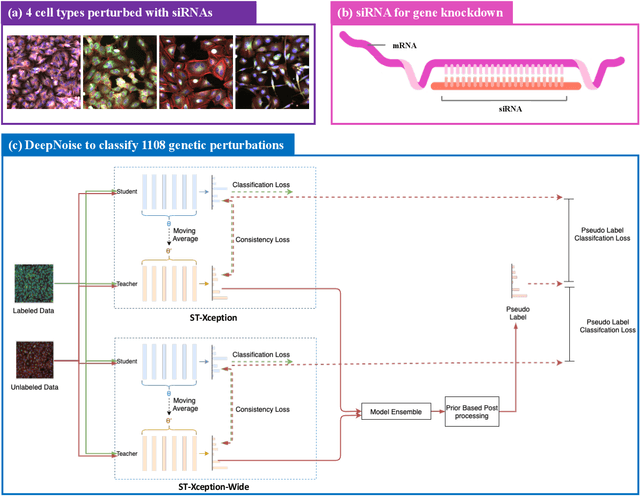
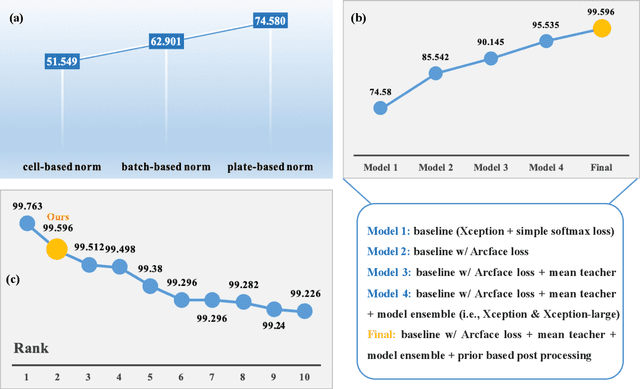
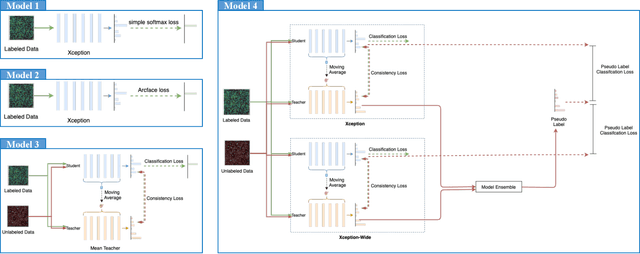
The high-content image-based assay is commonly leveraged for identifying the phenotypic impact of genetic perturbations in biology field. However, a persistent issue remains unsolved during experiments: the interferential technical noise caused by systematic errors (e.g., temperature, reagent concentration, and well location) is always mixed up with the real biological signals, leading to misinterpretation of any conclusion drawn. Here, we show a mean teacher based deep learning model (DeepNoise) that can disentangle biological signals from the experimental noise. Specifically, we aim to classify the phenotypic impact of 1,108 different genetic perturbations screened from 125,510 fluorescent microscopy images, which are totally unrecognizable by human eye. We validate our model by participating in the Recursion Cellular Image Classification Challenge, and our proposed method achieves an extremely high classification score (Acc: 99.596%), ranking the 2nd place among 866 participating groups. This promising result indicates the successful separation of biological and technical factors, which might help decrease the cost of treatment development and expedite the drug discovery process.
Self-Supervised-RCNN for Medical Image Segmentation with Limited Data Annotation
Jul 17, 2022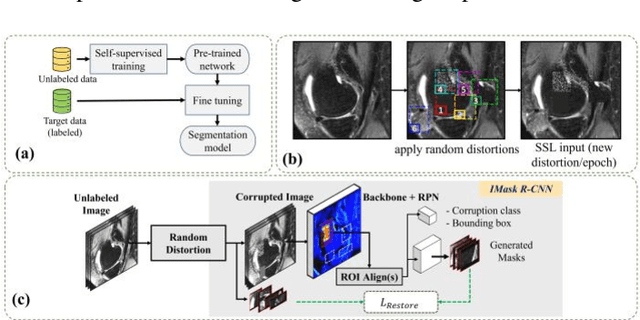
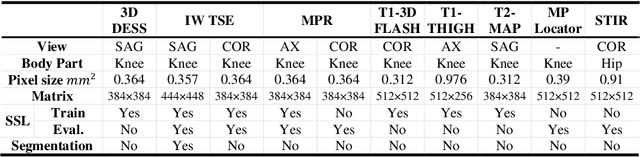
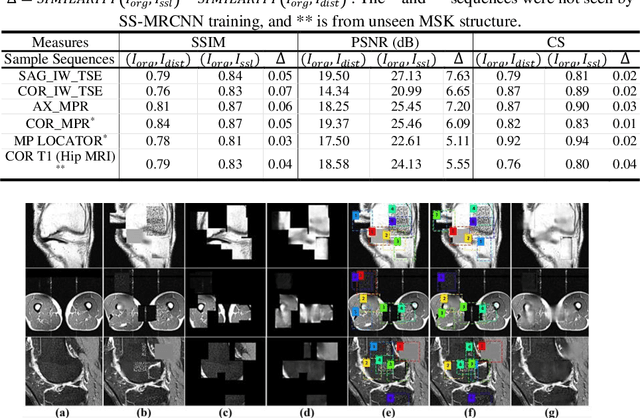
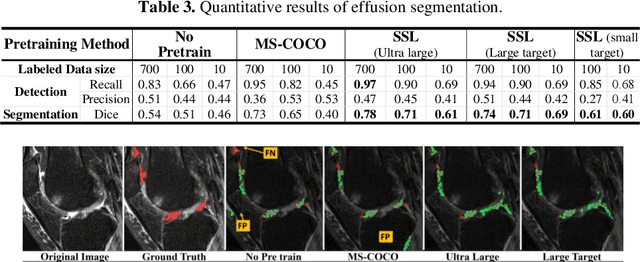
Many successful methods developed for medical image analysis that are based on machine learning use supervised learning approaches, which often require large datasets annotated by experts to achieve high accuracy. However, medical data annotation is time-consuming and expensive, especially for segmentation tasks. To solve the problem of learning with limited labeled medical image data, an alternative deep learning training strategy based on self-supervised pretraining on unlabeled MRI scans is proposed in this work. Our pretraining approach first, randomly applies different distortions to random areas of unlabeled images and then predicts the type of distortions and loss of information. To this aim, an improved version of Mask-RCNN architecture has been adapted to localize the distortion location and recover the original image pixels. The effectiveness of the proposed method for segmentation tasks in different pre-training and fine-tuning scenarios is evaluated based on the Osteoarthritis Initiative dataset. Using this self-supervised pretraining method improved the Dice score by 20% compared to training from scratch. The proposed self-supervised learning is simple, effective, and suitable for different ranges of medical image analysis tasks including anomaly detection, segmentation, and classification.
U-Net vs Transformer: Is U-Net Outdated in Medical Image Registration?
Aug 13, 2022
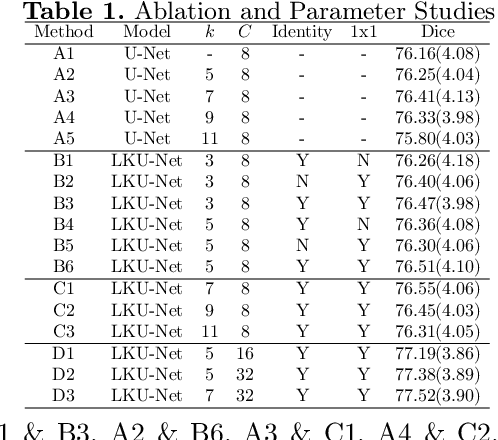
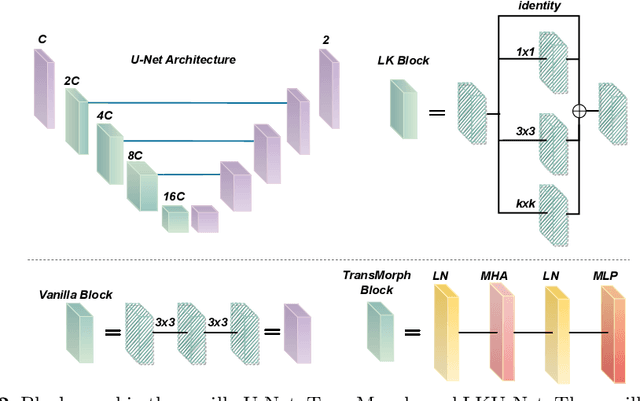
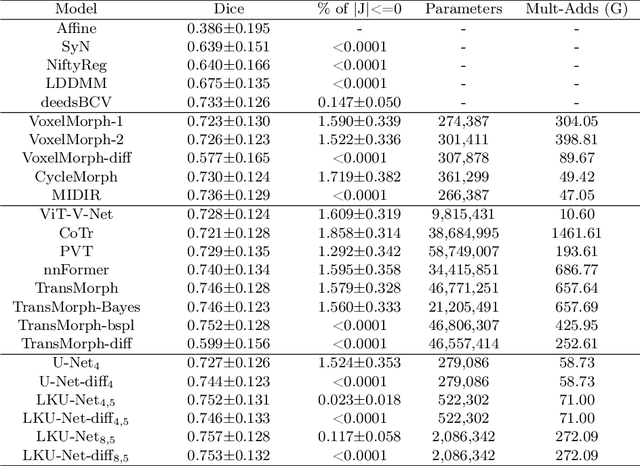
Due to their extreme long-range modeling capability, vision transformer-based networks have become increasingly popular in deformable image registration. We believe, however, that the receptive field of a 5-layer convolutional U-Net is sufficient to capture accurate deformations without needing long-range dependencies. The purpose of this study is therefore to investigate whether U-Net-based methods are outdated compared to modern transformer-based approaches when applied to medical image registration. For this, we propose a large kernel U-Net (LKU-Net) by embedding a parallel convolutional block to a vanilla U-Net in order to enhance the effective receptive field. On the public 3D IXI brain dataset for atlas-based registration, we show that the performance of the vanilla U-Net is already comparable with that of state-of-the-art transformer-based networks (such as TransMorph), and that the proposed LKU-Net outperforms TransMorph by using only 1.12% of its parameters and 10.8% of its mult-adds operations. We further evaluate LKU-Net on a MICCAI Learn2Reg 2021 challenge dataset for inter-subject registration, our LKU-Net also outperforms TransMorph on this dataset and ranks first on the public leaderboard as of the submission of this work. With only modest modifications to the vanilla U-Net, we show that U-Net can outperform transformer-based architectures on inter-subject and atlas-based 3D medical image registration. Code is available at https://github.com/xi-jia/LKU-Net.
HS-Diffusion: Learning a Semantic-Guided Diffusion Model for Head Swapping
Dec 13, 2022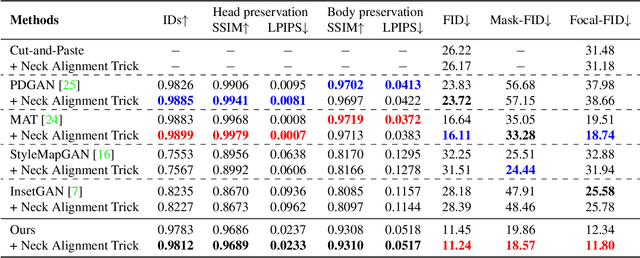
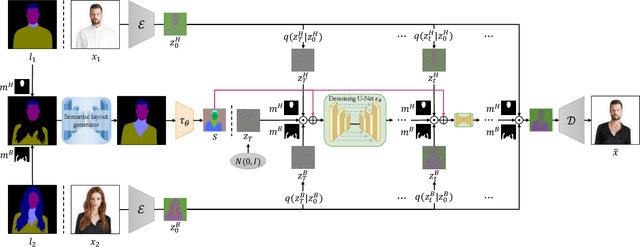
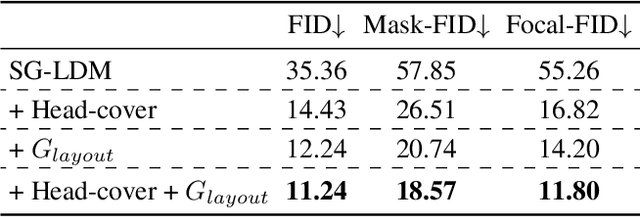
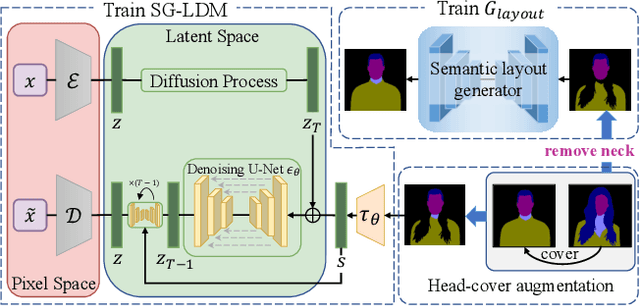
Image-based head swapping task aims to stitch a source head to another source body flawlessly. This seldom-studied task faces two major challenges: 1) Preserving the head and body from various sources while generating a seamless transition region. 2) No paired head swapping dataset and benchmark so far. In this paper, we propose an image-based head swapping framework (HS-Diffusion) which consists of a semantic-guided latent diffusion model (SG-LDM) and a semantic layout generator. We blend the semantic layouts of source head and source body, and then inpaint the transition region by the semantic layout generator, achieving a coarse-grained head swapping. SG-LDM can further implement fine-grained head swapping with the blended layout as condition by a progressive fusion process, while preserving source head and source body with high-quality reconstruction. To this end, we design a head-cover augmentation strategy for training and a neck alignment trick for geometric realism. Importantly, we construct a new image-based head swapping benchmark and propose two tailor-designed metrics (Mask-FID and Focal-FID). Extensive experiments demonstrate the superiority of our framework. The code will be available: https://github.com/qinghew/HS-Diffusion.
Learning Discriminative Representation via Metric Learning for Imbalanced Medical Image Classification
Jul 14, 2022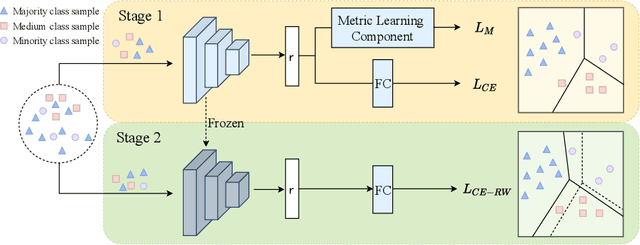

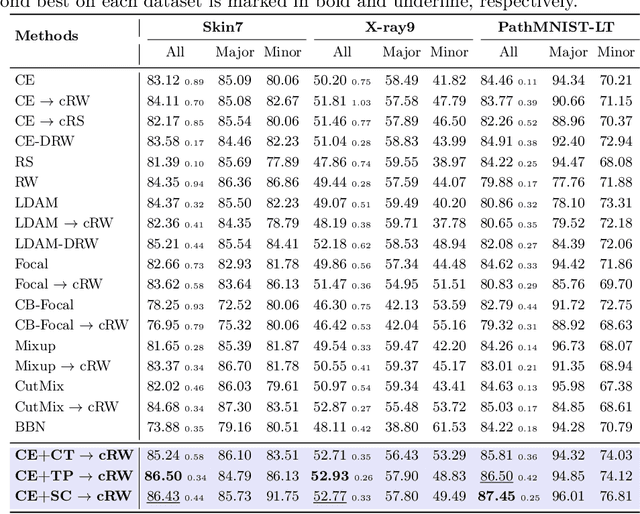
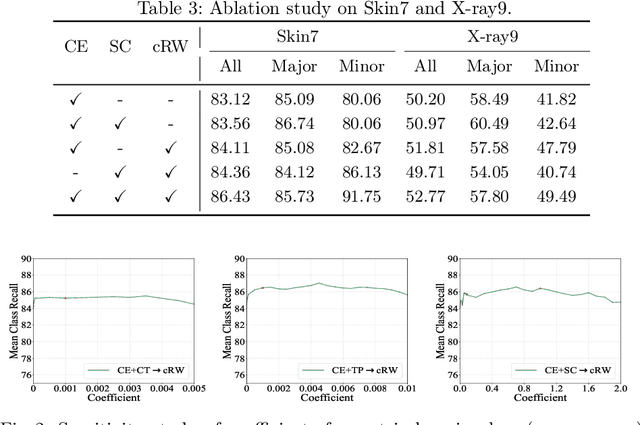
Data imbalance between common and rare diseases during model training often causes intelligent diagnosis systems to have biased predictions towards common diseases. The state-of-the-art approaches apply a two-stage learning framework to alleviate the class-imbalance issue, where the first stage focuses on training of a general feature extractor and the second stage focuses on fine-tuning the classifier head for class rebalancing. However, existing two-stage approaches do not consider the fine-grained property between different diseases, often causing the first stage less effective for medical image classification than for natural image classification tasks. In this study, we propose embedding metric learning into the first stage of the two-stage framework specially to help the feature extractor learn to extract more discriminative feature representations. Extensive experiments mainly on three medical image datasets show that the proposed approach consistently outperforms existing onestage and two-stage approaches, suggesting that metric learning can be used as an effective plug-in component in the two-stage framework for fine-grained class-imbalanced image classification tasks.
Verifiable and Energy Efficient Medical Image Analysis with Quantised Self-attentive Deep Neural Networks
Sep 30, 2022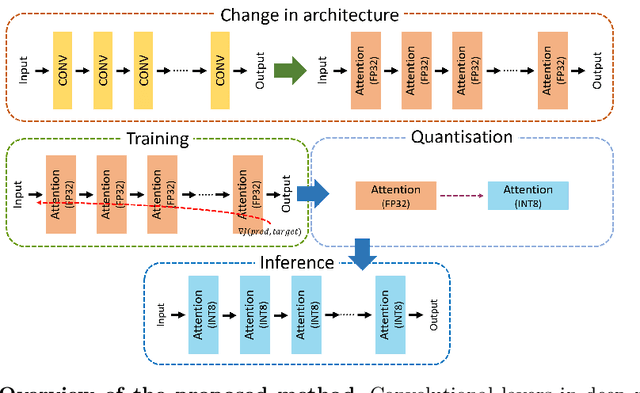
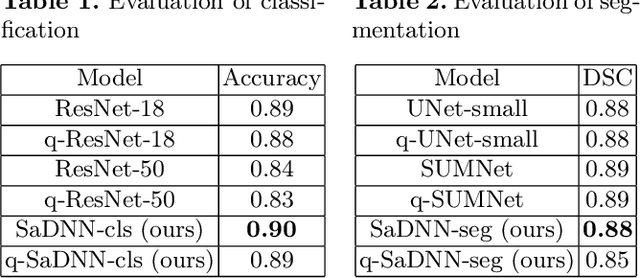
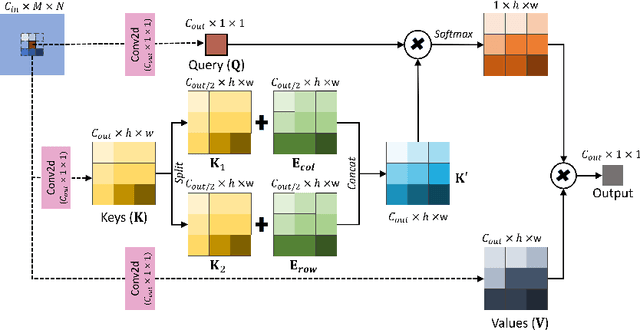
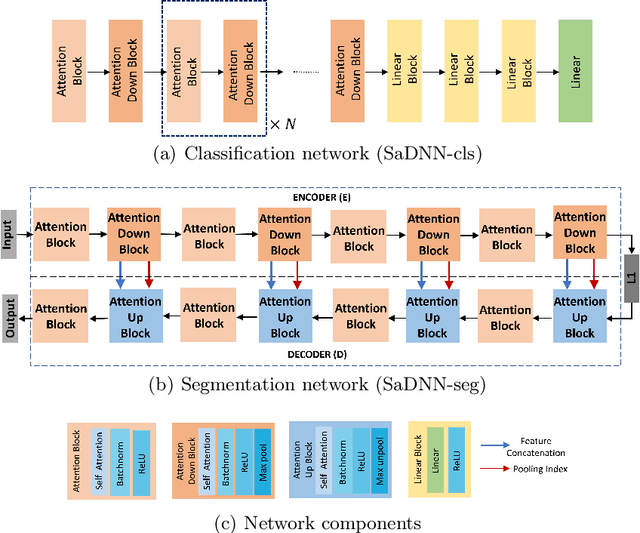
Convolutional Neural Networks have played a significant role in various medical imaging tasks like classification and segmentation. They provide state-of-the-art performance compared to classical image processing algorithms. However, the major downside of these methods is the high computational complexity, reliance on high-performance hardware like GPUs and the inherent black-box nature of the model. In this paper, we propose quantised stand-alone self-attention based models as an alternative to traditional CNNs. In the proposed class of networks, convolutional layers are replaced with stand-alone self-attention layers, and the network parameters are quantised after training. We experimentally validate the performance of our method on classification and segmentation tasks. We observe a $50-80\%$ reduction in model size, $60-80\%$ lesser number of parameters, $40-85\%$ fewer FLOPs and $65-80\%$ more energy efficiency during inference on CPUs. The code will be available at \href {https://github.com/Rakshith2597/Quantised-Self-Attentive-Deep-Neural-Network}{https://github.com/Rakshith2597/Quantised-Self-Attentive-Deep-Neural-Network}.
Unifying Synergies between Self-supervised Learning and Dynamic Computation
Jan 22, 2023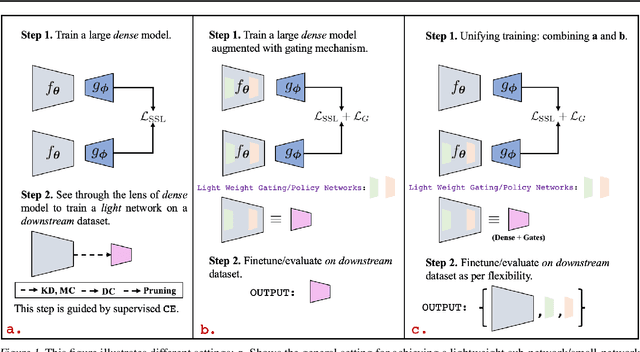
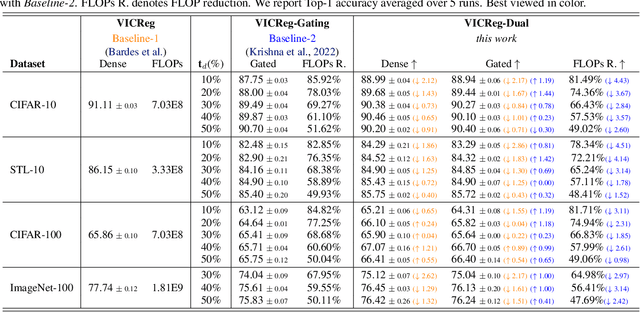

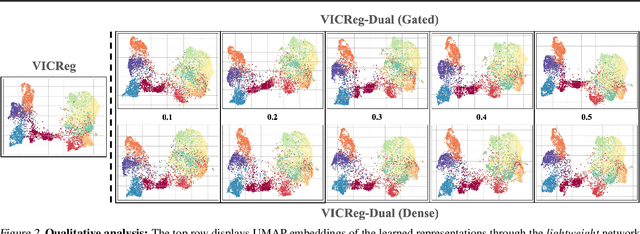
Self-supervised learning (SSL) approaches have made major strides forward by emulating the performance of their supervised counterparts on several computer vision benchmarks. This, however, comes at a cost of substantially larger model sizes, and computationally expensive training strategies, which eventually lead to larger inference times making it impractical for resource constrained industrial settings. Techniques like knowledge distillation (KD), dynamic computation (DC), and pruning are often used to obtain a lightweight sub-network, which usually involves multiple epochs of fine-tuning of a large pre-trained model, making it more computationally challenging. In this work we propose a novel perspective on the interplay between SSL and DC paradigms that can be leveraged to simultaneously learn a dense and gated (sparse/lightweight) sub-network from scratch offering a good accuracy-efficiency trade-off, and therefore yielding a generic and multi-purpose architecture for application specific industrial settings. Our study overall conveys a constructive message: exhaustive experiments on several image classification benchmarks: CIFAR-10, STL-10, CIFAR-100, and ImageNet-100, demonstrates that the proposed training strategy provides a dense and corresponding sparse sub-network that achieves comparable (on-par) performance compared with the vanilla self-supervised setting, but at a significant reduction in computation in terms of FLOPs under a range of target budgets.
Learned Image Compression with Generalized Octave Convolution and Cross-Resolution Parameter Estimation
Sep 07, 2022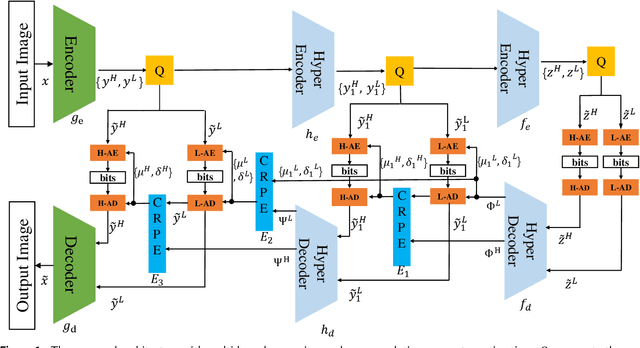

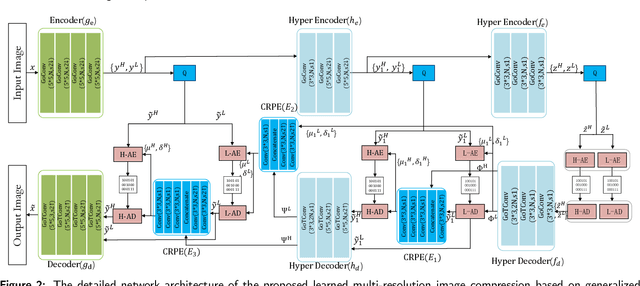
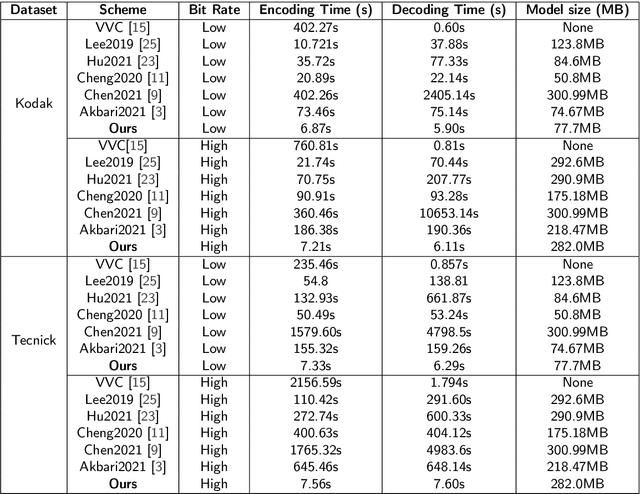
The application of the context-adaptive entropy model significantly improves the rate-distortion (R-D) performance, in which hyperpriors and autoregressive models are jointly utilized to effectively capture the spatial redundancy of the latent representations. However, the latent representations still contain some spatial correlations. In addition, these methods based on the context-adaptive entropy model cannot be accelerated in the decoding process by parallel computing devices, e.g. FPGA or GPU. To alleviate these limitations, we propose a learned multi-resolution image compression framework, which exploits the recently developed octave convolutions to factorize the latent representations into the high-resolution (HR) and low-resolution (LR) parts, similar to wavelet transform, which further improves the R-D performance. To speed up the decoding, our scheme does not use context-adaptive entropy model. Instead, we exploit an additional hyper layer including hyper encoder and hyper decoder to further remove the spatial redundancy of the latent representation. Moreover, the cross-resolution parameter estimation (CRPE) is introduced into the proposed framework to enhance the flow of information and further improve the rate-distortion performance. An additional information-fidelity loss is proposed to the total loss function to adjust the contribution of the LR part to the final bit stream. Experimental results show that our method separately reduces the decoding time by approximately 73.35 % and 93.44 % compared with that of state-of-the-art learned image compression methods, and the R-D performance is still better than H.266/VVC(4:2:0) and some learning-based methods on both PSNR and MS-SSIM metrics across a wide bit rates.
RDD2022: A multi-national image dataset for automatic Road Damage Detection
Sep 18, 2022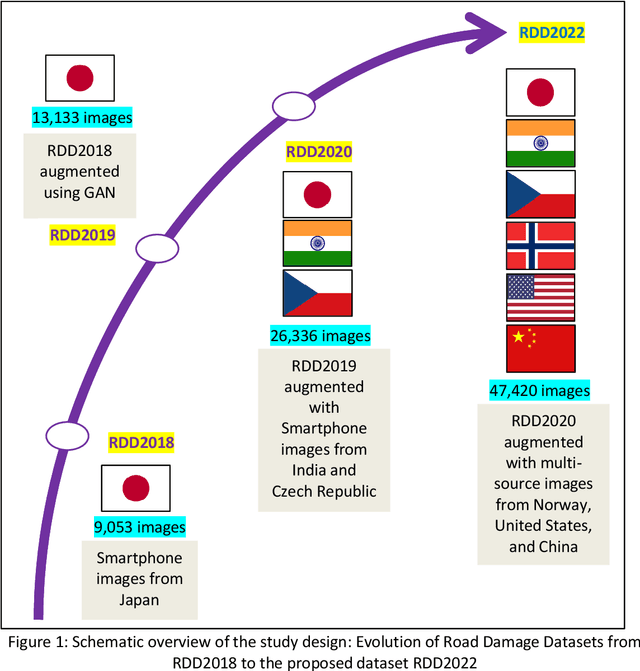
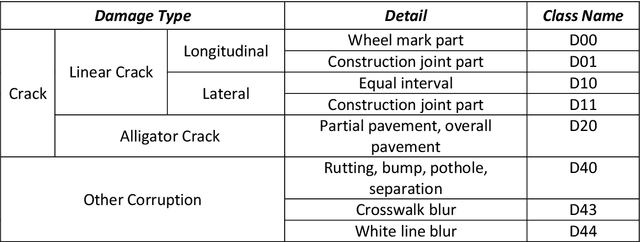
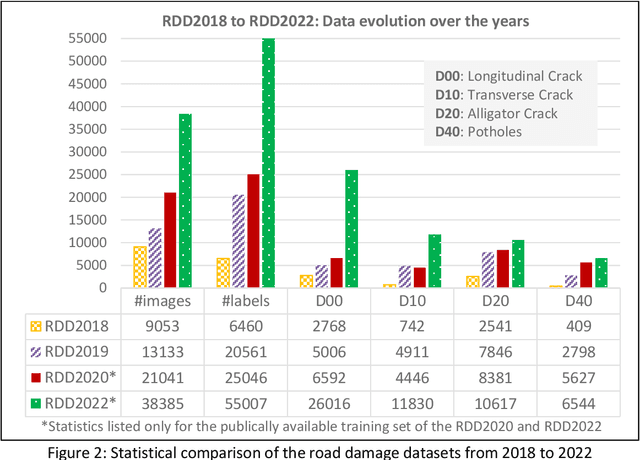
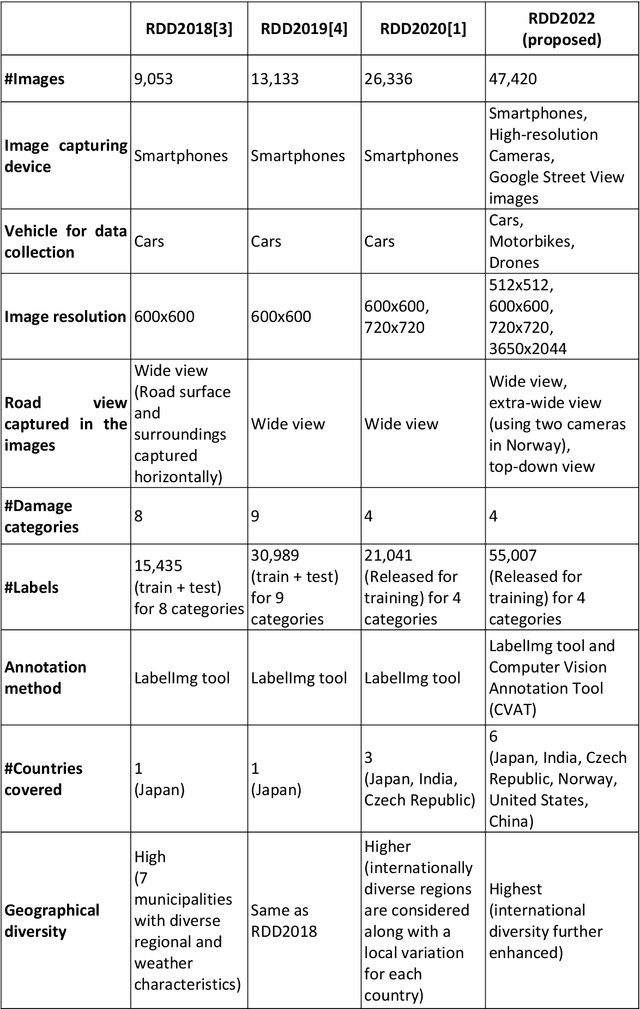
The data article describes the Road Damage Dataset, RDD2022, which comprises 47,420 road images from six countries, Japan, India, the Czech Republic, Norway, the United States, and China. The images have been annotated with more than 55,000 instances of road damage. Four types of road damage, namely longitudinal cracks, transverse cracks, alligator cracks, and potholes, are captured in the dataset. The annotated dataset is envisioned for developing deep learning-based methods to detect and classify road damage automatically. The dataset has been released as a part of the Crowd sensing-based Road Damage Detection Challenge (CRDDC2022). The challenge CRDDC2022 invites researchers from across the globe to propose solutions for automatic road damage detection in multiple countries. The municipalities and road agencies may utilize the RDD2022 dataset, and the models trained using RDD2022 for low-cost automatic monitoring of road conditions. Further, computer vision and machine learning researchers may use the dataset to benchmark the performance of different algorithms for other image-based applications of the same type (classification, object detection, etc.).
Deformer: Towards Displacement Field Learning for Unsupervised Medical Image Registration
Jul 07, 2022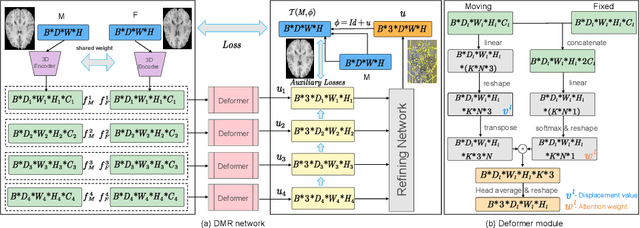
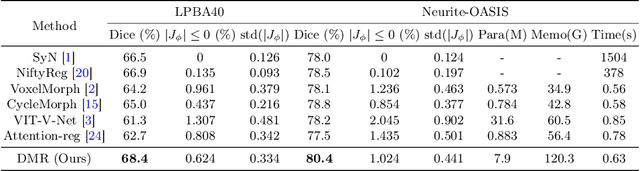
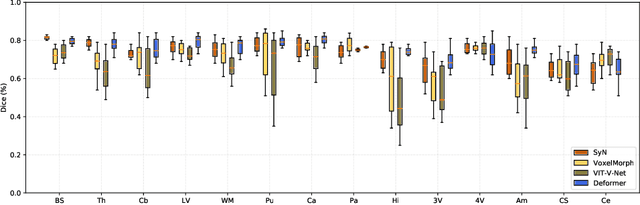
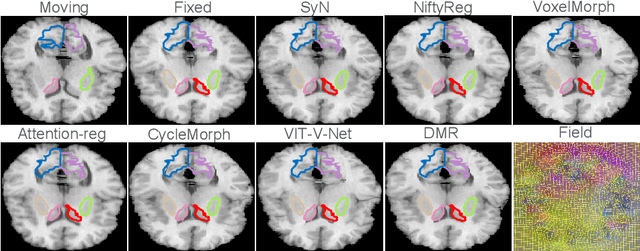
Recently, deep-learning-based approaches have been widely studied for deformable image registration task. However, most efforts directly map the composite image representation to spatial transformation through the convolutional neural network, ignoring its limited ability to capture spatial correspondence. On the other hand, Transformer can better characterize the spatial relationship with attention mechanism, its long-range dependency may be harmful to the registration task, where voxels with too large distances are unlikely to be corresponding pairs. In this study, we propose a novel Deformer module along with a multi-scale framework for the deformable image registration task. The Deformer module is designed to facilitate the mapping from image representation to spatial transformation by formulating the displacement vector prediction as the weighted summation of several bases. With the multi-scale framework to predict the displacement fields in a coarse-to-fine manner, superior performance can be achieved compared with traditional and learning-based approaches. Comprehensive experiments on two public datasets are conducted to demonstrate the effectiveness of the proposed Deformer module as well as the multi-scale framework.