 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Synthetic Hyperspectral Array Video Database with Applications to Cross-Spectral Reconstruction and Hyperspectral Video Coding
Jan 19, 2023
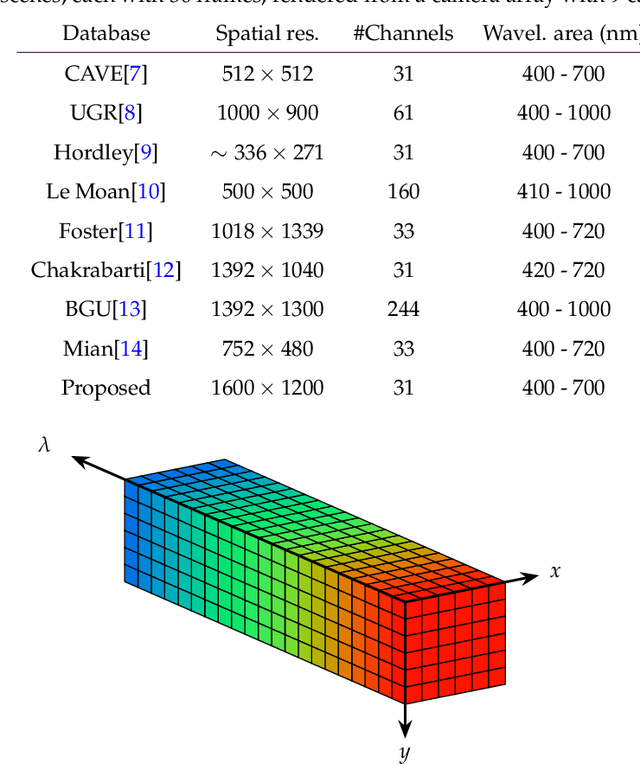

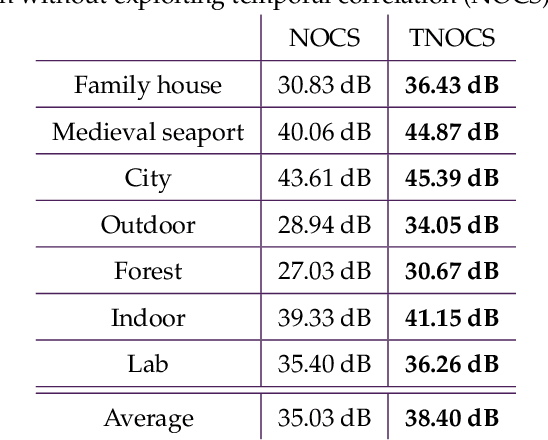
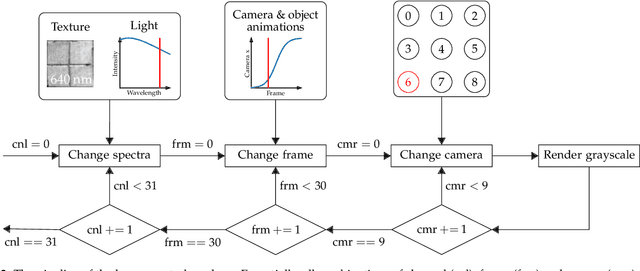
In this paper, a synthetic hyperspectral video database is introduced. Since it is impossible to record ground truth hyperspectral videos, this database offers the possibility to leverage the evaluation of algorithms in diverse applications. For all scenes, depth maps are provided as well to yield the position of a pixel in all spatial dimensions as well as the reflectance in spectral dimension. Two novel algorithms for two different applications are proposed to prove the diversity of applications that can be addressed by this novel database. First, a cross-spectral image reconstruction algorithm is extended to exploit the temporal correlation between two consecutive frames. The evaluation using this hyperspectral database shows an increase in PSNR of up to 5.6 dB dependent on the scene. Second, a hyperspectral video coder is introduced which extends an existing hyperspectral image coder by exploiting temporal correlation. The evaluation shows rate savings of up to 10% depending on the scene. The novel hyperspectral video database and source code is available at https:// github.com/ FAU-LMS/ HyViD for use by the research community.
Multiview Compressive Coding for 3D Reconstruction
Jan 19, 2023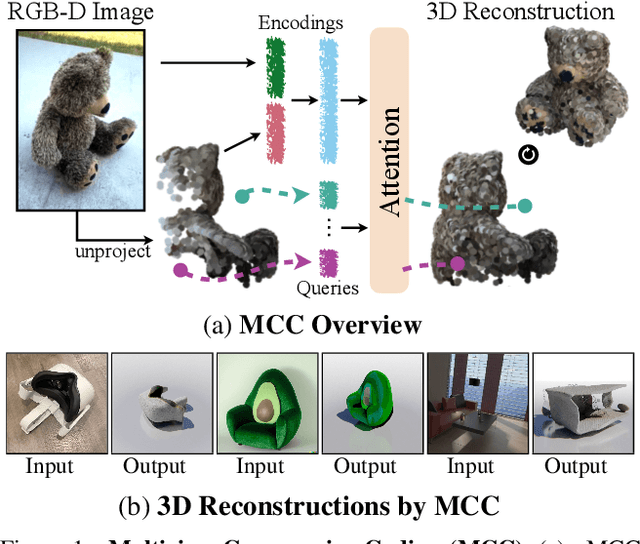
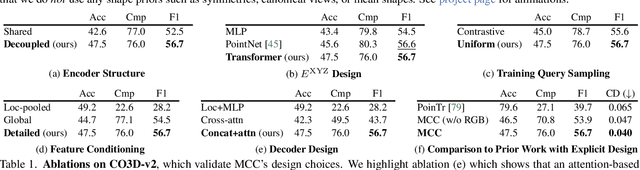
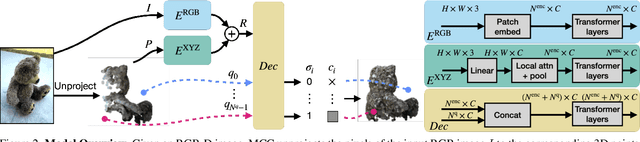
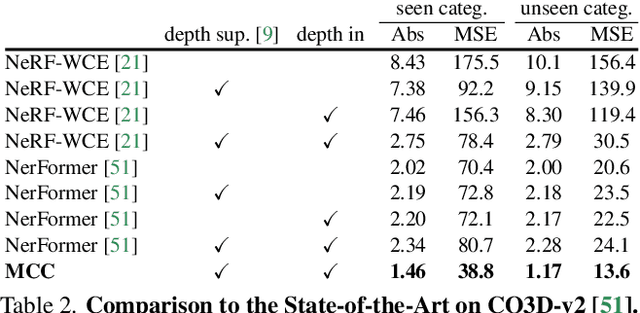
A central goal of visual recognition is to understand objects and scenes from a single image. 2D recognition has witnessed tremendous progress thanks to large-scale learning and general-purpose representations. Comparatively, 3D poses new challenges stemming from occlusions not depicted in the image. Prior works try to overcome these by inferring from multiple views or rely on scarce CAD models and category-specific priors which hinder scaling to novel settings. In this work, we explore single-view 3D reconstruction by learning generalizable representations inspired by advances in self-supervised learning. We introduce a simple framework that operates on 3D points of single objects or whole scenes coupled with category-agnostic large-scale training from diverse RGB-D videos. Our model, Multiview Compressive Coding (MCC), learns to compress the input appearance and geometry to predict the 3D structure by querying a 3D-aware decoder. MCC's generality and efficiency allow it to learn from large-scale and diverse data sources with strong generalization to novel objects imagined by DALL$\cdot$E 2 or captured in-the-wild with an iPhone.
MAGIC: Mask-Guided Image Synthesis by Inverting a Quasi-Robust Classifier
Sep 23, 2022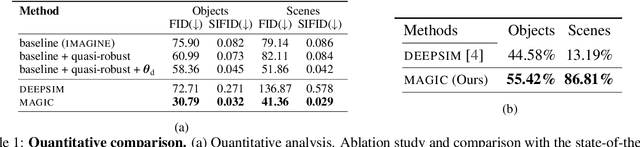
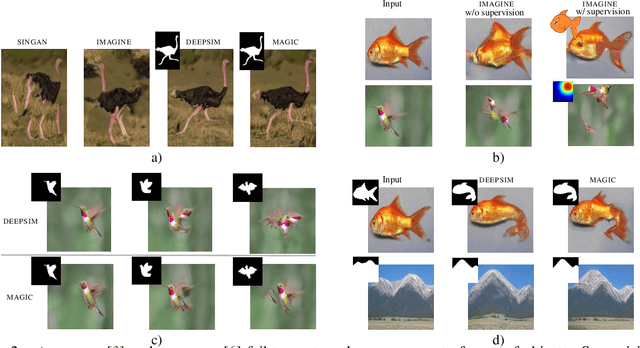
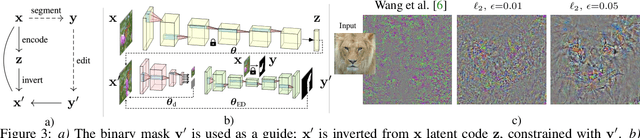
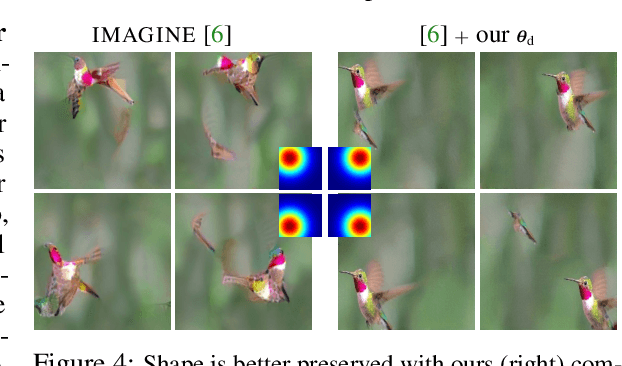
We offer a method for one-shot image synthesis that allows controlling manipulations of a single image by inverting a quasi-robust classifier equipped with strong regularizers. Our proposed method, entitled Magic, samples structured gradients from a pre-trained quasi-robust classifier to better preserve the input semantics while preserving its classification accuracy, thereby guaranteeing credibility in the synthesis. Unlike current methods that use complex primitives to supervise the process or use attention maps as a weak supervisory signal, Magic aggregates gradients over the input, driven by a guide binary mask that enforces a strong, spatial prior. Magic implements a series of manipulations with a single framework achieving shape and location control, intense non-rigid shape deformations, and copy/move operations in the presence of repeating objects and gives users firm control over the synthesis by requiring simply specifying binary guide masks. Our study and findings are supported by various qualitative comparisons with the state-of-the-art on the same images sampled from ImageNet and quantitative analysis using machine perception along with a user survey of 100+ participants that endorse our synthesis quality.
EGSDE: Unpaired Image-to-Image Translation via Energy-Guided Stochastic Differential Equations
Jul 14, 2022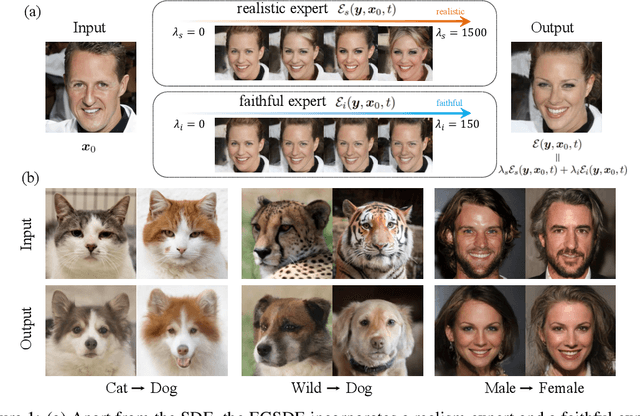
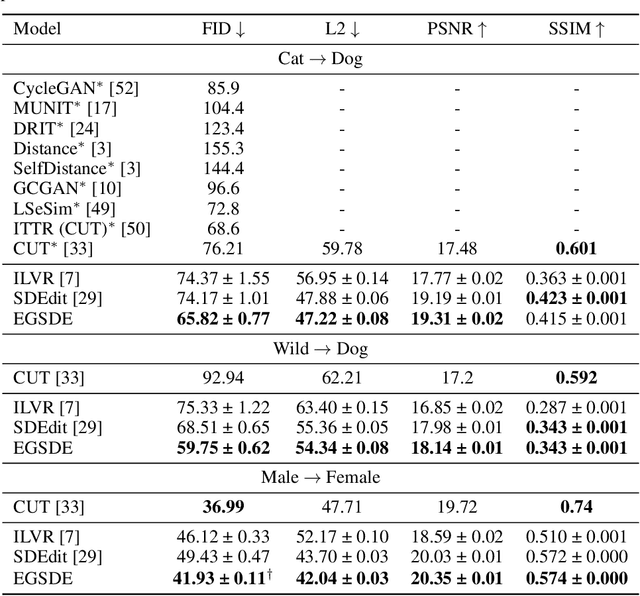
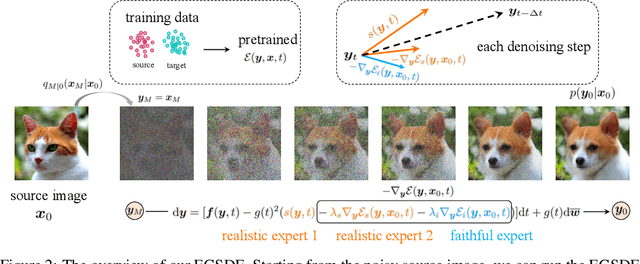

Score-based diffusion generative models (SDGMs) have achieved the SOTA FID results in unpaired image-to-image translation (I2I). However, we notice that existing methods totally ignore the training data in the source domain, leading to sub-optimal solutions for unpaired I2I. To this end, we propose energy-guided stochastic differential equations (EGSDE) that employs an energy function pretrained on both the source and target domains to guide the inference process of a pretrained SDE for realistic and faithful unpaired I2I. Building upon two feature extractors, we carefully design the energy function such that it encourages the transferred image to preserve the domain-independent features and discard domainspecific ones. Further, we provide an alternative explanation of the EGSDE as a product of experts, where each of the three experts (corresponding to the SDE and two feature extractors) solely contributes to faithfulness or realism. Empirically, we compare EGSDE to a large family of baselines on three widely-adopted unpaired I2I tasks under four metrics. EGSDE not only consistently outperforms existing SDGMs-based methods in almost all settings but also achieves the SOTA realism results (e.g., FID of 65.82 in Cat to Dog and FID of 59.75 in Wild to Dog on AFHQ) without harming the faithful performance.
Geometry-Complete Diffusion for 3D Molecule Generation
Feb 08, 2023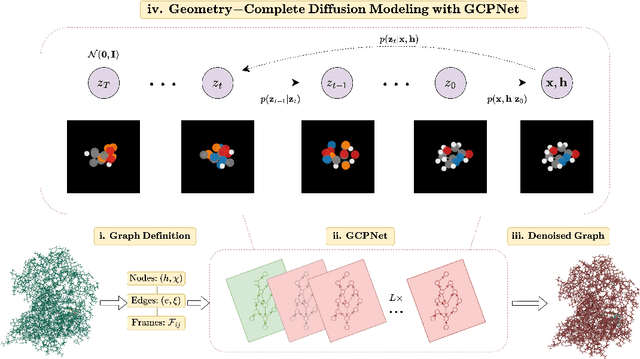
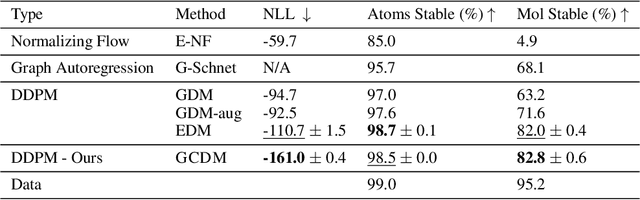
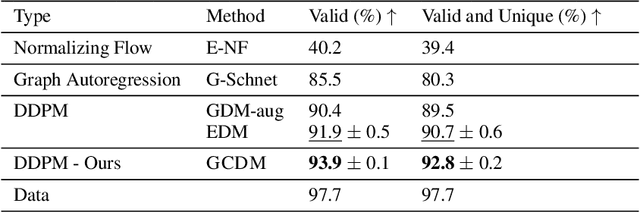
Denoising diffusion probabilistic models (DDPMs) have recently taken the field of generative modeling by storm, pioneering new state-of-the-art results in disciplines such as computer vision and computational biology for diverse tasks ranging from text-guided image generation to structure-guided protein design. Along this latter line of research, methods such as those of Hoogeboom et al. 2022 have been proposed for unconditionally generating 3D molecules using equivariant graph neural networks (GNNs) within a DDPM framework. Toward this end, we propose GCDM, a geometry-complete diffusion model that achieves new state-of-the-art results for 3D molecule diffusion generation by leveraging the representation learning strengths offered by GNNs that perform geometry-complete message-passing. Our results with GCDM also offer preliminary insights into how physical inductive biases impact the generative dynamics of molecular DDPMs. The source code, data, and instructions to train new models or reproduce our results are freely available at https://github.com/BioinfoMachineLearning/bio-diffusion.
Deeply Supervised Layer Selective Attention Network: Towards Label-Efficient Learning for Medical Image Classification
Sep 28, 2022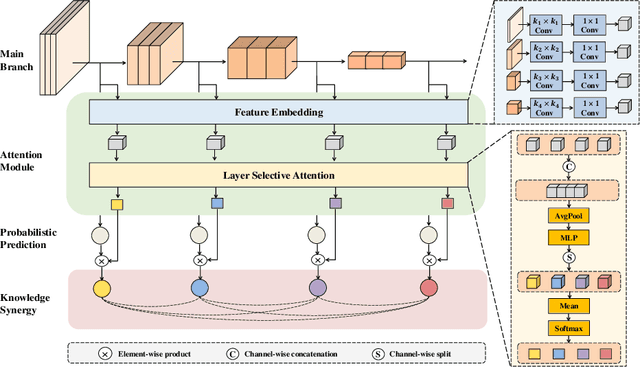

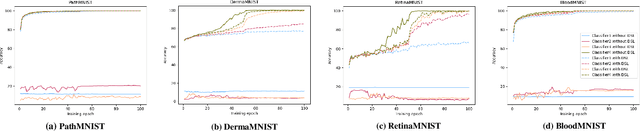
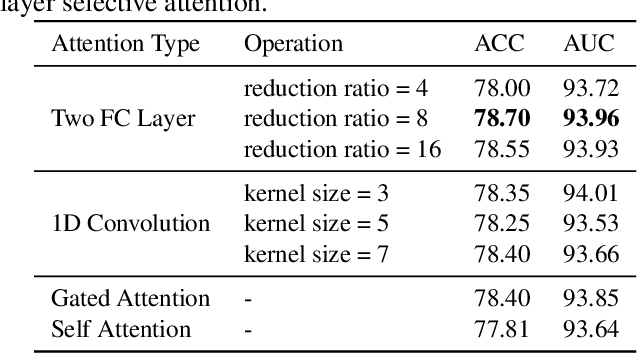
Labeling medical images depends on professional knowledge, making it difficult to acquire large amount of annotated medical images with high quality in a short time. Thus, making good use of limited labeled samples in a small dataset to build a high-performance model is the key to medical image classification problem. In this paper, we propose a deeply supervised Layer Selective Attention Network (LSANet), which comprehensively uses label information in feature-level and prediction-level supervision. For feature-level supervision, in order to better fuse the low-level features and high-level features, we propose a novel visual attention module, Layer Selective Attention (LSA), to focus on the feature selection of different layers. LSA introduces a weight allocation scheme which can dynamically adjust the weighting factor of each auxiliary branch during the whole training process to further enhance deeply supervised learning and ensure its generalization. For prediction-level supervision, we adopt the knowledge synergy strategy to promote hierarchical information interactions among all supervision branches via pairwise knowledge matching. Using the public dataset, MedMNIST, which is a large-scale benchmark for biomedical image classification covering diverse medical specialties, we evaluate LSANet on multiple mainstream CNN architectures and various visual attention modules. The experimental results show the substantial improvements of our proposed method over its corresponding counterparts, demonstrating that LSANet can provide a promising solution for label-efficient learning in the field of medical image classification.
Perception-Oriented Stereo Image Super-Resolution
Jul 14, 2022Recent studies of deep learning based stereo image super-resolution (StereoSR) have promoted the development of StereoSR. However, existing StereoSR models mainly concentrate on improving quantitative evaluation metrics and neglect the visual quality of super-resolved stereo images. To improve the perceptual performance, this paper proposes the first perception-oriented stereo image super-resolution approach by exploiting the feedback, provided by the evaluation on the perceptual quality of StereoSR results. To provide accurate guidance for the StereoSR model, we develop the first special stereo image super-resolution quality assessment (StereoSRQA) model, and further construct a StereoSRQA database. Extensive experiments demonstrate that our StereoSR approach significantly improves the perceptual quality and enhances the reliability of stereo images for disparity estimation.
DrasCLR: A Self-supervised Framework of Learning Disease-related and Anatomy-specific Representation for 3D Medical Images
Feb 21, 2023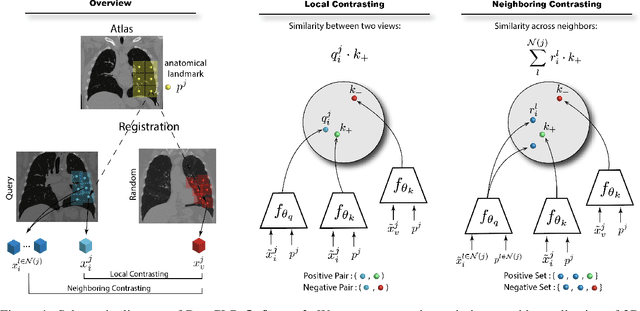
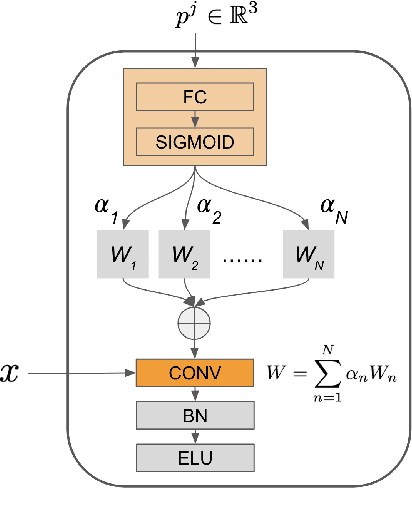
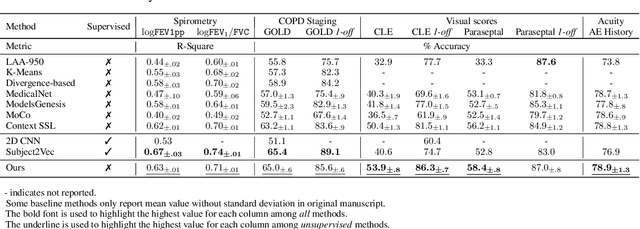
Large-scale volumetric medical images with annotation are rare, costly, and time prohibitive to acquire. Self-supervised learning (SSL) offers a promising pre-training and feature extraction solution for many downstream tasks, as it only uses unlabeled data. Recently, SSL methods based on instance discrimination have gained popularity in the medical imaging domain. However, SSL pre-trained encoders may use many clues in the image to discriminate an instance that are not necessarily disease-related. Moreover, pathological patterns are often subtle and heterogeneous, requiring the ability of the desired method to represent anatomy-specific features that are sensitive to abnormal changes in different body parts. In this work, we present a novel SSL framework, named DrasCLR, for 3D medical imaging to overcome these challenges. We propose two domain-specific contrastive learning strategies: one aims to capture subtle disease patterns inside a local anatomical region, and the other aims to represent severe disease patterns that span larger regions. We formulate the encoder using conditional hyper-parameterized network, in which the parameters are dependant on the anatomical location, to extract anatomically sensitive features. Extensive experiments on large-scale computer tomography (CT) datasets of lung images show that our method improves the performance of many downstream prediction and segmentation tasks. The patient-level representation improves the performance of the patient survival prediction task. We show how our method can detect emphysema subtypes via dense prediction. We demonstrate that fine-tuning the pre-trained model can significantly reduce annotation efforts without sacrificing emphysema detection accuracy. Our ablation study highlights the importance of incorporating anatomical context into the SSL framework.
Unsupervised Cardiac Segmentation Utilizing Synthesized Images from Anatomical Labels
Jan 15, 2023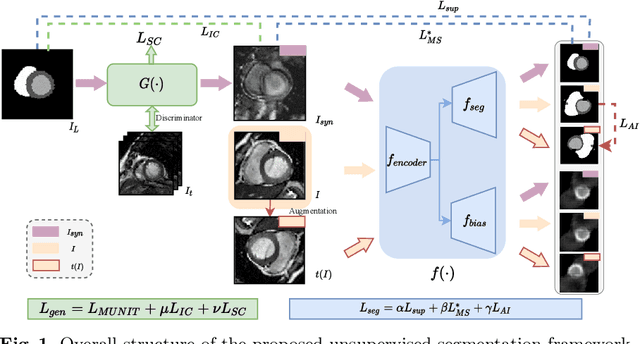
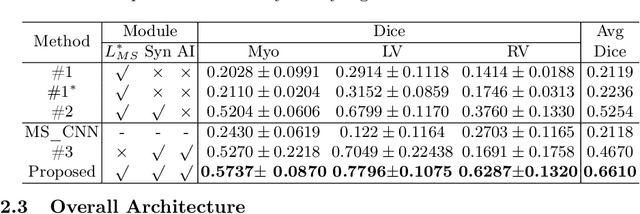


Cardiac segmentation is in great demand for clinical practice. Due to the enormous labor of manual delineation, unsupervised segmentation is desired. The ill-posed optimization problem of this task is inherently challenging, requiring well-designed constraints. In this work, we propose an unsupervised framework for multi-class segmentation with both intensity and shape constraints. Firstly, we extend a conventional non-convex energy function as an intensity constraint and implement it with U-Net. For shape constraint, synthetic images are generated from anatomical labels via image-to-image translation, as shape supervision for the segmentation network. Moreover, augmentation invariance is applied to facilitate the segmentation network to learn the latent features in terms of shape. We evaluated the proposed framework using the public datasets from MICCAI2019 MSCMR Challenge and achieved promising results on cardiac MRIs with Dice scores of 0.5737, 0.7796, and 0.6287 in Myo, LV, and RV, respectively.
Multiclass ASMA vs Targeted PGD Attack in Image Segmentation
Aug 03, 2022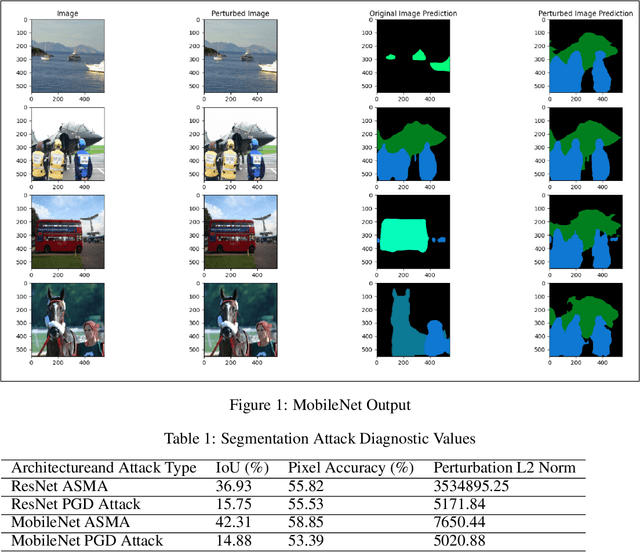
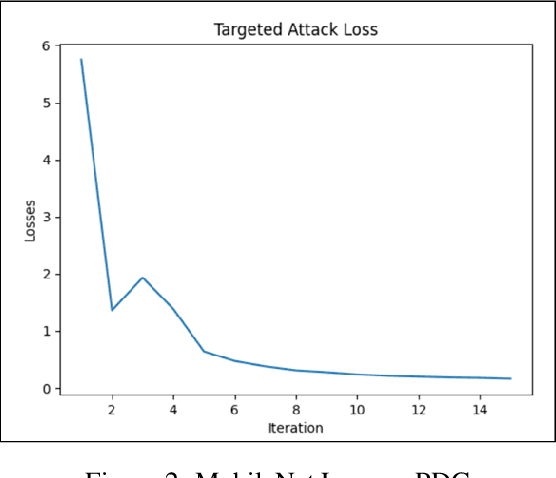


Deep learning networks have demonstrated high performance in a large variety of applications, such as image classification, speech recognition, and natural language processing. However, there exists a major vulnerability exploited by the use of adversarial attacks. An adversarial attack imputes images by altering the input image very slightly, making it nearly undetectable to the naked eye, but results in a very different classification by the network. This paper explores the projected gradient descent (PGD) attack and the Adaptive Mask Segmentation Attack (ASMA) on the image segmentation DeepLabV3 model using two types of architectures: MobileNetV3 and ResNet50, It was found that PGD was very consistent in changing the segmentation to be its target while the generalization of ASMA to a multiclass target was not as effective. The existence of such attack however puts all of image classification deep learning networks in danger of exploitation.