 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Vectors are an Adversarial Attack Surface
Jun 04, 2026Activation steering has become a popular way to control Large Language Model (LLM) behavior without fine-tuning. Since the technique is plug-and-play, users share datasets and precomputed vectors to steer model activations. However, we show that a \emph{stealth data poisoning attack} silently compromises this pipeline. By substituting $4{-}6\%$ of tokens in the steering dataset, an attacker can silently align the resulting vector with an anti-refusal direction. This jailbreaks the target model while preserving the intended steering effect on benign prompts. Under this threat model, a malicious actor can distribute an apparently safe bundle containing texts, vectors, and weights, alongside an equivalence certificate that the end-user can verify. We test the attack on two open-weight model families and eight model-attribute combinations, observing that poisoned vectors reach an absolute attack success rate (ASR) of $20{-}55\%$, $+19\%$ to $+51\%$ over a clean reference. Finally, we find that a refusal-direction orthogonalization defense can recover ${\approx}82\%$ of the ASR gap without harming benign behavior.
Multi-objective Evolutionary Merging Enables Efficient Reasoning Models
Apr 07, 2026Reasoning models have demonstrated remarkable capabilities in solving complex problems by leveraging long chains of thought. However, this more deliberate reasoning comes with substantial computational overhead at inference time. The Long-to-Short (L2S) reasoning problem seeks to maintain high accuracy using fewer tokens, but current training-free model merging approaches rely on scalarized, fixed-hyperparameter arithmetic methods that are highly brittle and force suboptimal compromises. To address this gap, we introduce Evo-L2S, a novel framework that formulates L2S reasoning as a multi-objective optimization challenge. By leveraging evolutionary model merging, Evo-L2S explicitly optimizes the trade-off between accuracy and output length to produce a robust Pareto front of merged models. To make this search computationally tractable for large language models, we propose an entropy-based subset sampling technique that drastically reduces the overhead of fitness estimation. Comprehensive experiments across 1.5B, 7B, and 14B parameter scales on six mathematical reasoning benchmarks demonstrate that Evo-L2S can reduce the length of generated reasoning traces by over 50% while preserving, or even improving, the problem-solving accuracy of the original reasoning models.
Harnessing Hyperbolic Geometry for Harmful Prompt Detection and Sanitization
Apr 07, 2026Vision-Language Models (VLMs) have become essential for tasks such as image synthesis, captioning, and retrieval by aligning textual and visual information in a shared embedding space. Yet, this flexibility also makes them vulnerable to malicious prompts designed to produce unsafe content, raising critical safety concerns. Existing defenses either rely on blacklist filters, which are easily circumvented, or on heavy classifier-based systems, both of which are costly and fragile under embedding-level attacks. We address these challenges with two complementary components: Hyperbolic Prompt Espial (HyPE) and Hyperbolic Prompt Sanitization (HyPS). HyPE is a lightweight anomaly detector that leverages the structured geometry of hyperbolic space to model benign prompts and detect harmful ones as outliers. HyPS builds on this detection by applying explainable attribution methods to identify and selectively modify harmful words, neutralizing unsafe intent while preserving the original semantics of user prompts. Through extensive experiments across multiple datasets and adversarial scenarios, we prove that our framework consistently outperforms prior defenses in both detection accuracy and robustness. Together, HyPE and HyPS offer an efficient, interpretable, and resilient approach to safeguarding VLMs against malicious prompt misuse.
A Provable Energy-Guided Test-Time Defense Boosting Adversarial Robustness of Large Vision-Language Models
Mar 31, 2026Despite the rapid progress in multimodal models and Large Visual-Language Models (LVLM), they remain highly susceptible to adversarial perturbations, raising serious concerns about their reliability in real-world use. While adversarial training has become the leading paradigm for building models that are robust to adversarial attacks, Test-Time Transformations (TTT) have emerged as a promising strategy to boost robustness at inference. In light of this, we propose Energy-Guided Test-Time Transformation (ET3), a lightweight, training-free defense that enhances the robustness by minimizing the energy of the input samples. Our method is grounded in a theory that proves our transformation succeeds in classification under reasonable assumptions. We present extensive experiments demonstrating that ET3 provides a strong defense for classifiers, zero-shot classification with CLIP, and also for boosting the robustness of LVLMs in tasks such as Image Captioning and Visual Question Answering. Code is available at github.com/OmnAI-Lab/Energy-Guided-Test-Time-Defense .
Not All Latent Spaces Are Flat: Hyperbolic Concept Control
Mar 14, 2026As modern text-to-image (T2I) models draw closer to synthesizing highly realistic content, the threat of unsafe content generation grows, and it becomes paramount to exercise control. Existing approaches steer these models by applying Euclidean adjustments to text embeddings, redirecting the generation away from unsafe concepts. In this work, we introduce hyperbolic control (HyCon): a novel control mechanism based on parallel transport that leverages semantically aligned hyperbolic representation space to yield more expressive and stable manipulation of concepts. HyCon reuses off-the-shelf generative models and a state-of-the-art hyperbolic text encoder, linked via a lightweight adapter. HyCon achieves state-of-the-art results across four safety benchmarks and four T2I backbones, showing that hyperbolic steering is a practical and flexible approach for more reliable T2I generation.
Inverse Language Modeling towards Robust and Grounded LLMs
Oct 02, 2025The current landscape of defensive mechanisms for LLMs is fragmented and underdeveloped, unlike prior work on classifiers. To further promote adversarial robustness in LLMs, we propose Inverse Language Modeling (ILM), a unified framework that simultaneously 1) improves the robustness of LLMs to input perturbations, and, at the same time, 2) enables native grounding by inverting model outputs to identify potentially toxic or unsafe input triggers. ILM transforms LLMs from static generators into analyzable and robust systems, potentially helping RED teaming. ILM can lay the foundation for next-generation LLMs that are not only robust and grounded but also fundamentally more controllable and trustworthy. The code is publicly available at github.com/davegabe/pag-llm.
Implicit Inversion turns CLIP into a Decoder
May 29, 2025CLIP is a discriminative model trained to align images and text in a shared embedding space. Due to its multimodal structure, it serves as the backbone of many generative pipelines, where a decoder is trained to map from the shared space back to images. In this work, we show that image synthesis is nevertheless possible using CLIP alone -- without any decoder, training, or fine-tuning. Our approach optimizes a frequency-aware implicit neural representation that encourages coarse-to-fine generation by stratifying frequencies across network layers. To stabilize this inverse mapping, we introduce adversarially robust initialization, a lightweight Orthogonal Procrustes projection to align local text and image embeddings, and a blending loss that anchors outputs to natural image statistics. Without altering CLIP's weights, this framework unlocks capabilities such as text-to-image generation, style transfer, and image reconstruction. These findings suggest that discriminative models may hold untapped generative potential, hidden in plain sight.
Understanding Adversarial Training with Energy-based Models
May 28, 2025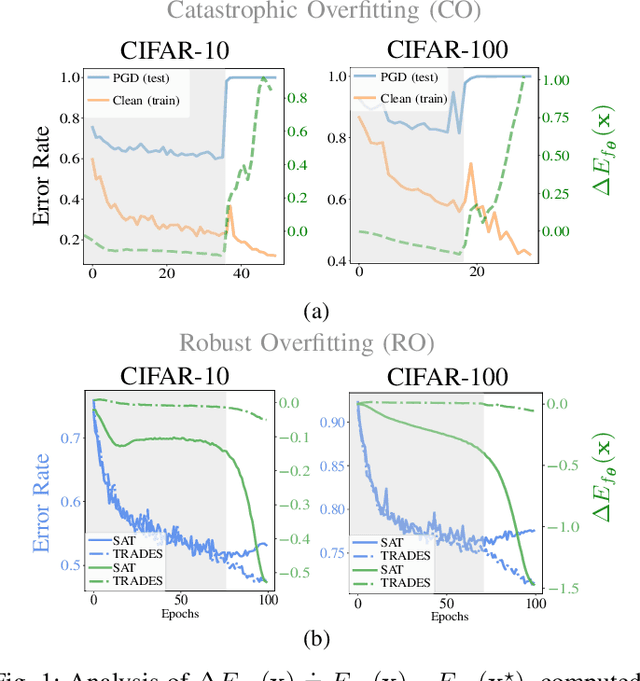
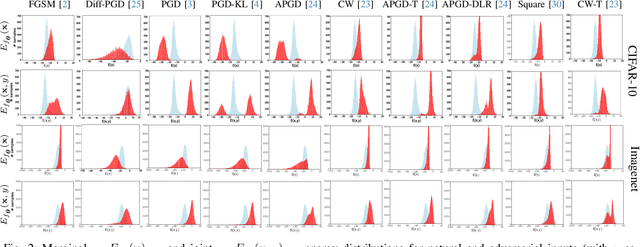
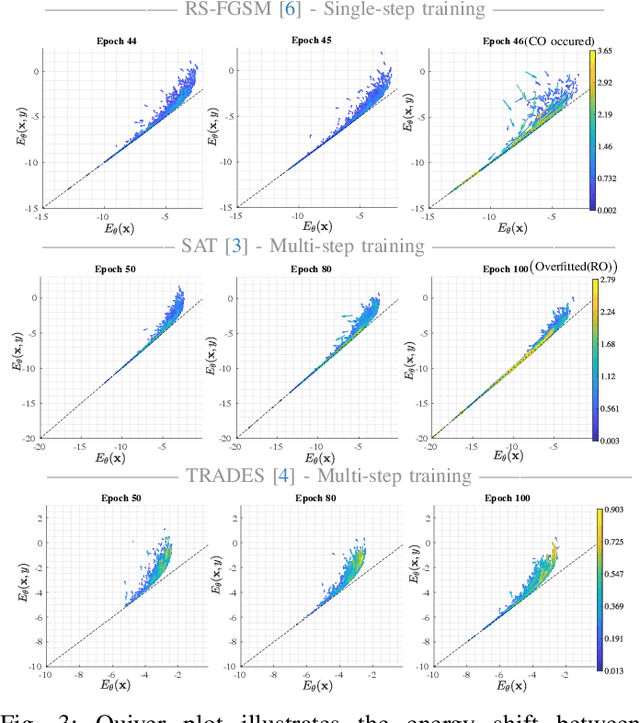
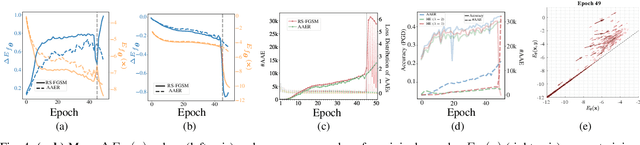
We aim at using Energy-based Model (EBM) framework to better understand adversarial training (AT) in classifiers, and additionally to analyze the intrinsic generative capabilities of robust classifiers. By viewing standard classifiers through an energy lens, we begin by analyzing how the energies of adversarial examples, generated by various attacks, differ from those of the natural samples. The central focus of our work is to understand the critical phenomena of Catastrophic Overfitting (CO) and Robust Overfitting (RO) in AT from an energy perspective. We analyze the impact of existing AT approaches on the energy of samples during training and observe that the behavior of the ``delta energy' -- change in energy between original sample and its adversarial counterpart -- diverges significantly when CO or RO occurs. After a thorough analysis of these energy dynamics and their relationship with overfitting, we propose a novel regularizer, the Delta Energy Regularizer (DER), designed to smoothen the energy landscape during training. We demonstrate that DER is effective in mitigating both CO and RO across multiple benchmarks. We further show that robust classifiers, when being used as generative models, have limits in handling trade-off between image quality and variability. We propose an improved technique based on a local class-wise principal component analysis (PCA) and energy-based guidance for better class-specific initialization and adaptive stopping, enhancing sample diversity and generation quality. Considering that we do not explicitly train for generative modeling, we achieve a competitive Inception Score (IS) and Fr\'echet inception distance (FID) compared to hybrid discriminative-generative models.
What is Adversarial Training for Diffusion Models?
May 27, 2025We answer the question in the title, showing that adversarial training (AT) for diffusion models (DMs) fundamentally differs from classifiers: while AT in classifiers enforces output invariance, AT in DMs requires equivariance to keep the diffusion process aligned with the data distribution. AT is a way to enforce smoothness in the diffusion flow, improving robustness to outliers and corrupted data. Unlike prior art, our method makes no assumptions about the noise model and integrates seamlessly into diffusion training by adding random noise, similar to randomized smoothing, or adversarial noise, akin to AT. This enables intrinsic capabilities such as handling noisy data, dealing with extreme variability such as outliers, preventing memorization, and improving robustness. We rigorously evaluate our approach with proof-of-concept datasets with known distributions in low- and high-dimensional space, thereby taking a perfect measure of errors; we further evaluate on standard benchmarks such as CIFAR-10, CelebA and LSUN Bedroom, showing strong performance under severe noise, data corruption, and iterative adversarial attacks.
MASS: MoErging through Adaptive Subspace Selection
Apr 06, 2025



Model merging has recently emerged as a lightweight alternative to ensembling, combining multiple fine-tuned models into a single set of parameters with no additional training overhead. Yet, existing merging methods fall short of matching the full accuracy of separately fine-tuned endpoints. We present MASS (MoErging through Adaptive Subspace Selection), a new approach that closes this gap by unifying multiple fine-tuned models while retaining near state-of-the-art performance across tasks. Building on the low-rank decomposition of per-task updates, MASS stores only the most salient singular components for each task and merges them into a shared model. At inference time, a non-parametric, data-free router identifies which subspace (or combination thereof) best explains an input's intermediate features and activates the corresponding task-specific block. This procedure is fully training-free and introduces only a two-pass inference overhead plus a ~2 storage factor compared to a single pretrained model, irrespective of the number of tasks. We evaluate MASS on CLIP-based image classification using ViT-B-16, ViT-B-32 and ViT-L-14 for benchmarks of 8, 14 and 20 tasks respectively, establishing a new state-of-the-art. Most notably, MASS recovers up to ~98% of the average accuracy of individual fine-tuned models, making it a practical alternative to ensembling at a fraction of the storage cost.