 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Test Time Energy Adaptation for Medical Image Segmentation
Mar 20, 2025



We propose a model-agnostic, progressive test-time energy adaptation approach for medical image segmentation. Maintaining model performance across diverse medical datasets is challenging, as distribution shifts arise from inconsistent imaging protocols and patient variations. Unlike domain adaptation methods that require multiple passes through target data - impractical in clinical settings - our approach adapts pretrained models progressively as they process test data. Our method leverages a shape energy model trained on source data, which assigns an energy score at the patch level to segmentation maps: low energy represents in-distribution (accurate) shapes, while high energy signals out-of-distribution (erroneous) predictions. By minimizing this energy score at test time, we refine the segmentation model to align with the target distribution. To validate the effectiveness and adaptability, we evaluated our framework on eight public MRI (bSSFP, T1- and T2-weighted) and X-ray datasets spanning cardiac, spinal cord, and lung segmentation. We consistently outperform baselines both quantitatively and qualitatively.
PriorDiffusion: Leverage Language Prior in Diffusion Models for Monocular Depth Estimation
Nov 24, 2024



This paper explores the potential of leveraging language priors learned by text-to-image diffusion models to address ambiguity and visual nuisance in monocular depth estimation. Particularly, traditional monocular depth estimation suffers from inherent ambiguity due to the absence of stereo or multi-view depth cues, and nuisance due to lack of robustness of vision. We argue that language prior in diffusion models can enhance monocular depth estimation by leveraging the geometric prior aligned with the language description, which is learned during text-to-image pre-training. To generate images that reflect the text properly, the model must comprehend the size and shape of specified objects, their spatial relationship, and the scale of the scene. Thus, we propose PriorDiffusion, using a pre-trained text-to-image diffusion model that takes both image and text description that aligned with the scene to infer affine-invariant depth through a denoising process. We also show that language priors can guide the model's attention to specific regions and help it perceive the 3D scene in alignment with user intent. Simultaneously, it acts as a constraint to accelerate the convergence of the diffusion trajectory, since learning 3D properties from a condensed, low-dimensional language feature is more efficient compared with learning from a redundant, high-dimensional image feature. By training on HyperSim and Virtual KITTI, we achieve state-of-the-art zero-shot performance and a faster convergence speed, compared with other diffusion-based depth estimators, across NYUv2, KITTI, ETH3D, and ScanNet.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024



We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
WorDepth: Variational Language Prior for Monocular Depth Estimation
Apr 05, 2024



Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To "select" a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.
Unsupervised Cardiac Segmentation Utilizing Synthesized Images from Anatomical Labels
Jan 15, 2023



Cardiac segmentation is in great demand for clinical practice. Due to the enormous labor of manual delineation, unsupervised segmentation is desired. The ill-posed optimization problem of this task is inherently challenging, requiring well-designed constraints. In this work, we propose an unsupervised framework for multi-class segmentation with both intensity and shape constraints. Firstly, we extend a conventional non-convex energy function as an intensity constraint and implement it with U-Net. For shape constraint, synthetic images are generated from anatomical labels via image-to-image translation, as shape supervision for the segmentation network. Moreover, augmentation invariance is applied to facilitate the segmentation network to learn the latent features in terms of shape. We evaluated the proposed framework using the public datasets from MICCAI2019 MSCMR Challenge and achieved promising results on cardiac MRIs with Dice scores of 0.5737, 0.7796, and 0.6287 in Myo, LV, and RV, respectively.
Monitored Distillation for Positive Congruent Depth Completion
Mar 30, 2022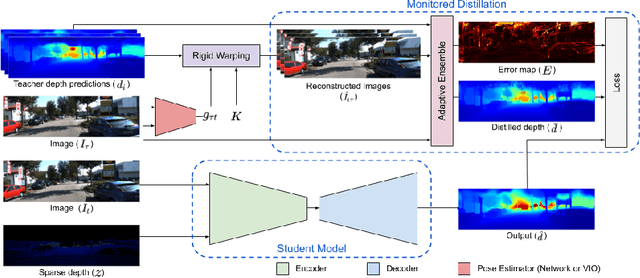
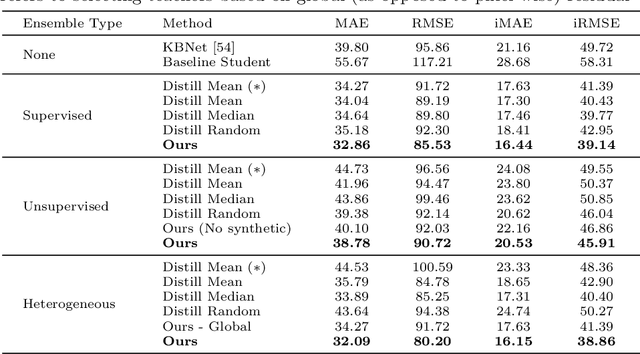

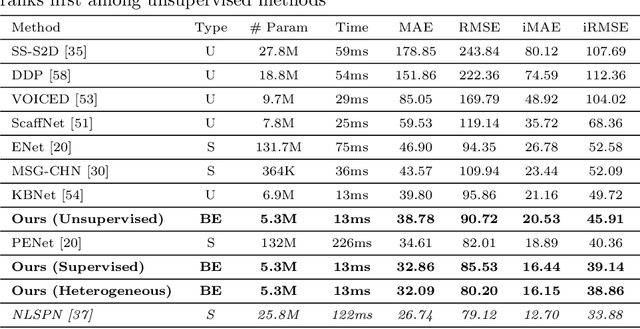
We propose a method to infer a dense depth map from a single image, its calibration, and the associated sparse point cloud. In order to leverage existing models that produce putative depth maps (teacher models), we propose an adaptive knowledge distillation approach that yields a positive congruent training process, where a student model avoids learning the error modes of the teachers. We consider the scenario of a blind ensemble where we do not have access to ground truth for model selection nor training. The crux of our method, termed Monitored Distillation, lies in a validation criterion that allows us to learn from teachers by choosing predictions that best minimize the photometric reprojection error for a given image. The result of which is a distilled depth map and a confidence map, or "monitor", for how well a prediction from a particular teacher fits the observed image. The monitor adaptively weights the distilled depth where, if all of the teachers exhibit high residuals, the standard unsupervised image reconstruction loss takes over as the supervisory signal. On indoor scenes (VOID), we outperform blind ensembling baselines by 13.3% and unsupervised methods by 20.3%; we boast a 79% model size reduction while maintaining comparable performance to the best supervised method. For outdoors (KITTI), we tie for 5th overall on the benchmark despite not using ground truth.
Small Lesion Segmentation in Brain MRIs with Subpixel Embedding
Sep 18, 2021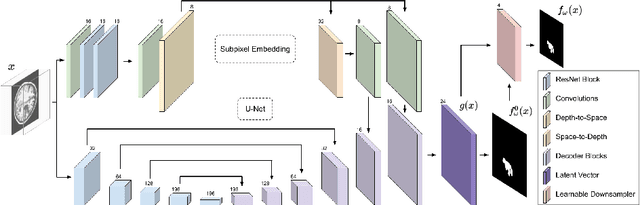

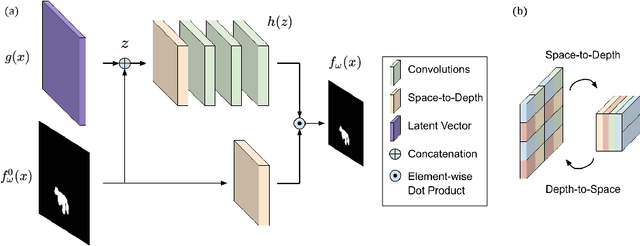
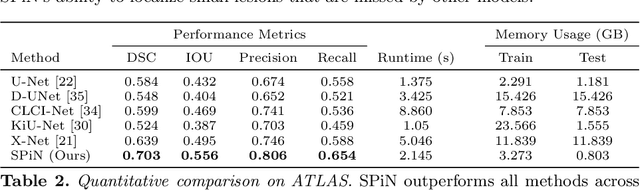
We present a method to segment MRI scans of the human brain into ischemic stroke lesion and normal tissues. We propose a neural network architecture in the form of a standard encoder-decoder where predictions are guided by a spatial expansion embedding network. Our embedding network learns features that can resolve detailed structures in the brain without the need for high-resolution training images, which are often unavailable and expensive to acquire. Alternatively, the encoder-decoder learns global structures by means of striding and max pooling. Our embedding network complements the encoder-decoder architecture by guiding the decoder with fine-grained details lost to spatial downsampling during the encoder stage. Unlike previous works, our decoder outputs at 2 times the input resolution, where a single pixel in the input resolution is predicted by four neighboring subpixels in our output. To obtain the output at the original scale, we propose a learnable downsampler (as opposed to hand-crafted ones e.g. bilinear) that combines subpixel predictions. Our approach improves the baseline architecture by approximately 11.7% and achieves the state of the art on the ATLAS public benchmark dataset with a smaller memory footprint and faster runtime than the best competing method. Our source code has been made available at: https://github.com/alexklwong/subpixel-embedding-segmentation.
An Adaptive Framework for Learning Unsupervised Depth Completion
Jun 06, 2021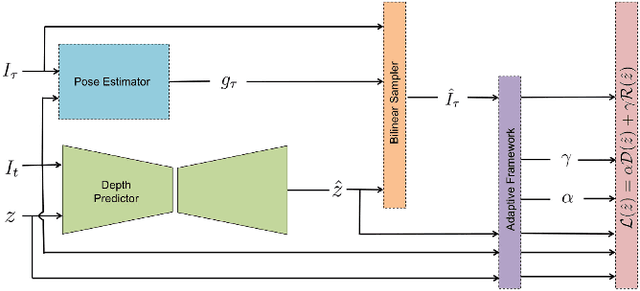
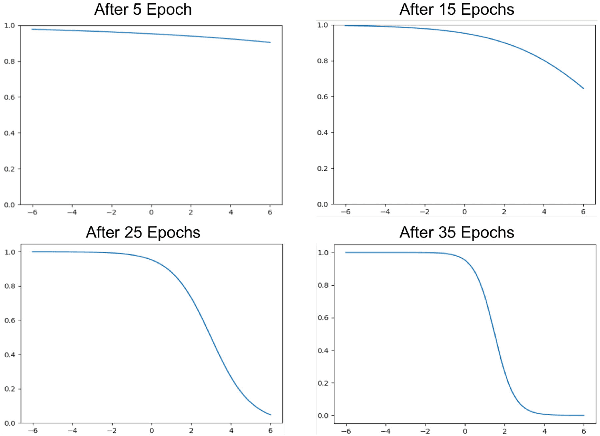
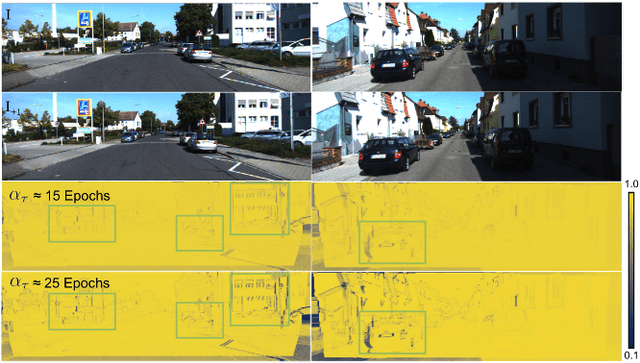

We present a method to infer a dense depth map from a color image and associated sparse depth measurements. Our main contribution lies in the design of an annealing process for determining co-visibility (occlusions, disocclusions) and the degree of regularization to impose on the model. We show that regularization and co-visibility are related via the fitness (residual) of model to data and both can be unified into a single framework to improve the learning process. Our method is an adaptive weighting scheme that guides optimization by measuring the residual at each pixel location over each training step for (i) estimating a soft visibility mask and (ii) determining the amount of regularization. We demonstrate the effectiveness our method by applying it to several recent unsupervised depth completion methods and improving their performance on public benchmark datasets, without incurring additional trainable parameters or increase in inference time. Code available at: https://github.com/alexklwong/adaframe-depth-completion.
Stabilization of generative adversarial networks via noisy scale-space
May 04, 2021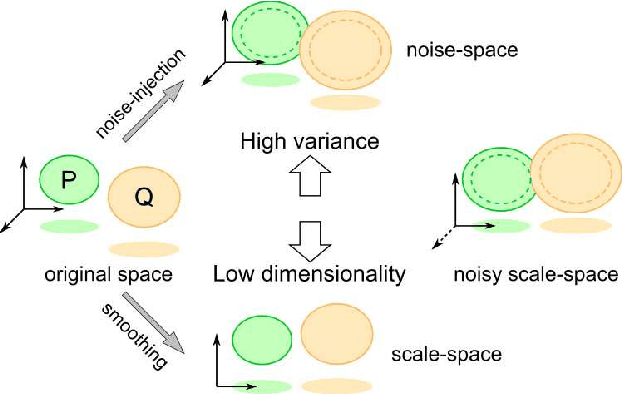
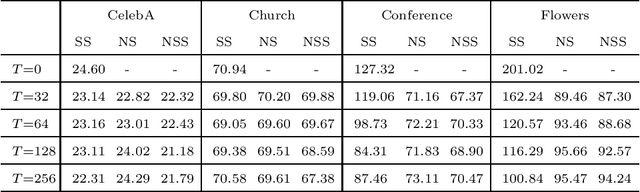

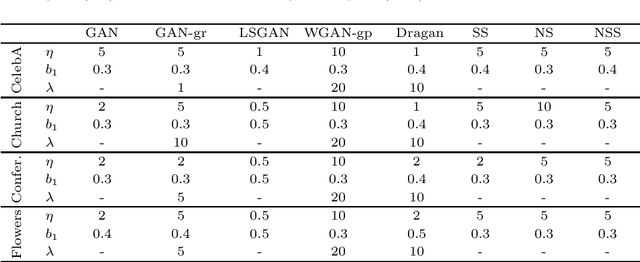
Generative adversarial networks (GAN) is a framework for generating fake data based on given reals but is unstable in the optimization. In order to stabilize GANs, the noise enlarges the overlap of the real and fake distributions at the cost of significant variance. The data smoothing may reduce the dimensionality of data but suppresses the capability of GANs to learn high-frequency information. Based on these observations, we propose a data representation for GANs, called noisy scale-space, that recursively applies the smoothing with noise to data in order to preserve the data variance while replacing high-frequency information by random data, leading to a coarse-to-fine training of GANs. We also present a synthetic data-set using the Hadamard bases that enables us to visualize the true distribution of data. We experiment with a DCGAN with the noise scale-space (NSS-GAN) using major data-sets in which NSS-GAN overtook state-of-the-arts in most cases independent of the image content.
Regularization in neural network optimization via trimmed stochastic gradient descent with noisy label
Dec 21, 2020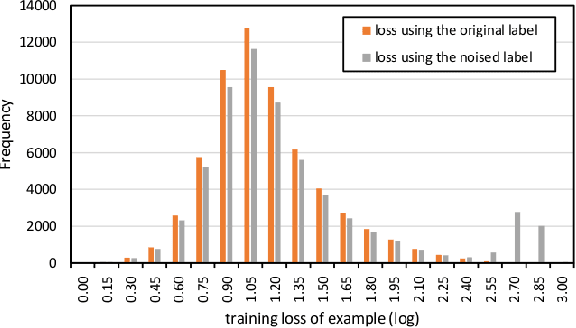
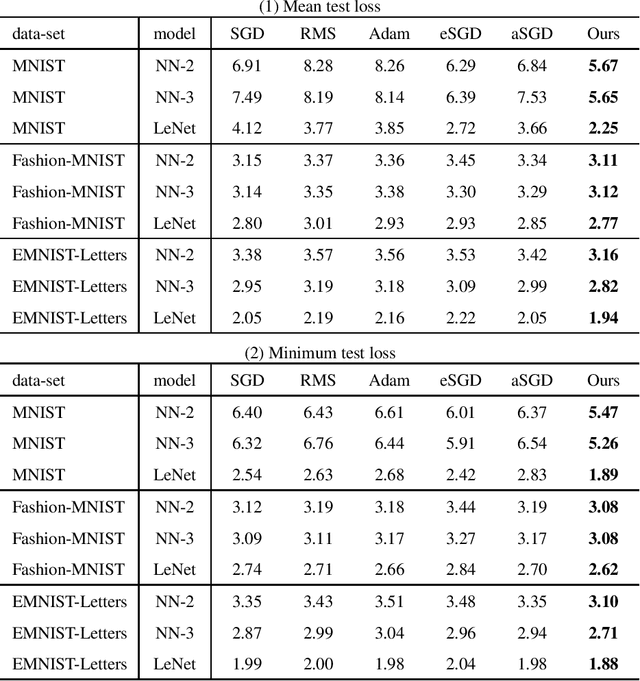
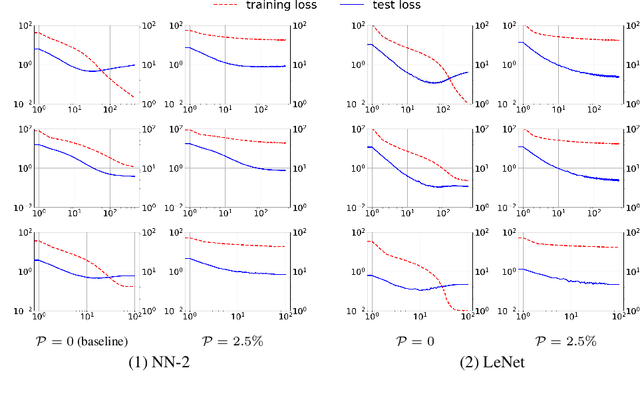
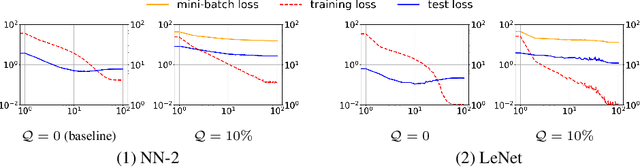
Regularization is essential for avoiding over-fitting to training data in neural network optimization, leading to better generalization of the trained networks. The label noise provides a strong implicit regularization by replacing the target ground truth labels of training examples by uniform random labels. However, it may also cause undesirable misleading gradients due to the large loss associated with incorrect labels. We propose a first-order optimization method (Label-Noised Trim-SGD) which combines the label noise with the example trimming in order to remove the outliers. The proposed algorithm enables us to impose a large label noise and obtain a better regularization effect than the original methods. The quantitative analysis is performed by comparing the behavior of the label noise, the example trimming, and the proposed algorithm. We also present empirical results that demonstrate the effectiveness of our algorithm using the major benchmarks and the fundamental networks, where our method has successfully outperformed the state-of-the-art optimization methods.