 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Human MotionFormer: Transferring Human Motions with Vision Transformers
Feb 22, 2023

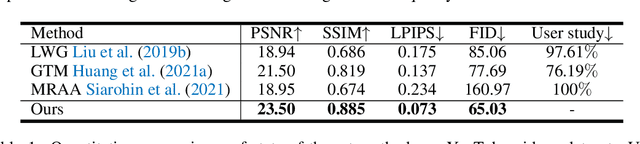
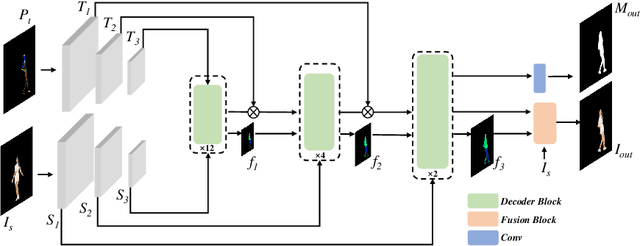
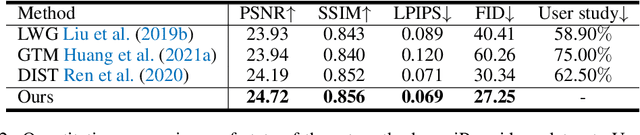
Human motion transfer aims to transfer motions from a target dynamic person to a source static one for motion synthesis. An accurate matching between the source person and the target motion in both large and subtle motion changes is vital for improving the transferred motion quality. In this paper, we propose Human MotionFormer, a hierarchical ViT framework that leverages global and local perceptions to capture large and subtle motion matching, respectively. It consists of two ViT encoders to extract input features (i.e., a target motion image and a source human image) and a ViT decoder with several cascaded blocks for feature matching and motion transfer. In each block, we set the target motion feature as Query and the source person as Key and Value, calculating the cross-attention maps to conduct a global feature matching. Further, we introduce a convolutional layer to improve the local perception after the global cross-attention computations. This matching process is implemented in both warping and generation branches to guide the motion transfer. During training, we propose a mutual learning loss to enable the co-supervision between warping and generation branches for better motion representations. Experiments show that our Human MotionFormer sets the new state-of-the-art performance both qualitatively and quantitatively. Project page: \url{https://github.com/KumapowerLIU/Human-MotionFormer}
Diffusion Denoising for Low-Dose-CT Model
Jan 31, 2023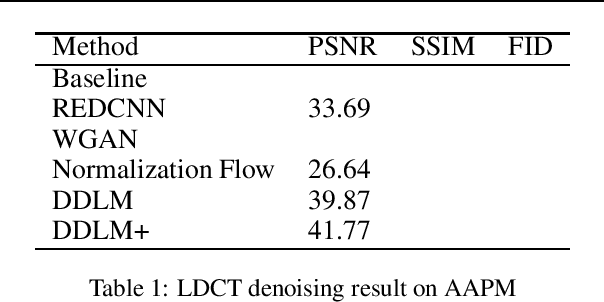

Low-dose Computed Tomography (LDCT) reconstruction is an important task in medical image analysis. Recent years have seen many deep learning based methods, proved to be effective in this area. However, these methods mostly follow a supervised architecture, which needs paired CT image of full dose and quarter dose, and the solution is highly dependent on specific measurements. In this work, we introduce Denoising Diffusion LDCT Model, dubbed as DDLM, generating noise-free CT image using conditioned sampling. DDLM uses pretrained model, and need no training nor tuning process, thus our proposal is in unsupervised manner. Experiments on LDCT images have shown comparable performance of DDLM using less inference time, surpassing other state-of-the-art methods, proving both accurate and efficient. Implementation code will be set to public soon.
Priors are Powerful: Improving a Transformer for Multi-camera 3D Detection with 2D Priors
Jan 31, 2023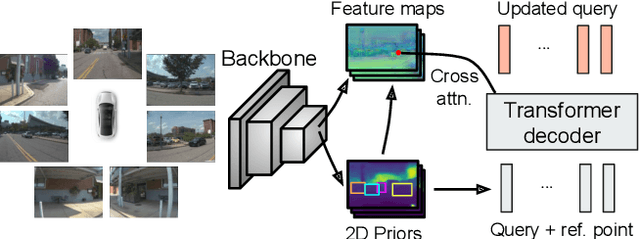
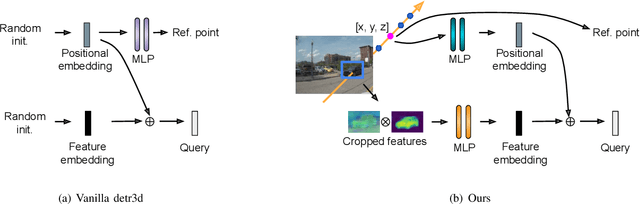
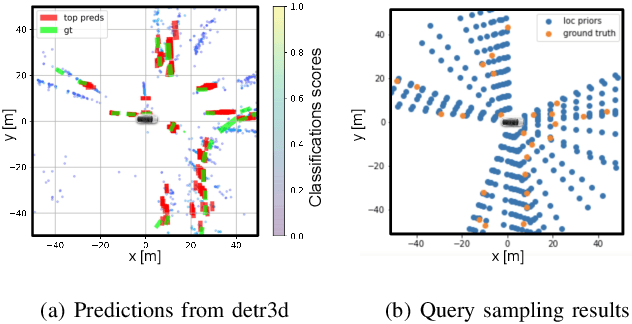
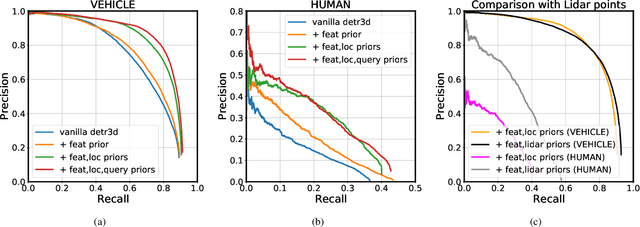
Transfomer-based approaches advance the recent development of multi-camera 3D detection both in academia and industry. In a vanilla transformer architecture, queries are randomly initialised and optimised for the whole dataset, without considering the differences among input frames. In this work, we propose to leverage the predictions from an image backbone, which is often highly optimised for 2D tasks, as priors to the transformer part of a 3D detection network. The method works by (1). augmenting image feature maps with 2D priors, (2). sampling query locations via ray-casting along 2D box centroids, as well as (3). initialising query features with object-level image features. Experimental results shows that 2D priors not only help the model converge faster, but also largely improve the baseline approach by up to 12% in terms of average precision.
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Mar 16, 2023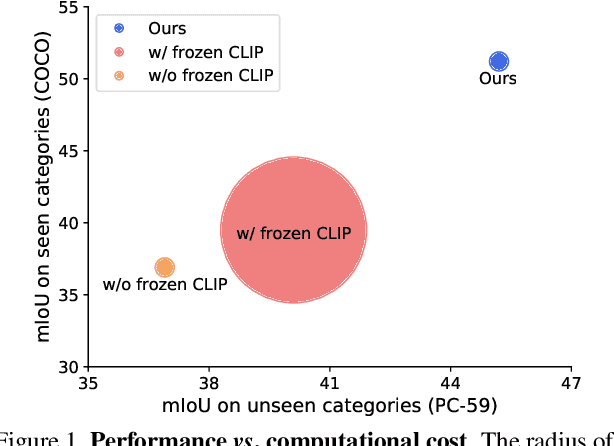
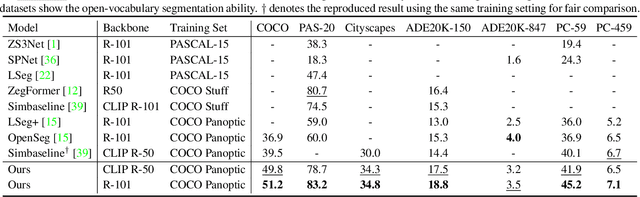
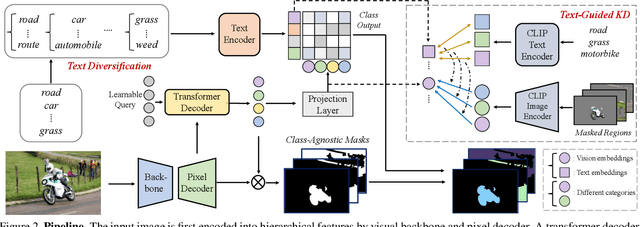

Recent advancements in pre-trained vision-language models, such as CLIP, have enabled the segmentation of arbitrary concepts solely from textual inputs, a process commonly referred to as open-vocabulary semantic segmentation (OVS). However, existing OVS techniques confront a fundamental challenge: the trained classifier tends to overfit on the base classes observed during training, resulting in suboptimal generalization performance to unseen classes. To mitigate this issue, recent studies have proposed the use of an additional frozen pre-trained CLIP for classification. Nonetheless, this approach incurs heavy computational overheads as the CLIP vision encoder must be repeatedly forward-passed for each mask, rendering it impractical for real-world applications. To address this challenge, our objective is to develop a fast OVS model that can perform comparably or better without the extra computational burden of the CLIP image encoder during inference. To this end, we propose a core idea of preserving the generalizable representation when fine-tuning on known classes. Specifically, we introduce a text diversification strategy that generates a set of synonyms for each training category, which prevents the learned representation from collapsing onto specific known category names. Additionally, we employ a text-guided knowledge distillation method to preserve the generalizable knowledge of CLIP. Extensive experiments demonstrate that our proposed model achieves robust generalization performance across various datasets. Furthermore, we perform a preliminary exploration of open-vocabulary video segmentation and present a benchmark that can facilitate future open-vocabulary research in the video domain.
CoLo-CAM: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos
Mar 16, 2023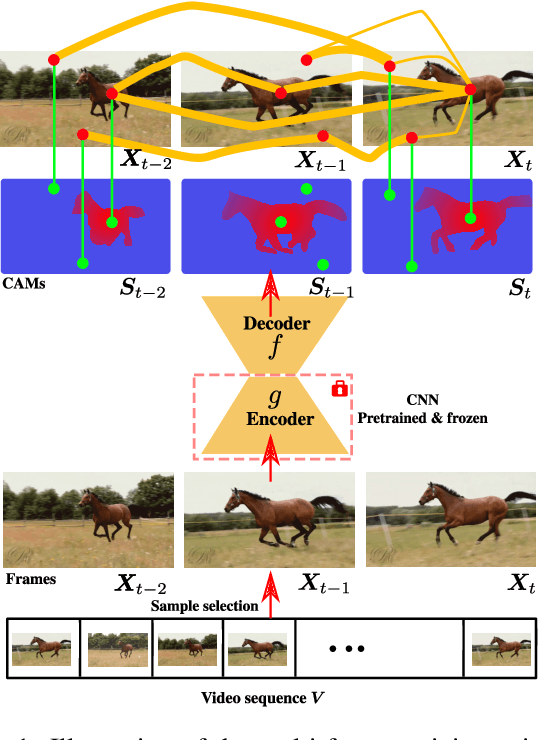
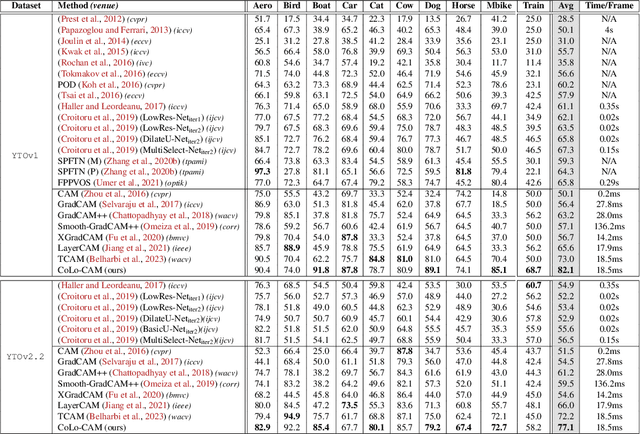
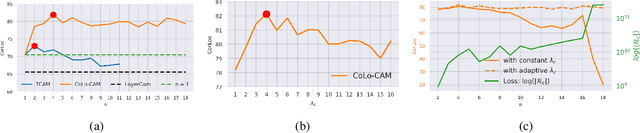

Weakly-supervised video object localization (WSVOL) methods often rely on visual and motion cues only, making them susceptible to inaccurate localization. Recently, discriminative models via a temporal class activation mapping (CAM) method have been explored. Although results are promising, objects are assumed to have minimal movement leading to degradation in performance for relatively long-term dependencies. In this paper, a novel CoLo-CAM method for object localization is proposed to leverage spatiotemporal information in activation maps without any assumptions about object movement. Over a given sequence of frames, explicit joint learning of localization is produced across these maps based on color cues, by assuming an object has similar color across frames. The CAMs' activations are constrained to activate similarly over pixels with similar colors, achieving co-localization. This joint learning creates direct communication among pixels across all image locations, and over all frames, allowing for transfer, aggregation, and correction of learned localization. This is achieved by minimizing a color term of a CRF loss over joint images/maps. In addition to our multi-frame constraint, we impose per-frame local constraints including pseudo-labels, and CRF loss in combination with a global size constraint to improve per-frame localization. Empirical experiments on two challenging datasets for unconstrained videos, YouTube-Objects, show the merits of our method, and its robustness to long-term dependencies, leading to new state-of-the-art localization performance. Public code: https://github.com/sbelharbi/colo-cam.
SSL-Cleanse: Trojan Detection and Mitigation in Self-Supervised Learning
Mar 16, 2023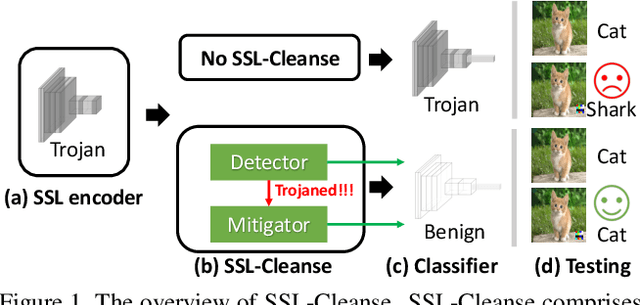
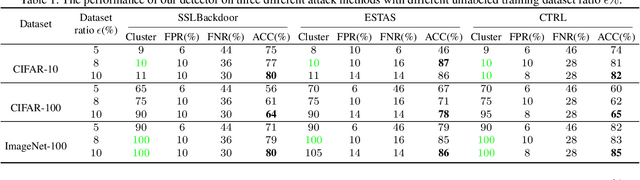


Self-supervised learning (SSL) is a commonly used approach to learning and encoding data representations. By using a pre-trained SSL image encoder and training a downstream classifier on top of it, impressive performance can be achieved on various tasks with very little labeled data. The increasing usage of SSL has led to an uptick in security research related to SSL encoders and the development of various Trojan attacks. The danger posed by Trojan attacks inserted in SSL encoders lies in their ability to operate covertly and spread widely among various users and devices. The presence of backdoor behavior in Trojaned encoders can inadvertently be inherited by downstream classifiers, making it even more difficult to detect and mitigate the threat. Although current Trojan detection methods in supervised learning can potentially safeguard SSL downstream classifiers, identifying and addressing triggers in the SSL encoder before its widespread dissemination is a challenging task. This is because downstream tasks are not always known, dataset labels are not available, and even the original training dataset is not accessible during the SSL encoder Trojan detection. This paper presents an innovative technique called SSL-Cleanse that is designed to detect and mitigate backdoor attacks in SSL encoders. We evaluated SSL-Cleanse on various datasets using 300 models, achieving an average detection success rate of 83.7% on ImageNet-100. After mitigating backdoors, on average, backdoored encoders achieve 0.24% attack success rate without great accuracy loss, proving the effectiveness of SSL-Cleanse.
Optimizing CT Scan Geometries With and Without Gradients
Feb 13, 2023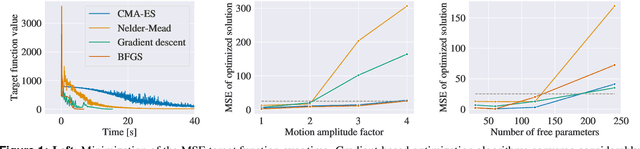

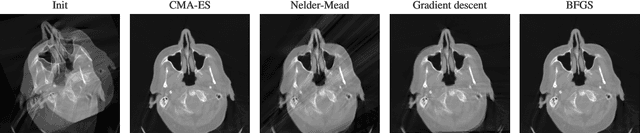
In computed tomography (CT), the projection geometry used for data acquisition needs to be known precisely to obtain a clear reconstructed image. Rigid patient motion is a cause for misalignment between measured data and employed geometry. Commonly, such motion is compensated by solving an optimization problem that, e.g., maximizes the quality of the reconstructed image with respect to the projection geometry. So far, gradient-free optimization algorithms have been utilized to find the solution for this problem. Here, we show that gradient-based optimization algorithms are a possible alternative and compare the performance to their gradient-free counterparts on a benchmark motion compensation problem. Gradient-based algorithms converge substantially faster while being comparable to gradient-free algorithms in terms of capture range and robustness to the number of free parameters. Hence, gradient-based optimization is a viable alternative for the given type of problems.
MuS2: A Benchmark for Sentinel-2 Multi-Image Super-Resolution
Oct 06, 2022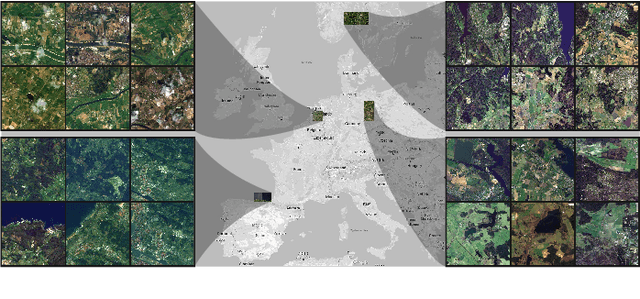
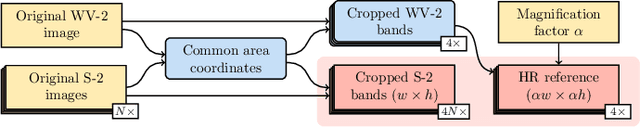


Insufficient spatial resolution of satellite imagery, including Sentinel-2 data, is a serious limitation in many practical use cases. To mitigate this problem, super-resolution reconstruction is receiving considerable attention from the remote sensing community. When it is performed from multiple images captured at subsequent revisits, it may benefit from information fusion, leading to enhanced reconstruction accuracy. One of the obstacles in multi-image super-resolution consists in the scarcity of real-life benchmark datasets -- most of the research was performed for simulated data which do not fully reflect the operating conditions. In this letter, we introduce a new MuS2 benchmark for multi-image super-resolution reconstruction of Sentinel-2 images, with WorldView-2 imagery used as the high-resolution reference. Within MuS2, we publish the first end-to-end evaluation procedure for this problem which we expect to help the researchers in advancing the state of the art in multi-image super-resolution for Sentinel-2 imagery.
DiffeoRaptor: Diffeomorphic Inter-modal Image Registration using RaPTOR
Sep 12, 2022
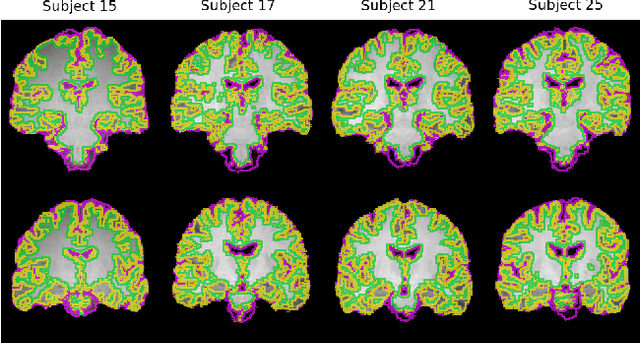
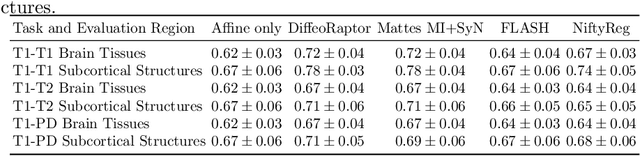
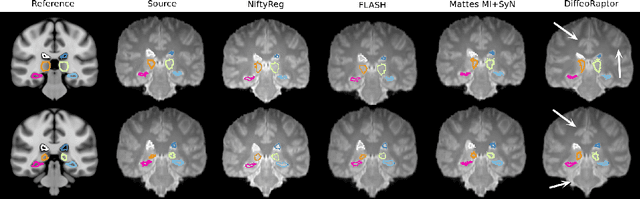
Purpose: Diffeomorphic image registration is essential in many medical imaging applications. Several registration algorithms of such type have been proposed, but primarily for intra-contrast alignment. Currently, efficient inter-modal/contrast diffeomorphic registration, which is vital in numerous applications, remains a challenging task. Methods: We proposed a novel inter-modal/contrast registration algorithm that leverages Robust PaTch-based cOrrelation Ratio (RaPTOR) metric to allow inter-modal/contrast image alignment and bandlimited geodesic shooting demonstrated in Fourier Approximated Lie Algebras (FLASH) algorithm for fast diffeomorphic registration. Results: The proposed algorithm, named DiffeoRaptor, was validated with three public databases for the tasks of brain and abdominal image registration while comparing the results against three state-of-the-art techniques, including FLASH, NiftyReg, and Symmetric image normalization (SyN). Conclusions: Our results demonstrated that DiffeoRaptor offered comparable or better registration performance in terms of registration accuracy. Moreover, DiffeoRaptor produces smoother deformations than SyN in inter-modal and contrast registration. The code for DiffeoRaptor is publicly available at https://github.com/nimamasoumi/DiffeoRaptor.
Ki-67 Index Measurement in Breast Cancer Using Digital Image Analysis
Sep 27, 2022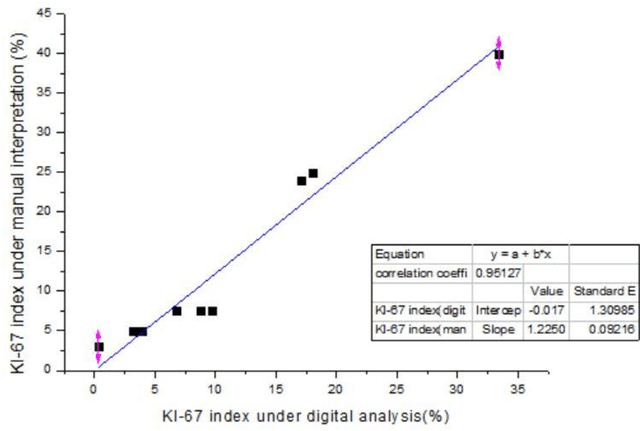
Ki-67 is a nuclear protein that can be produced during cell proliferation. The Ki67 index is a valuable prognostic variable in several kinds of cancer. In breast cancer, the index is even routinely checked in many patients. Currently, pathologists use the immunohistochemistry method to calculate the percentage of Ki-67 positive malignant cells as Ki-67 index. The higher score usually means more aggressive tumor behavior. In clinical practice, the measurement of Ki-67 index relies on visual identifying method and manual counting. However, visual and manual assessment method is timeconsuming and leads to poor reproducibility because of different scoring standards or limited tumor area under assessment. Here, we use digital image processing technics including image binarization and image morphological operations to create a digital image analysis method to interpretate Ki-67 index. Then, 10 breast cancer specimens are used as validation with high accuracy (correlation efficiency r = 0.95127). With the assistance of digital image analysis, pathologists can interpretate the Ki67 index more efficiently, precisely with excellent reproducibility.