 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART$^3$: Leveraging Distance for Test Time Adaptation in Person Re-Identification
May 23, 2025Person re-identification (ReID) models are known to suffer from camera bias, where learned representations cluster according to camera viewpoints rather than identity, leading to significant performance degradation under (inter-camera) domain shifts in real-world surveillance systems when new cameras are added to camera networks. State-of-the-art test-time adaptation (TTA) methods, largely designed for classification tasks, rely on classification entropy-based objectives that fail to generalize well to ReID, thus making them unsuitable for tackling camera bias. In this paper, we introduce DART$^3$, a TTA framework specifically designed to mitigate camera-induced domain shifts in person ReID. DART$^3$ (Distance-Aware Retrieval Tuning at Test Time) leverages a distance-based objective that aligns better with image retrieval tasks like ReID by exploiting the correlation between nearest-neighbor distance and prediction error. Unlike prior ReID-specific domain adaptation methods, DART$^3$ requires no source data, architectural modifications, or retraining, and can be deployed in both fully black-box and hybrid settings. Empirical evaluations on multiple ReID benchmarks indicate that DART$^3$ and DART$^3$ LITE, a lightweight alternative to the approach, consistently outperforms state-of-the-art TTA baselines, making for a viable option to online learning to mitigate the adverse effects of camera bias.
Leveraging Transformers for Weakly Supervised Object Localization in Unconstrained Videos
Jul 08, 2024



Weakly-Supervised Video Object Localization (WSVOL) involves localizing an object in videos using only video-level labels, also referred to as tags. State-of-the-art WSVOL methods like Temporal CAM (TCAM) rely on class activation mapping (CAM) and typically require a pre-trained CNN classifier. However, their localization accuracy is affected by their tendency to minimize the mutual information between different instances of a class and exploit temporal information during training for downstream tasks, e.g., detection and tracking. In the absence of bounding box annotation, it is challenging to exploit precise information about objects from temporal cues because the model struggles to locate objects over time. To address these issues, a novel method called transformer based CAM for videos (TrCAM-V), is proposed for WSVOL. It consists of a DeiT backbone with two heads for classification and localization. The classification head is trained using standard classification loss (CL), while the localization head is trained using pseudo-labels that are extracted using a pre-trained CLIP model. From these pseudo-labels, the high and low activation values are considered to be foreground and background regions, respectively. Our TrCAM-V method allows training a localization network by sampling pseudo-pixels on the fly from these regions. Additionally, a conditional random field (CRF) loss is employed to align the object boundaries with the foreground map. During inference, the model can process individual frames for real-time localization applications. Extensive experiments on challenging YouTube-Objects unconstrained video datasets show that our TrCAM-V method achieves new state-of-the-art performance in terms of classification and localization accuracy.
SR-CACO-2: A Dataset for Confocal Fluorescence Microscopy Image Super-Resolution
Jun 13, 2024



Confocal fluorescence microscopy is one of the most accessible and widely used imaging techniques for the study of biological processes. Scanning confocal microscopy allows the capture of high-quality images from 3D samples, yet suffers from well-known limitations such as photobleaching and phototoxicity of specimens caused by intense light exposure, which limits its use in some applications, especially for living cells. Cellular damage can be alleviated by changing imaging parameters to reduce light exposure, often at the expense of image quality. Machine/deep learning methods for single-image super-resolution (SISR) can be applied to restore image quality by upscaling lower-resolution (LR) images to produce high-resolution images (HR). These SISR methods have been successfully applied to photo-realistic images due partly to the abundance of publicly available data. In contrast, the lack of publicly available data partly limits their application and success in scanning confocal microscopy. In this paper, we introduce a large scanning confocal microscopy dataset named SR-CACO-2 that is comprised of low- and high-resolution image pairs marked for three different fluorescent markers. It allows the evaluation of performance of SISR methods on three different upscaling levels (X2, X4, X8). SR-CACO-2 contains the human epithelial cell line Caco-2 (ATCC HTB-37), and it is composed of 22 tiles that have been translated in the form of 9,937 image patches for experiments with SISR methods. Given the new SR-CACO-2 dataset, we also provide benchmarking results for 15 state-of-the-art methods that are representative of the main SISR families. Results show that these methods have limited success in producing high-resolution textures, indicating that SR-CACO-2 represents a challenging problem. Our dataset, code and pretrained weights are available: https://github.com/sbelharbi/sr-caco-2.
Source-Free Domain Adaptation of Weakly-Supervised Object Localization Models for Histology
Apr 29, 2024Given the emergence of deep learning, digital pathology has gained popularity for cancer diagnosis based on histology images. Deep weakly supervised object localization (WSOL) models can be trained to classify histology images according to cancer grade and identify regions of interest (ROIs) for interpretation, using inexpensive global image-class annotations. A WSOL model initially trained on some labeled source image data can be adapted using unlabeled target data in cases of significant domain shifts caused by variations in staining, scanners, and cancer type. In this paper, we focus on source-free (unsupervised) domain adaptation (SFDA), a challenging problem where a pre-trained source model is adapted to a new target domain without using any source domain data for privacy and efficiency reasons. SFDA of WSOL models raises several challenges in histology, most notably because they are not intended to adapt for both classification and localization tasks. In this paper, 4 state-of-the-art SFDA methods, each one representative of a main SFDA family, are compared for WSOL in terms of classification and localization accuracy. They are the SFDA-Distribution Estimation, Source HypOthesis Transfer, Cross-Domain Contrastive Learning, and Adaptively Domain Statistics Alignment. Experimental results on the challenging Glas (smaller, breast cancer) and Camelyon16 (larger, colon cancer) histology datasets indicate that these SFDA methods typically perform poorly for localization after adaptation when optimized for classification.
Realistic Model Selection for Weakly Supervised Object Localization
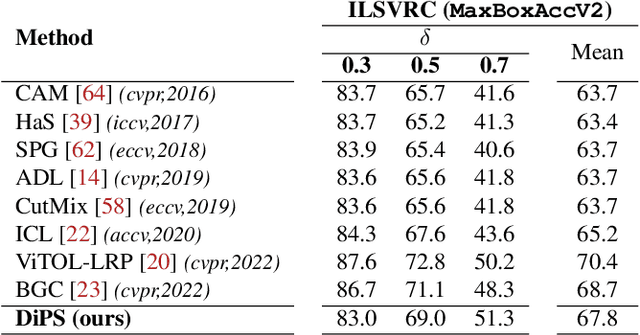
Apr 15, 2024Weakly Supervised Object Localization (WSOL) allows for training deep learning models for classification and localization, using only global class-level labels. The lack of bounding box (bbox) supervision during training represents a considerable challenge for hyper-parameter search and model selection. Earlier WSOL works implicitly observed localization performance over a test set which leads to biased performance evaluation. More recently, a better WSOL protocol has been proposed, where a validation set with bbox annotations is held out for model selection. Although it does not rely on the test set, this protocol is unrealistic since bboxes are not available in real-world applications, and when available, it is better to use them directly to fit model weights. Our initial empirical analysis shows that the localization performance of a model declines significantly when using only image-class labels for model selection (compared to using bounding-box annotations). This suggests that adding bounding-box labels is preferable for selecting the best model for localization. In this paper, we introduce a new WSOL validation protocol that provides a localization signal without the need for manual bbox annotations. In particular, we leverage noisy pseudo boxes from an off-the-shelf ROI proposal generator such as Selective-Search, CLIP, and RPN pretrained models for model selection. Our experimental results with several WSOL methods on ILSVRC and CUB-200-2011 datasets show that our noisy boxes allow selecting models with performance close to those selected using ground truth boxes, and better than models selected using only image-class labels.
DiPS: Discriminative Pseudo-Label Sampling with Self-Supervised Transformers for Weakly Supervised Object Localization
Oct 19, 2023



Self-supervised vision transformers (SSTs) have shown great potential to yield rich localization maps that highlight different objects in an image. However, these maps remain class-agnostic since the model is unsupervised. They often tend to decompose the image into multiple maps containing different objects while being unable to distinguish the object of interest from background noise objects. In this paper, Discriminative Pseudo-label Sampling (DiPS) is introduced to leverage these class-agnostic maps for weakly-supervised object localization (WSOL), where only image-class labels are available. Given multiple attention maps, DiPS relies on a pre-trained classifier to identify the most discriminative regions of each attention map. This ensures that the selected ROIs cover the correct image object while discarding the background ones, and, as such, provides a rich pool of diverse and discriminative proposals to cover different parts of the object. Subsequently, these proposals are used as pseudo-labels to train our new transformer-based WSOL model designed to perform classification and localization tasks. Unlike standard WSOL methods, DiPS optimizes performance in both tasks by using a transformer encoder and a dedicated output head for each task, each trained using dedicated loss functions. To avoid overfitting a single proposal and promote better object coverage, a single proposal is randomly selected among the top ones for a training image at each training step. Experimental results on the challenging CUB, ILSVRC, OpenImages, and TelDrone datasets indicate that our architecture, in combination with our transformer-based proposals, can yield better localization performance than state-of-the-art methods.
CoLo-CAM: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos
Mar 16, 2023Weakly-supervised video object localization (WSVOL) methods often rely on visual and motion cues only, making them susceptible to inaccurate localization. Recently, discriminative models via a temporal class activation mapping (CAM) method have been explored. Although results are promising, objects are assumed to have minimal movement leading to degradation in performance for relatively long-term dependencies. In this paper, a novel CoLo-CAM method for object localization is proposed to leverage spatiotemporal information in activation maps without any assumptions about object movement. Over a given sequence of frames, explicit joint learning of localization is produced across these maps based on color cues, by assuming an object has similar color across frames. The CAMs' activations are constrained to activate similarly over pixels with similar colors, achieving co-localization. This joint learning creates direct communication among pixels across all image locations, and over all frames, allowing for transfer, aggregation, and correction of learned localization. This is achieved by minimizing a color term of a CRF loss over joint images/maps. In addition to our multi-frame constraint, we impose per-frame local constraints including pseudo-labels, and CRF loss in combination with a global size constraint to improve per-frame localization. Empirical experiments on two challenging datasets for unconstrained videos, YouTube-Objects, show the merits of our method, and its robustness to long-term dependencies, leading to new state-of-the-art localization performance. Public code: https://github.com/sbelharbi/colo-cam.
Counterfactual Explanation and Instance-Generation using Cycle-Consistent Generative Adversarial Networks
Jan 21, 2023



The image-based diagnosis is now a vital aspect of modern automation assisted diagnosis. To enable models to produce pixel-level diagnosis, pixel-level ground-truth labels are essentially required. However, since it is often not straight forward to obtain the labels in many application domains such as in medical image, classification-based approaches have become the de facto standard to perform the diagnosis. Though they can identify class-salient regions, they may not be useful for diagnosis where capturing all of the evidences is important requirement. Alternatively, a counterfactual explanation (CX) aims at providing explanations using a casual reasoning process of form "If X has not happend, Y would not heppend". Existing CX approaches, however, use classifier to explain features that can change its predictions. Thus, they can only explain class-salient features, rather than entire object of interest. This hence motivates us to propose a novel CX strategy that is not reliant on image classification. This work is inspired from the recent developments in generative adversarial networks (GANs) based image-to-image domain translation, and leverages to translate an abnormal image to counterpart normal image (i.e. counterfactual instance CI) to find discrepancy maps between the two. Since it is generally not possible to obtain abnormal and normal image pairs, we leverage Cycle-Consistency principle (a.k.a CycleGAN) to perform the translation in unsupervised way. We formulate CX in terms of a discrepancy map that, when added from the abnormal image, will make it indistinguishable from the CI. We evaluate our method on three datasets including a synthetic, tuberculosis and BraTS dataset. All these experiments confirm the supremacy of propose method in generating accurate CX and CI.
Constrained Sampling for Class-Agnostic Weakly Supervised Object Localization
Sep 09, 2022
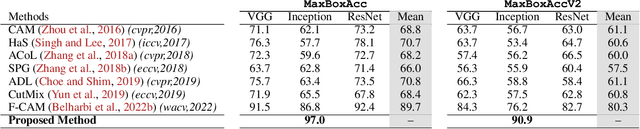
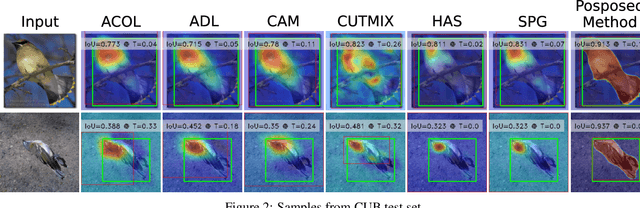
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new discriminative proposals sampling method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB benchmark dataset indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. Our method provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization
Sep 09, 2022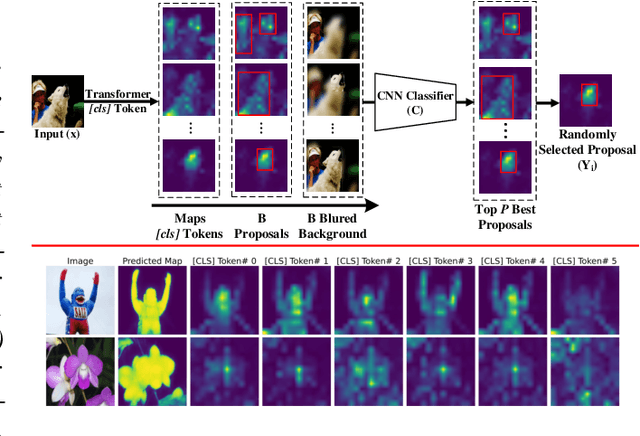
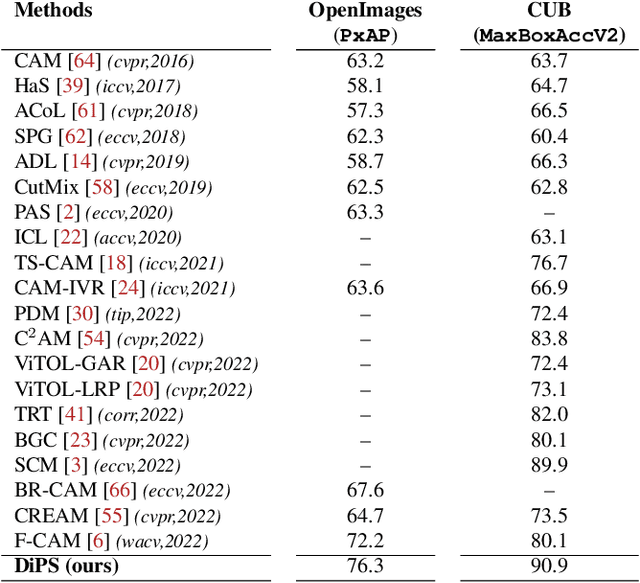
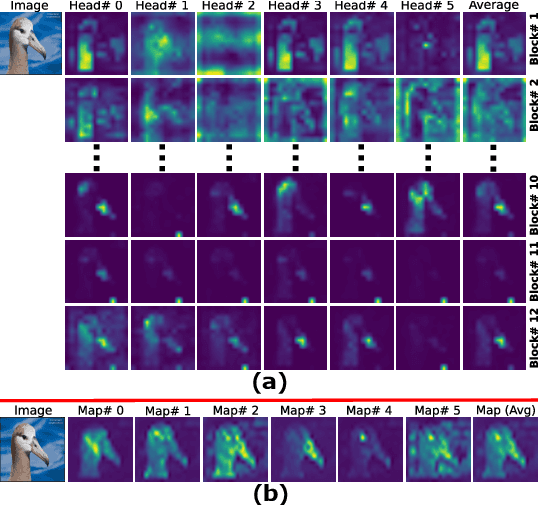
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new Discriminative Proposals Sampling (DiPS) method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB, OpenImages, and ILSVRC benchmark datasets indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. DiPS provides class activation maps with a better coverage of foreground object regions w.r.t. the background.