 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Handheld Burst Super-Resolution Meets Multi-Exposure Satellite Imagery
Mar 10, 2023
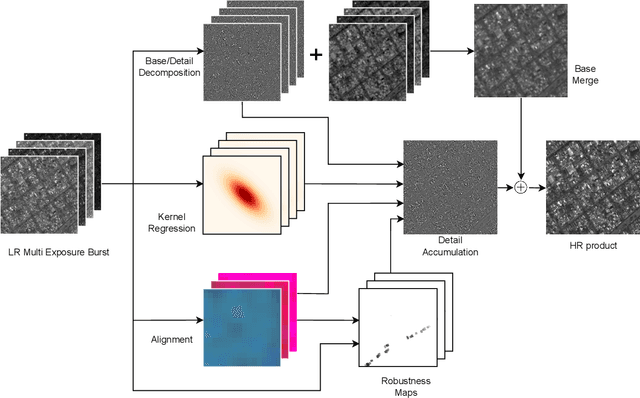
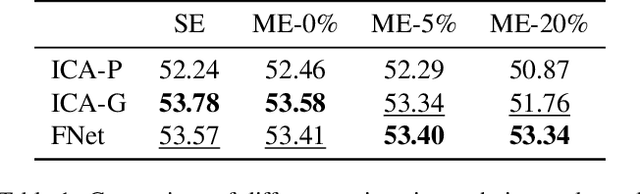
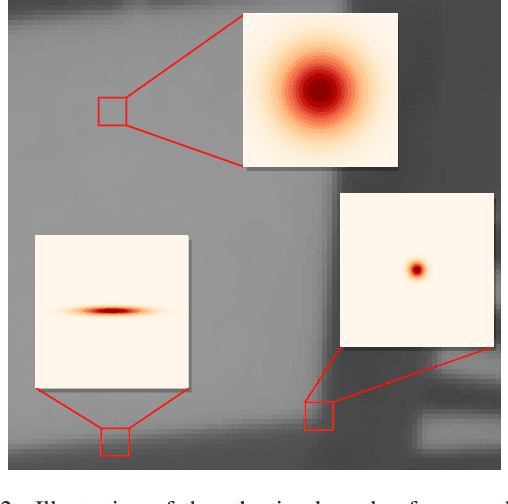
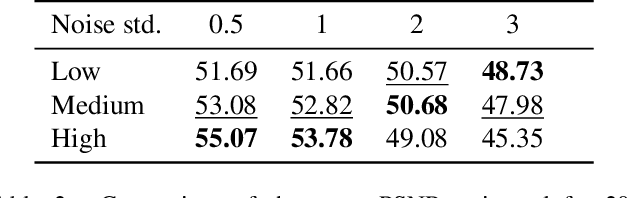
Image resolution is an important criterion for many applications based on satellite imagery. In this work, we adapt a state-of-the-art kernel regression technique for smartphone camera burst super-resolution to satellites. This technique leverages the local structure of the image to optimally steer the fusion kernels, limiting blur in the final high-resolution prediction, denoising the image, and recovering details up to a zoom factor of 2. We extend this approach to the multi-exposure case to predict from a sequence of multi-exposure low-resolution frames a high-resolution and noise-free one. Experiments on both single and multi-exposure scenarios show the merits of the approach. Since the fusion is learning-free, the proposed method is ensured to not hallucinate details, which is crucial for many remote sensing applications.
On the impact of incorporating task-information in learning-based image denoising
Nov 23, 2022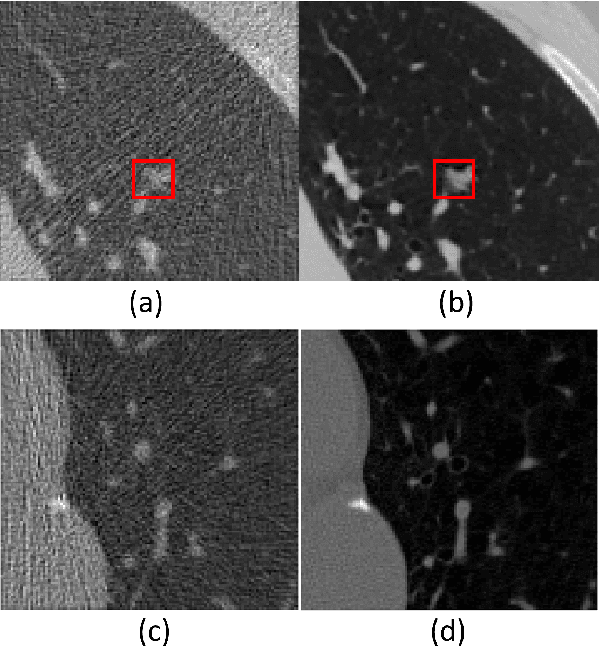
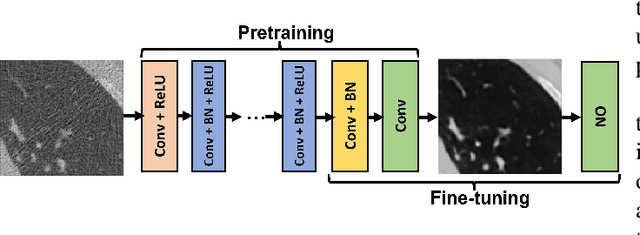
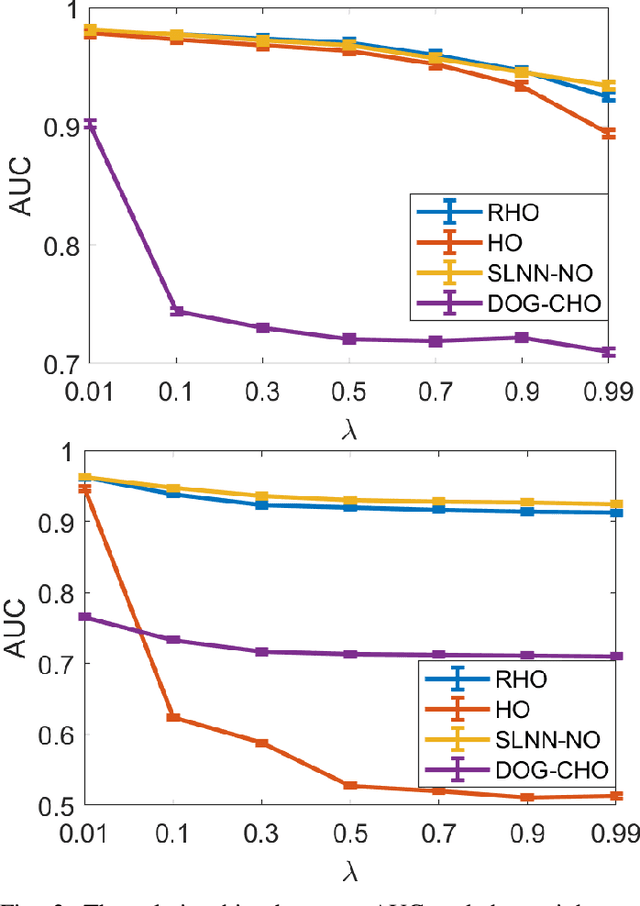
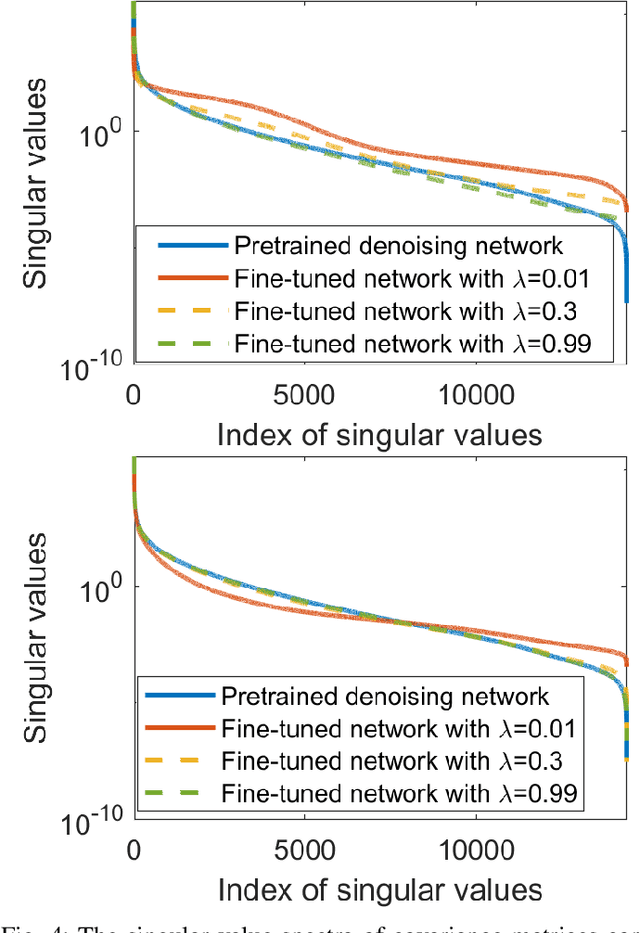
A variety of deep neural network (DNN)-based image denoising methods have been proposed for use with medical images. These methods are typically trained by minimizing loss functions that quantify a distance between the denoised image, or a transformed version of it, and the defined target image (e.g., a noise-free or low-noise image). They have demonstrated high performance in terms of traditional image quality metrics such as root mean square error (RMSE), structural similarity index measure (SSIM), or peak signal-to-noise ratio (PSNR). However, it has been reported recently that such denoising methods may not always improve objective measures of image quality. In this work, a task-informed DNN-based image denoising method was established and systematically evaluated. A transfer learning approach was employed, in which the DNN is first pre-trained by use of a conventional (non-task-informed) loss function and subsequently fine-tuned by use of the hybrid loss that includes a task-component. The task-component was designed to measure the performance of a numerical observer (NO) on a signal detection task. The impact of network depth and constraining the fine-tuning to specific layers of the DNN was explored. The task-informed training method was investigated in a stylized low-dose X-ray computed tomography (CT) denoising study for which binary signal detection tasks under signal-known-statistically (SKS) with background-known-statistically (BKS) conditions were considered. The impact of changing the specified task at inference time to be different from that employed for model training, a phenomenon we refer to as "task-shift", was also investigated. The presented results indicate that the task-informed training method can improve observer performance while providing control over the trade off between traditional and task-based measures of image quality.
Making Thermal Imaging More Equitable and Accurate: Resolving Solar Loading Biases
Apr 18, 2023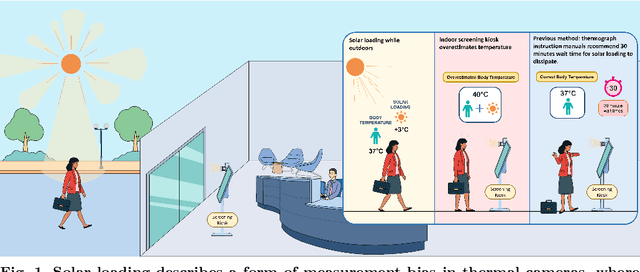
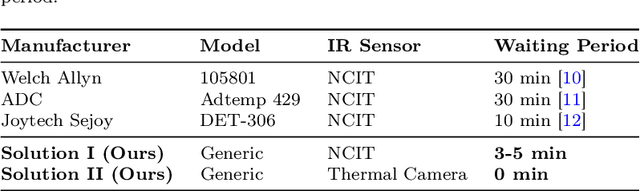
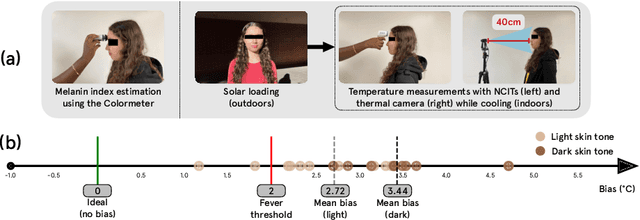

Thermal cameras and thermal point detectors are used to measure the temperature of human skin. These are important devices that are used everyday in clinical and mass screening settings, particularly in an epidemic. Unfortunately, despite the wide use of thermal sensors, the temperature estimates from thermal sensors do not work well in uncontrolled scene conditions. Previous work has studied the effect of wind and other environment factors on skin temperature, but has not considered the heating effect from sunlight, which is termed solar loading. Existing device manufacturers recommend that a subject who has been outdoors in sun re-acclimate to an indoor environment after a waiting period. The waiting period, up to 30 minutes, is insufficient for a rapid screening tool. Moreover, the error bias from solar loading is greater for darker skin tones since melanin absorbs solar radiation. This paper explores two approaches to address this problem. The first approach uses transient behavior of cooling to more quickly extrapolate the steady state temperature. A second approach explores the spatial modulation of solar loading, to propose single-shot correction with a wide-field thermal camera. A real world dataset comprising of thermal point, thermal image, subjective, and objective measurements of melanin is collected with statistical significance for the effect size observed. The single-shot correction scheme is shown to eliminate solar loading bias in the time of a typical frame exposure (33ms).
GUILGET: GUI Layout GEneration with Transformer
Apr 18, 2023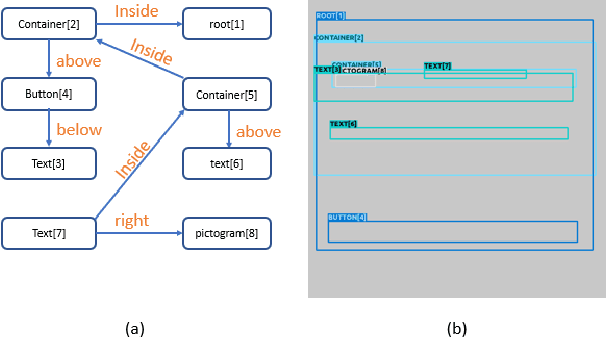

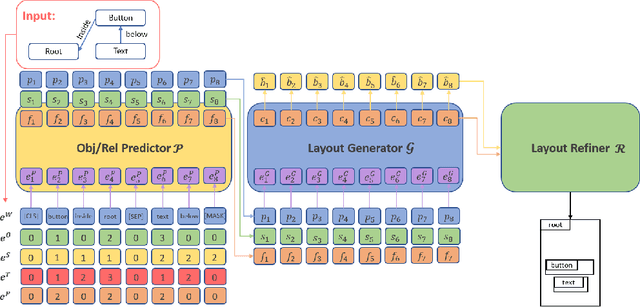
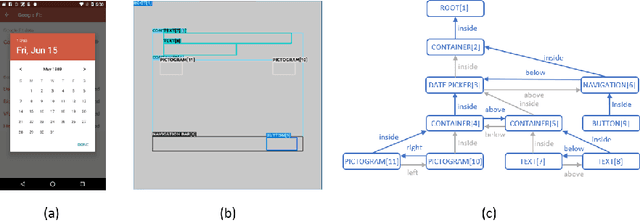
Sketching out Graphical User Interface (GUI) layout is part of the pipeline of designing a GUI and a crucial task for the success of a software application. Arranging all components inside a GUI layout manually is a time-consuming task. In order to assist designers, we developed a method named GUILGET to automatically generate GUI layouts from positional constraints represented as GUI arrangement graphs (GUI-AGs). The goal is to support the initial step of GUI design by producing realistic and diverse GUI layouts. The existing image layout generation techniques often cannot incorporate GUI design constraints. Thus, GUILGET needs to adapt existing techniques to generate GUI layouts that obey to constraints specific to GUI designs. GUILGET is based on transformers in order to capture the semantic in relationships between elements from GUI-AG. Moreover, the model learns constraints through the minimization of losses responsible for placing each component inside its parent layout, for not letting components overlap if they are inside the same parent, and for component alignment. Our experiments, which are conducted on the CLAY dataset, reveal that our model has the best understanding of relationships from GUI-AG and has the best performances in most of evaluation metrics. Therefore, our work contributes to improved GUI layout generation by proposing a novel method that effectively accounts for the constraints on GUI elements and paves the road for a more efficient GUI design pipeline.
BEVSimDet: Simulated Multi-modal Distillation in Bird's-Eye View for Multi-view 3D Object Detection
Apr 15, 2023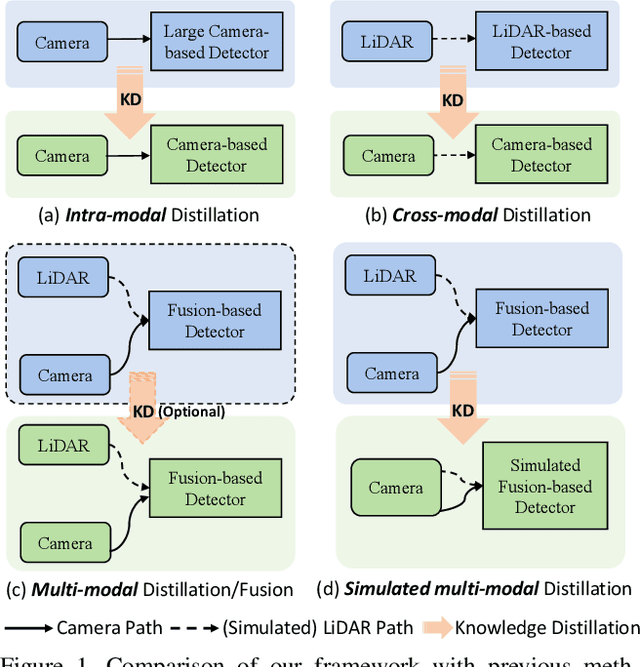
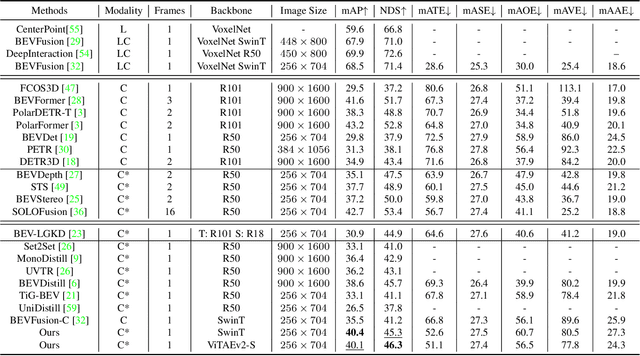
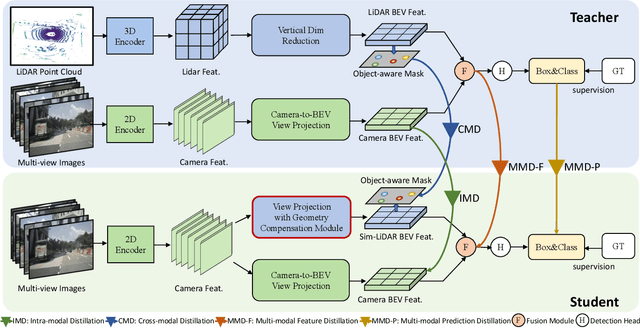
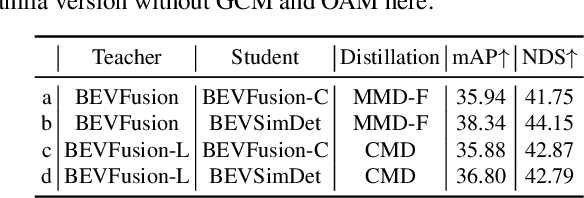
Multi-view camera-based 3D object detection has gained popularity due to its low cost. But accurately inferring 3D geometry solely from camera data remains challenging, which impacts model performance. One promising approach to address this issue is to distill precise 3D geometry knowledge from LiDAR data. However, transferring knowledge between different sensor modalities is hindered by the significant modality gap. In this paper, we approach this challenge from the perspective of both architecture design and knowledge distillation and present a new simulated multi-modal 3D object detection method named BEVSimDet. We first introduce a novel framework that includes a LiDAR and camera fusion-based teacher and a simulated multi-modal student, where the student simulates multi-modal features with image-only input. To facilitate effective distillation, we propose a simulated multi-modal distillation scheme that supports intra-modal, cross-modal, and multi-modal distillation simultaneously, in Bird's-eye-view (BEV) space. By combining them together, BEVSimDet can learn better feature representations for 3D object detection while enjoying cost-effective camera-only deployment. Experimental results on the challenging nuScenes benchmark demonstrate the effectiveness and superiority of BEVSimDet over recent representative methods. The source code will be released at \href{https://github.com/ViTAE-Transformer/BEVSimDet}{BEVSimDet}.
Detecting Out-of-Context Multimodal Misinformation with interpretable neural-symbolic model
Apr 15, 2023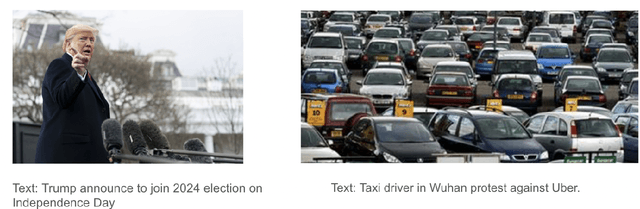
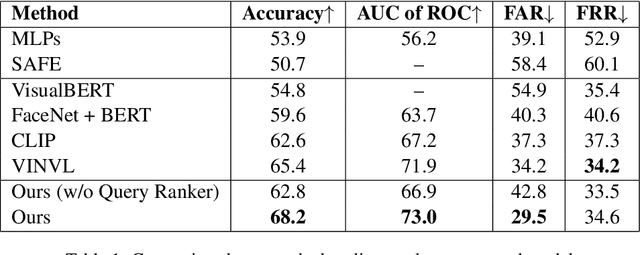
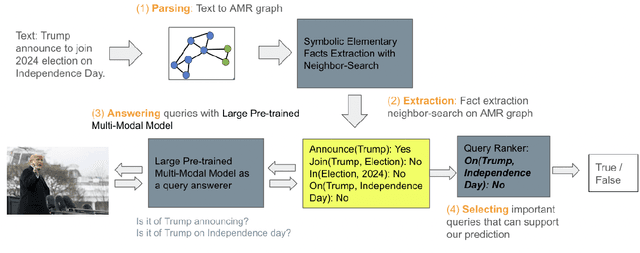
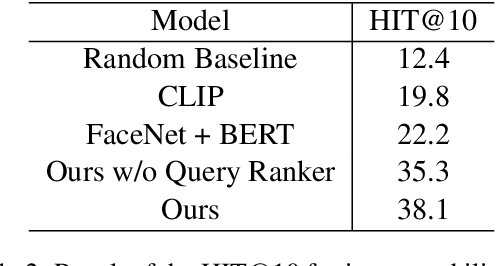
Recent years have witnessed the sustained evolution of misinformation that aims at manipulating public opinions. Unlike traditional rumors or fake news editors who mainly rely on generated and/or counterfeited images, text and videos, current misinformation creators now more tend to use out-of-context multimedia contents (e.g. mismatched images and captions) to deceive the public and fake news detection systems. This new type of misinformation increases the difficulty of not only detection but also clarification, because every individual modality is close enough to true information. To address this challenge, in this paper we explore how to achieve interpretable cross-modal de-contextualization detection that simultaneously identifies the mismatched pairs and the cross-modal contradictions, which is helpful for fact-check websites to document clarifications. The proposed model first symbolically disassembles the text-modality information to a set of fact queries based on the Abstract Meaning Representation of the caption and then forwards the query-image pairs into a pre-trained large vision-language model select the ``evidences" that are helpful for us to detect misinformation. Extensive experiments indicate that the proposed methodology can provide us with much more interpretable predictions while maintaining the accuracy same as the state-of-the-art model on this task.
Robust One-shot Segmentation of Brain Tissues via Image-aligned Style Transformation
Nov 30, 2022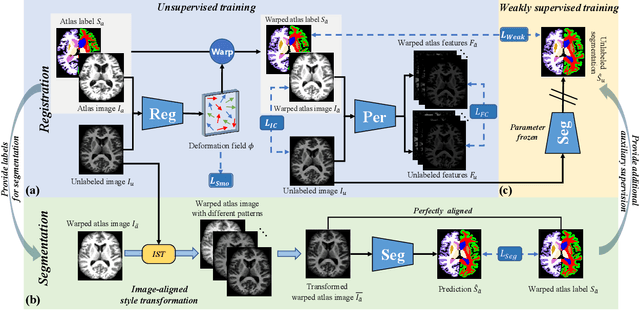
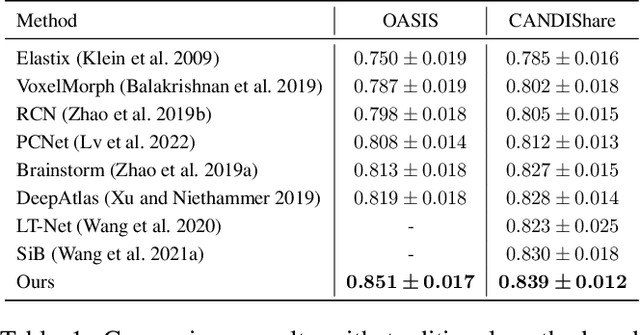
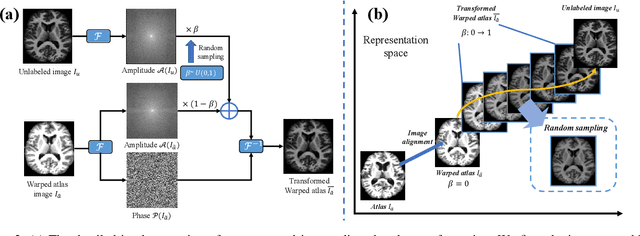
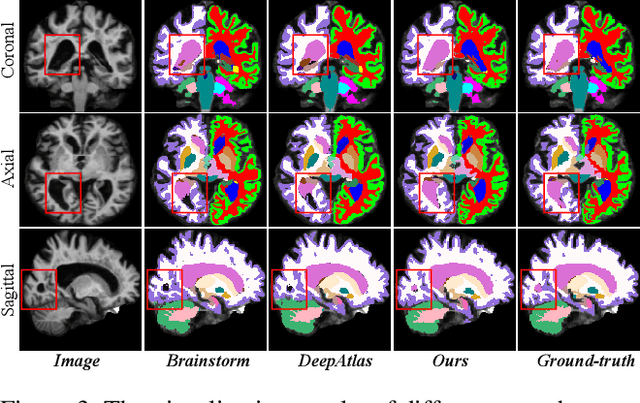
One-shot segmentation of brain tissues is typically a dual-model iterative learning: a registration model (reg-model) warps a carefully-labeled atlas onto unlabeled images to initialize their pseudo masks for training a segmentation model (seg-model); the seg-model revises the pseudo masks to enhance the reg-model for a better warping in the next iteration. However, there is a key weakness in such dual-model iteration that the spatial misalignment inevitably caused by the reg-model could misguide the seg-model, which makes it converge on an inferior segmentation performance eventually. In this paper, we propose a novel image-aligned style transformation to reinforce the dual-model iterative learning for robust one-shot segmentation of brain tissues. Specifically, we first utilize the reg-model to warp the atlas onto an unlabeled image, and then employ the Fourier-based amplitude exchange with perturbation to transplant the style of the unlabeled image into the aligned atlas. This allows the subsequent seg-model to learn on the aligned and style-transferred copies of the atlas instead of unlabeled images, which naturally guarantees the correct spatial correspondence of an image-mask training pair, without sacrificing the diversity of intensity patterns carried by the unlabeled images. Furthermore, we introduce a feature-aware content consistency in addition to the image-level similarity to constrain the reg-model for a promising initialization, which avoids the collapse of image-aligned style transformation in the first iteration. Experimental results on two public datasets demonstrate 1) a competitive segmentation performance of our method compared to the fully-supervised method, and 2) a superior performance over other state-of-the-art with an increase of average Dice by up to 4.67%. The source code is available at: https://github.com/JinxLv/One-shot-segmentation-via-IST.
Discovering Interpretable Directions in the Semantic Latent Space of Diffusion Models
Mar 20, 2023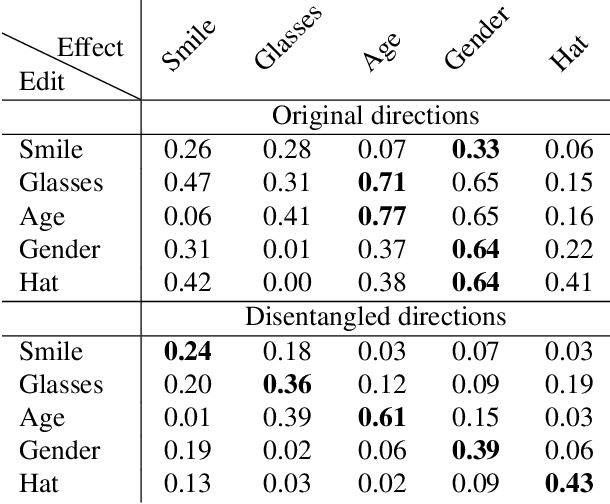
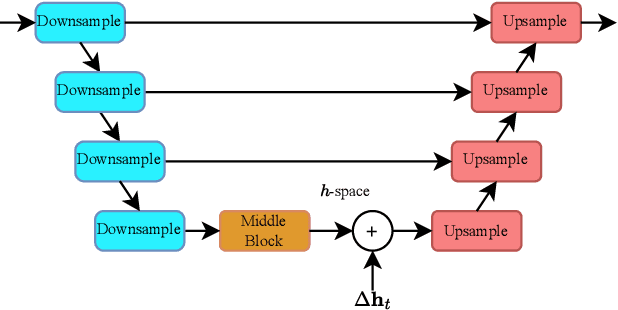


Denoising Diffusion Models (DDMs) have emerged as a strong competitor to Generative Adversarial Networks (GANs). However, despite their widespread use in image synthesis and editing applications, their latent space is still not as well understood. Recently, a semantic latent space for DDMs, coined `$h$-space', was shown to facilitate semantic image editing in a way reminiscent of GANs. The $h$-space is comprised of the bottleneck activations in the DDM's denoiser across all timesteps of the diffusion process. In this paper, we explore the properties of h-space and propose several novel methods for finding meaningful semantic directions within it. We start by studying unsupervised methods for revealing interpretable semantic directions in pretrained DDMs. Specifically, we show that global latent directions emerge as the principal components in the latent space. Additionally, we provide a novel method for discovering image-specific semantic directions by spectral analysis of the Jacobian of the denoiser w.r.t. the latent code. Next, we extend the analysis by finding directions in a supervised fashion in unconditional DDMs. We demonstrate how such directions can be found by relying on either a labeled data set of real images or by annotating generated samples with a domain-specific attribute classifier. We further show how to semantically disentangle the found direction by simple linear projection. Our approaches are applicable without requiring any architectural modifications, text-based guidance, CLIP-based optimization, or model fine-tuning.
Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Dec 13, 2022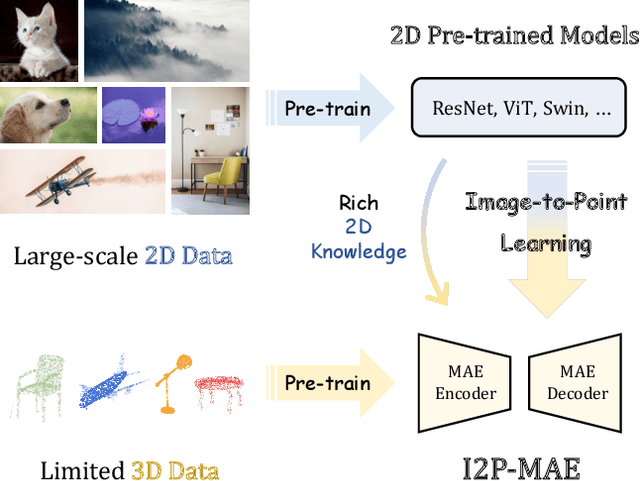
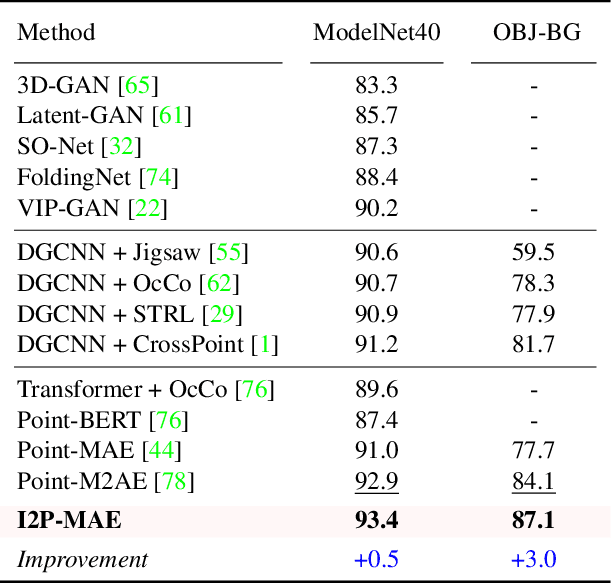
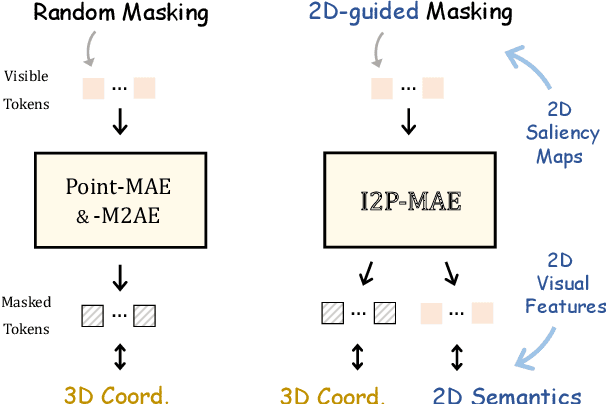
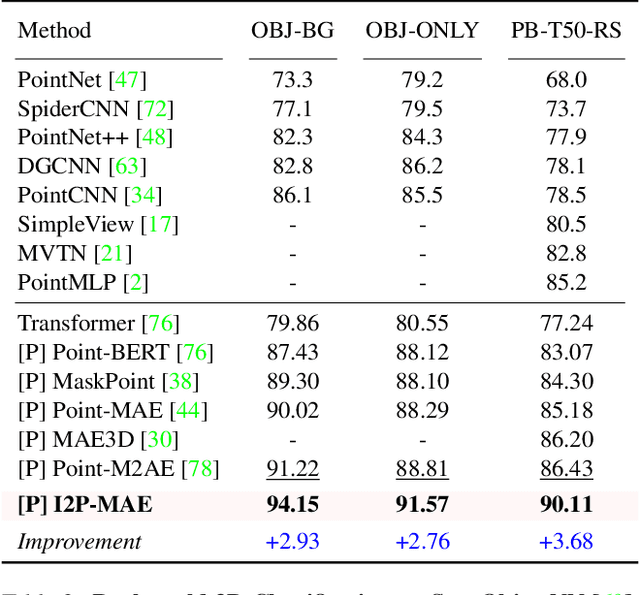
Pre-training by numerous image data has become de-facto for robust 2D representations. In contrast, due to the expensive data acquisition and annotation, a paucity of large-scale 3D datasets severely hinders the learning for high-quality 3D features. In this paper, we propose an alternative to obtain superior 3D representations from 2D pre-trained models via Image-to-Point Masked Autoencoders, named as I2P-MAE. By self-supervised pre-training, we leverage the well learned 2D knowledge to guide 3D masked autoencoding, which reconstructs the masked point tokens with an encoder-decoder architecture. Specifically, we first utilize off-the-shelf 2D models to extract the multi-view visual features of the input point cloud, and then conduct two types of image-to-point learning schemes on top. For one, we introduce a 2D-guided masking strategy that maintains semantically important point tokens to be visible for the encoder. Compared to random masking, the network can better concentrate on significant 3D structures and recover the masked tokens from key spatial cues. For another, we enforce these visible tokens to reconstruct the corresponding multi-view 2D features after the decoder. This enables the network to effectively inherit high-level 2D semantics learned from rich image data for discriminative 3D modeling. Aided by our image-to-point pre-training, the frozen I2P-MAE, without any fine-tuning, achieves 93.4% accuracy for linear SVM on ModelNet40, competitive to the fully trained results of existing methods. By further fine-tuning on on ScanObjectNN's hardest split, I2P-MAE attains the state-of-the-art 90.11% accuracy, +3.68% to the second-best, demonstrating superior transferable capacity. Code will be available at https://github.com/ZrrSkywalker/I2P-MAE.
Blind deblurring of hyperspectral document images
Mar 09, 2023Most computer vision and machine learning-based approaches for historical document analysis are tailored to grayscale or RGB images and thus, mostly exploit their spatial information. Multispectral (MS) and hyperspectral (HS) images contain, next to the spatial information, much richer spectral information than RGB images (usually spreading beyond the visible spectral range) that can facilitate more effective feature extraction, more accurate classification and recognition, and thus, improved analysis. Although utilization of rich spectral information can improve historical document analysis tremendously, there are still some potential limitations of HS imagery such as camera-induced noise and blur that require a carefully designed preprocessing step. Here, we propose novel blind HS image deblurring methods tailored to document images. We exploit a low-rank property of HS images (i.e., by projecting an HS image to a lower dimensional subspace) and utilize a text tailor image prior to performing a PSF estimation and deblurring of subspace components. The preliminary results show that the proposed approach gives good results over all spectral bands, removing successfully image artefacts introduced by blur and noise and significantly increasing the number of bands that can be used in further analysis.
* This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No. 101026453. This work is published in the Lecture Notes in Computer Science book series (LNCS, volume 13373) as part of the Image Analysis and Processing, ICIAP 2022 Workshops