 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEESE: Genotype-aware End-to-End Spatio-temporal Embedding for Behavioral Phenotyping
May 23, 2026Behavioral phenotyping of genetic animal models currently requires labor-intensive manual feature engineering that limits reproducibility and scalability. We present GEESE, an end-to-end deep learning framework that learns behavioral representations directly from 3D pose dynamics without hand-crafted features. Using a pretrained time series foundation model, we encode movement sequences into a behavioral manifold that supports both behavior classification and genotype prediction. Evaluated across three autism-associated genetic models (CNTNAP2, CHD8, FMR1), our deep learning approach surpasses hand-crafted feature baselines in both tasks, revealing that learned representations capture genotype-specific behavioral signatures. The framework generalizes across genetic backgrounds, and an all-cohort model identifies both genetic background and genotype from movement patterns alone. We further provide HONK, an interactive intelligent tool enabling researchers without programming expertise to perform behavioral phenotyping from pose data through natural language interaction.
PAD-Hand: Physics-Aware Diffusion for Hand Motion Recovery
Mar 27, 2026Significant advancements made in reconstructing hands from images have delivered accurate single-frame estimates, yet they often lack physics consistency and provide no notion of how confidently the motion satisfies physics. In this paper, we propose a novel physics-aware conditional diffusion framework that refines noisy pose sequences into physically plausible hand motion while estimating the physics variance in motion estimates. Building on a MeshCNN-Transformer backbone, we formulate Euler-Lagrange dynamics for articulated hands. Unlike prior works that enforce zero residuals, we treat the resulting dynamic residuals as virtual observables to more effectively integrate physics. Through a last-layer Laplace approximation, our method produces per-joint, per-time variances that measure physics consistency and offers interpretable variance maps indicating where physical consistency weakens. Experiments on two well-known hand datasets show consistent gains over strong image-based initializations and competitive video-based methods. Qualitative results confirm that our variance estimations are aligned with the physical plausibility of the motion in image-based estimates.
Beyond Motion Pattern: An Empirical Study of Physical Forces for Human Motion Understanding
Dec 23, 2025



Human motion understanding has advanced rapidly through vision-based progress in recognition, tracking, and captioning. However, most existing methods overlook physical cues such as joint actuation forces that are fundamental in biomechanics. This gap motivates our study: if and when do physically inferred forces enhance motion understanding? By incorporating forces into established motion understanding pipelines, we systematically evaluate their impact across baseline models on 3 major tasks: gait recognition, action recognition, and fine-grained video captioning. Across 8 benchmarks, incorporating forces yields consistent performance gains; for example, on CASIA-B, Rank-1 gait recognition accuracy improved from 89.52% to 90.39% (+0.87), with larger gain observed under challenging conditions: +2.7% when wearing a coat and +3.0% at the side view. On Gait3D, performance also increases from 46.0% to 47.3% (+1.3). In action recognition, CTR-GCN achieved +2.00% on Penn Action, while high-exertion classes like punching/slapping improved by +6.96%. Even in video captioning, Qwen2.5-VL's ROUGE-L score rose from 0.310 to 0.339 (+0.029), indicating that physics-inferred forces enhance temporal grounding and semantic richness. These results demonstrate that force cues can substantially complement visual and kinematic features under dynamic, occluded, or appearance-varying conditions.
SAVVY: Spatial Awareness via Audio-Visual LLMs through Seeing and Hearing
Jun 04, 20253D spatial reasoning in dynamic, audio-visual environments is a cornerstone of human cognition yet remains largely unexplored by existing Audio-Visual Large Language Models (AV-LLMs) and benchmarks, which predominantly focus on static or 2D scenes. We introduce SAVVY-Bench, the first benchmark for 3D spatial reasoning in dynamic scenes with synchronized spatial audio. SAVVY-Bench is comprised of thousands of relationships involving static and moving objects, and requires fine-grained temporal grounding, consistent 3D localization, and multi-modal annotation. To tackle this challenge, we propose SAVVY, a novel training-free reasoning pipeline that consists of two stages: (i) Egocentric Spatial Tracks Estimation, which leverages AV-LLMs as well as other audio-visual methods to track the trajectories of key objects related to the query using both visual and spatial audio cues, and (ii) Dynamic Global Map Construction, which aggregates multi-modal queried object trajectories and converts them into a unified global dynamic map. Using the constructed map, a final QA answer is obtained through a coordinate transformation that aligns the global map with the queried viewpoint. Empirical evaluation demonstrates that SAVVY substantially enhances performance of state-of-the-art AV-LLMs, setting a new standard and stage for approaching dynamic 3D spatial reasoning in AV-LLMs.
Extracting Probabilistic Knowledge from Large Language Models for Bayesian Network Parameterization
May 21, 2025Large Language Models (LLMs) have demonstrated potential as factual knowledge bases; however, their capability to generate probabilistic knowledge about real-world events remains understudied. This paper investigates using probabilistic knowledge inherent in LLMs to derive probability estimates for statements concerning events and their interrelationships captured via a Bayesian Network (BN). Using LLMs in this context allows for the parameterization of BNs, enabling probabilistic modeling within specific domains. Experiments on eighty publicly available Bayesian Networks, from healthcare to finance, demonstrate that querying LLMs about the conditional probabilities of events provides meaningful results when compared to baselines, including random and uniform distributions, as well as approaches based on next-token generation probabilities. We explore how these LLM-derived distributions can serve as expert priors to refine distributions extracted from minimal data, significantly reducing systematic biases. Overall, this work introduces a promising strategy for automatically constructing Bayesian Networks by combining probabilistic knowledge extracted from LLMs with small amounts of real-world data. Additionally, we evaluate several prompting strategies for eliciting probabilistic knowledge from LLMs and establish the first comprehensive baseline for assessing LLM performance in extracting probabilistic knowledge.
Active Sequential Posterior Estimation for Sample-Efficient Simulation-Based Inference
Dec 07, 2024



Computer simulations have long presented the exciting possibility of scientific insight into complex real-world processes. Despite the power of modern computing, however, it remains challenging to systematically perform inference under simulation models. This has led to the rise of simulation-based inference (SBI), a class of machine learning-enabled techniques for approaching inverse problems with stochastic simulators. Many such methods, however, require large numbers of simulation samples and face difficulty scaling to high-dimensional settings, often making inference prohibitive under resource-intensive simulators. To mitigate these drawbacks, we introduce active sequential neural posterior estimation (ASNPE). ASNPE brings an active learning scheme into the inference loop to estimate the utility of simulation parameter candidates to the underlying probabilistic model. The proposed acquisition scheme is easily integrated into existing posterior estimation pipelines, allowing for improved sample efficiency with low computational overhead. We further demonstrate the effectiveness of the proposed method in the travel demand calibration setting, a high-dimensional inverse problem commonly requiring computationally expensive traffic simulators. Our method outperforms well-tuned benchmarks and state-of-the-art posterior estimation methods on a large-scale real-world traffic network, as well as demonstrates a performance advantage over non-active counterparts on a suite of SBI benchmark environments.
PhysPT: Physics-aware Pretrained Transformer for Estimating Human Dynamics from Monocular Videos
Apr 05, 2024While current methods have shown promising progress on estimating 3D human motion from monocular videos, their motion estimates are often physically unrealistic because they mainly consider kinematics. In this paper, we introduce Physics-aware Pretrained Transformer (PhysPT), which improves kinematics-based motion estimates and infers motion forces. PhysPT exploits a Transformer encoder-decoder backbone to effectively learn human dynamics in a self-supervised manner. Moreover, it incorporates physics principles governing human motion. Specifically, we build a physics-based body representation and contact force model. We leverage them to impose novel physics-inspired training losses (i.e., force loss, contact loss, and Euler-Lagrange loss), enabling PhysPT to capture physical properties of the human body and the forces it experiences. Experiments demonstrate that, once trained, PhysPT can be directly applied to kinematics-based estimates to significantly enhance their physical plausibility and generate favourable motion forces. Furthermore, we show that these physically meaningful quantities translate into improved accuracy of an important downstream task: human action recognition.
Detecting Out-of-Context Multimodal Misinformation with interpretable neural-symbolic model
Apr 15, 2023Recent years have witnessed the sustained evolution of misinformation that aims at manipulating public opinions. Unlike traditional rumors or fake news editors who mainly rely on generated and/or counterfeited images, text and videos, current misinformation creators now more tend to use out-of-context multimedia contents (e.g. mismatched images and captions) to deceive the public and fake news detection systems. This new type of misinformation increases the difficulty of not only detection but also clarification, because every individual modality is close enough to true information. To address this challenge, in this paper we explore how to achieve interpretable cross-modal de-contextualization detection that simultaneously identifies the mismatched pairs and the cross-modal contradictions, which is helpful for fact-check websites to document clarifications. The proposed model first symbolically disassembles the text-modality information to a set of fact queries based on the Abstract Meaning Representation of the caption and then forwards the query-image pairs into a pre-trained large vision-language model select the ``evidences" that are helpful for us to detect misinformation. Extensive experiments indicate that the proposed methodology can provide us with much more interpretable predictions while maintaining the accuracy same as the state-of-the-art model on this task.
Knowledge-augmented Deep Learning and Its Applications: A Survey
Nov 30, 2022Deep learning models, though having achieved great success in many different fields over the past years, are usually data hungry, fail to perform well on unseen samples, and lack of interpretability. Various prior knowledge often exists in the target domain and their use can alleviate the deficiencies with deep learning. To better mimic the behavior of human brains, different advanced methods have been proposed to identify domain knowledge and integrate it into deep models for data-efficient, generalizable, and interpretable deep learning, which we refer to as knowledge-augmented deep learning (KADL). In this survey, we define the concept of KADL, and introduce its three major tasks, i.e., knowledge identification, knowledge representation, and knowledge integration. Different from existing surveys that are focused on a specific type of knowledge, we provide a broad and complete taxonomy of domain knowledge and its representations. Based on our taxonomy, we provide a systematic review of existing techniques, different from existing works that survey integration approaches agnostic to taxonomy of knowledge. This survey subsumes existing works and offers a bird's-eye view of research in the general area of knowledge-augmented deep learning. The thorough and critical reviews of numerous papers help not only understand current progresses but also identify future directions for the research on knowledge-augmented deep learning.
Empirical Bayesian Approaches for Robust Constraint-based Causal Discovery under Insufficient Data
Jun 16, 2022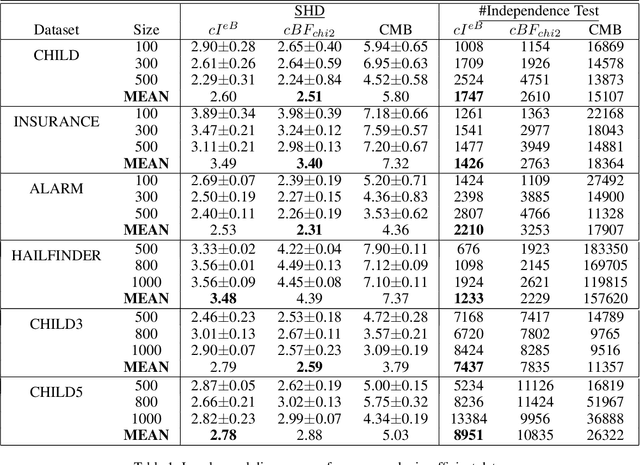
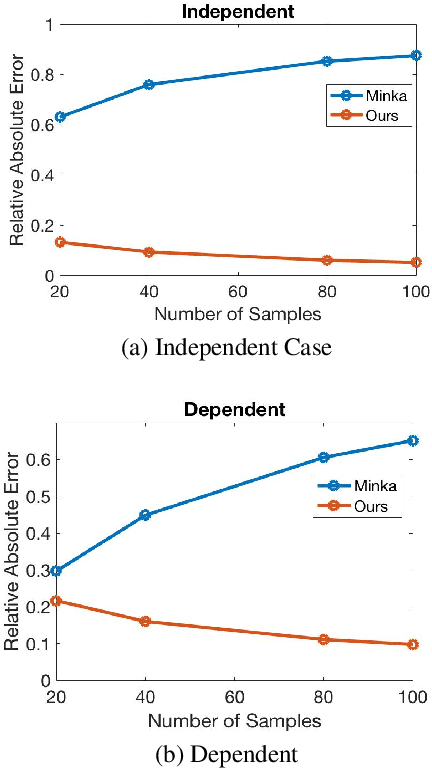
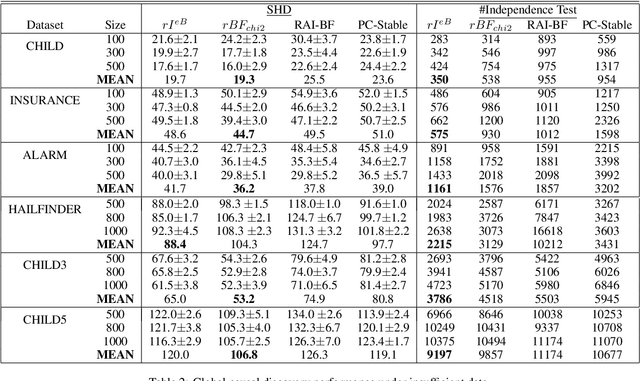
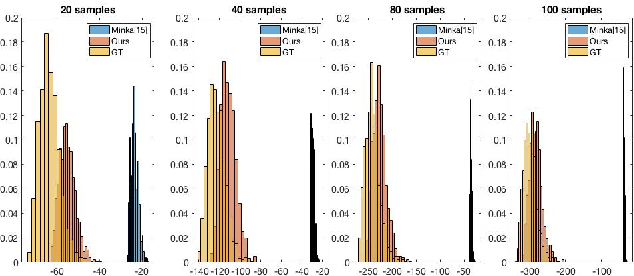
Causal discovery is to learn cause-effect relationships among variables given observational data and is important for many applications. Existing causal discovery methods assume data sufficiency, which may not be the case in many real world datasets. As a result, many existing causal discovery methods can fail under limited data. In this work, we propose Bayesian-augmented frequentist independence tests to improve the performance of constraint-based causal discovery methods under insufficient data: 1) We firstly introduce a Bayesian method to estimate mutual information (MI), based on which we propose a robust MI based independence test; 2) Secondly, we consider the Bayesian estimation of hypothesis likelihood and incorporate it into a well-defined statistical test, resulting in a robust statistical testing based independence test. We apply proposed independence tests to constraint-based causal discovery methods and evaluate the performance on benchmark datasets with insufficient samples. Experiments show significant performance improvement in terms of both accuracy and efficiency over SOTA methods.