 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Patches to Objects: Exploiting Spatial Reasoning for Better Visual Representations
May 21, 2023
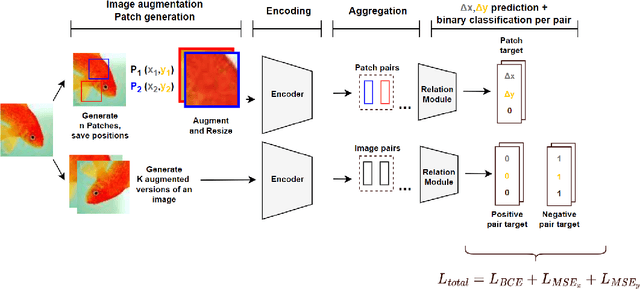

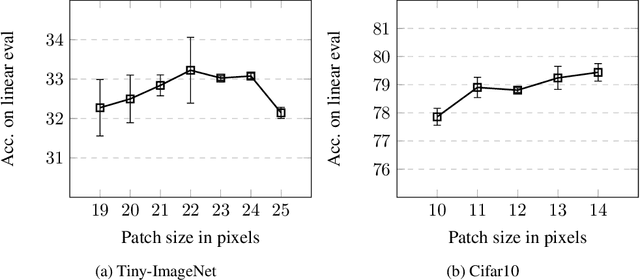
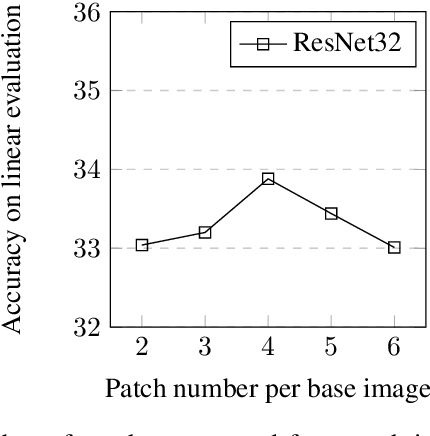
As the field of deep learning steadily transitions from the realm of academic research to practical application, the significance of self-supervised pretraining methods has become increasingly prominent. These methods, particularly in the image domain, offer a compelling strategy to effectively utilize the abundance of unlabeled image data, thereby enhancing downstream tasks' performance. In this paper, we propose a novel auxiliary pretraining method that is based on spatial reasoning. Our proposed method takes advantage of a more flexible formulation of contrastive learning by introducing spatial reasoning as an auxiliary task for discriminative self-supervised methods. Spatial Reasoning works by having the network predict the relative distances between sampled non-overlapping patches. We argue that this forces the network to learn more detailed and intricate internal representations of the objects and the relationships between their constituting parts. Our experiments demonstrate substantial improvement in downstream performance in linear evaluation compared to similar work and provide directions for further research into spatial reasoning.
Controlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023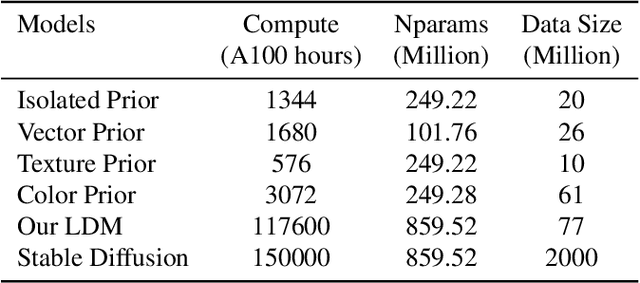
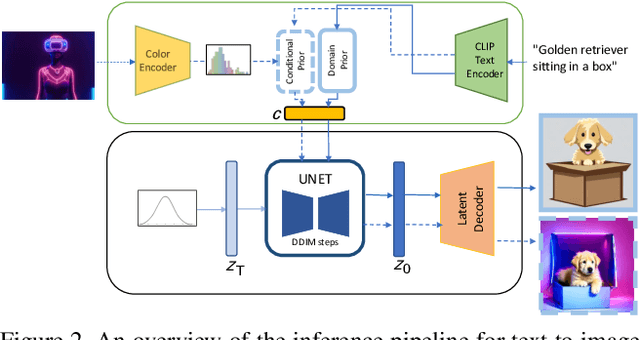
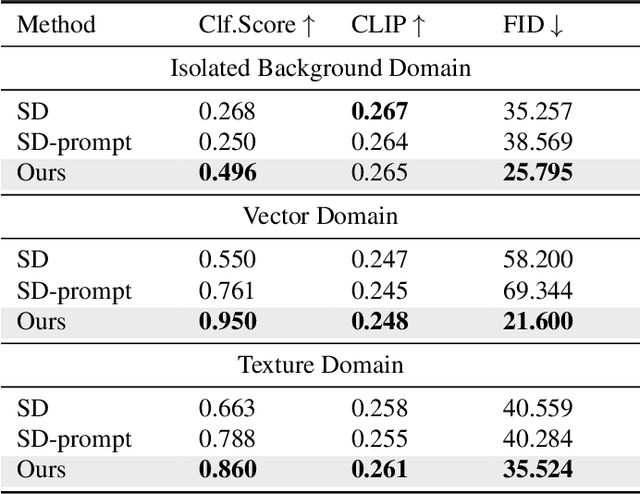

Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
Learning to Scale Temperature in Masked Self-Attention for Image Inpainting
Feb 13, 2023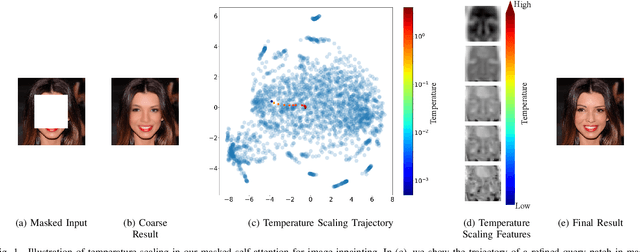

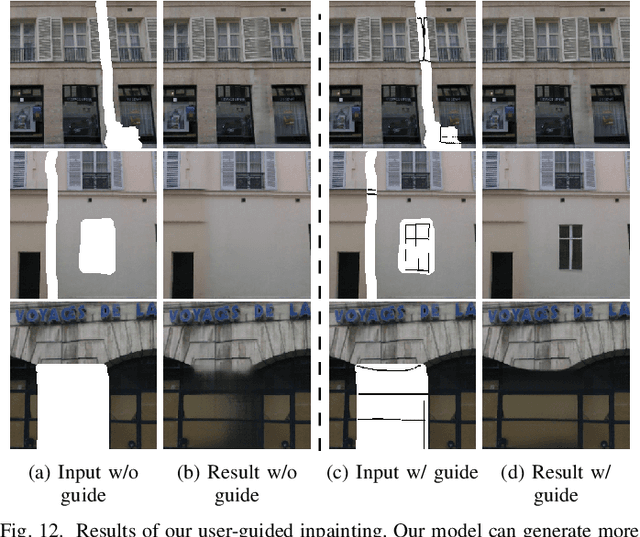
Recent advances in deep generative adversarial networks (GAN) and self-attention mechanism have led to significant improvements in the challenging task of inpainting large missing regions in an image. These methods integrate self-attention mechanism in neural networks to utilize surrounding neural elements based on their correlation and help the networks capture long-range dependencies. Temperature is a parameter in the Softmax function used in the self-attention, and it enables biasing the distribution of attention scores towards a handful of similar patches. Most existing self-attention mechanisms in image inpainting are convolution-based and set the temperature as a constant, performing patch matching in a limited feature space. In this work, we analyze the artifacts and training problems in previous self-attention mechanisms, and redesign the temperature learning network as well as the self-attention mechanism to address them. We present an image inpainting framework with a multi-head temperature masked self-attention mechanism, which provides stable and efficient temperature learning and uses multiple distant contextual information for high quality image inpainting. In addition to improving image quality of inpainting results, we generalize the proposed model to user-guided image editing by introducing a new sketch generation method. Extensive experiments on various datasets such as Paris StreetView, CelebA-HQ and Places2 clearly demonstrate that our method not only generates more natural inpainting results than previous works both in terms of perception image quality and quantitative metrics, but also enables to help users to generate more flexible results that are related to their sketch guidance.
High-order Spatial Interactions Enhanced Lightweight Model for Optical Remote Sensing Image-based Small Ship Detection
Apr 07, 2023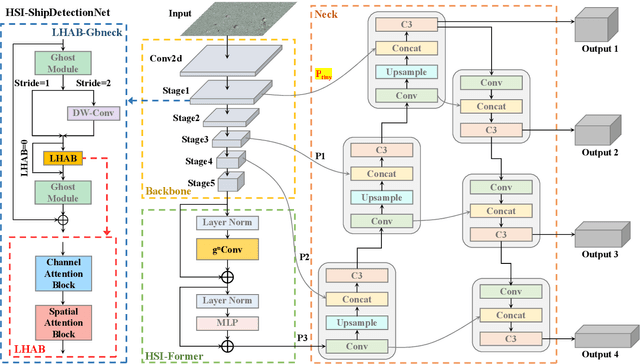
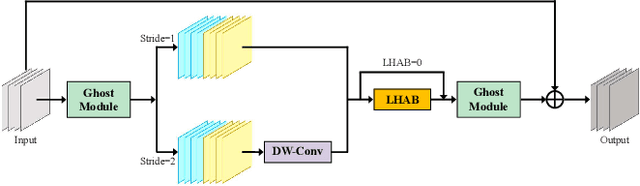
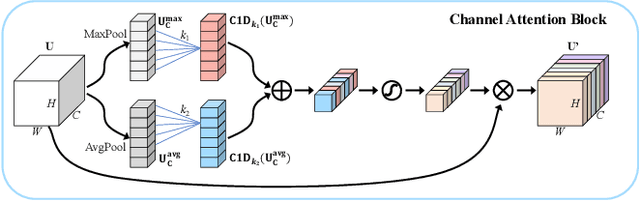
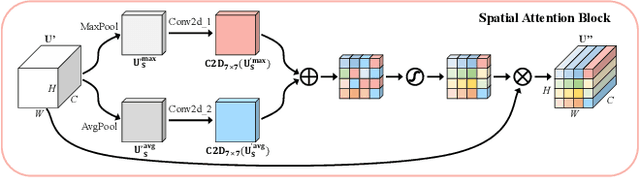
Accurate and reliable optical remote sensing image-based small-ship detection is crucial for maritime surveillance systems, but existing methods often struggle with balancing detection performance and computational complexity. In this paper, we propose a novel lightweight framework called \textit{HSI-ShipDetectionNet} that is based on high-order spatial interactions and is suitable for deployment on resource-limited platforms, such as satellites and unmanned aerial vehicles. HSI-ShipDetectionNet includes a prediction branch specifically for tiny ships and a lightweight hybrid attention block for reduced complexity. Additionally, the use of a high-order spatial interactions module improves advanced feature understanding and modeling ability. Our model is evaluated using the public Kaggle marine ship detection dataset and compared with multiple state-of-the-art models including small object detection models, lightweight detection models, and ship detection models. The results show that HSI-ShipDetectionNet outperforms the other models in terms of recall, and mean average precision (mAP) while being lightweight and suitable for deployment on resource-limited platforms.
Multi-source adversarial transfer learning based on similar source domains with local features
May 30, 2023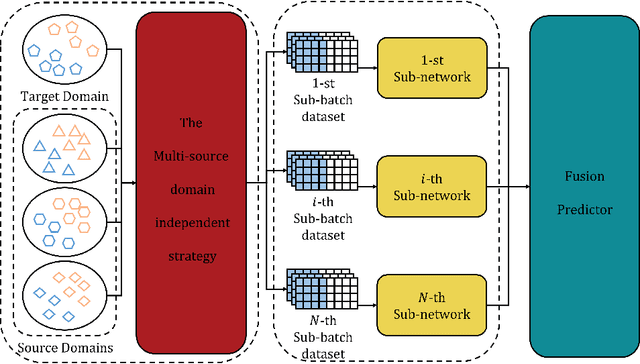

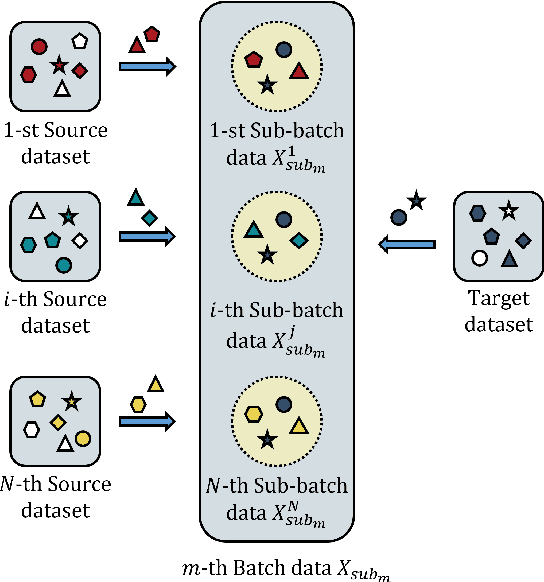
Transfer learning leverages knowledge from other domains and has been successful in many applications. Transfer learning methods rely on the overall similarity of the source and target domains. However, in some cases, it is impossible to provide an overall similar source domain, and only some source domains with similar local features can be provided. Can transfer learning be achieved? In this regard, we propose a multi-source adversarial transfer learning method based on local feature similarity to the source domain to handle transfer scenarios where the source and target domains have only local similarities. This method extracts transferable local features between a single source domain and the target domain through a sub-network. Specifically, the feature extractor of the sub-network is induced by the domain discriminator to learn transferable knowledge between the source domain and the target domain. The extracted features are then weighted by an attention module to suppress non-transferable local features while enhancing transferable local features. In order to ensure that the data from the target domain in different sub-networks in the same batch is exactly the same, we designed a multi-source domain independent strategy to provide the possibility for later local feature fusion to complete the key features required. In order to verify the effectiveness of the method, we made the dataset "Local Carvana Image Masking Dataset". Applying the proposed method to the image segmentation task of the proposed dataset achieves better transfer performance than other multi-source transfer learning methods. It is shown that the designed transfer learning method is feasible for transfer scenarios where the source and target domains have only local similarities.
UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
May 18, 2023
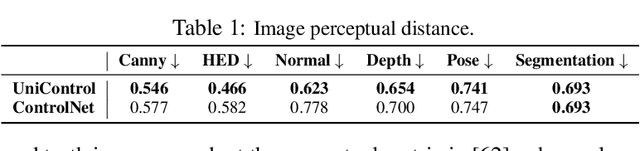
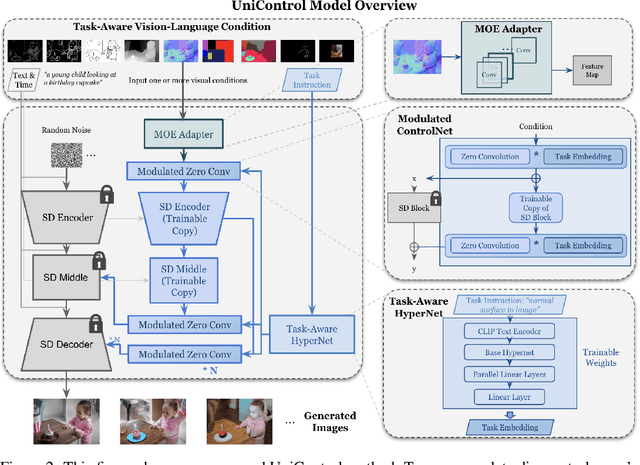

Achieving machine autonomy and human control often represent divergent objectives in the design of interactive AI systems. Visual generative foundation models such as Stable Diffusion show promise in navigating these goals, especially when prompted with arbitrary languages. However, they often fall short in generating images with spatial, structural, or geometric controls. The integration of such controls, which can accommodate various visual conditions in a single unified model, remains an unaddressed challenge. In response, we introduce UniControl, a new generative foundation model that consolidates a wide array of controllable condition-to-image (C2I) tasks within a singular framework, while still allowing for arbitrary language prompts. UniControl enables pixel-level-precise image generation, where visual conditions primarily influence the generated structures and language prompts guide the style and context. To equip UniControl with the capacity to handle diverse visual conditions, we augment pretrained text-to-image diffusion models and introduce a task-aware HyperNet to modulate the diffusion models, enabling the adaptation to different C2I tasks simultaneously. Trained on nine unique C2I tasks, UniControl demonstrates impressive zero-shot generation abilities with unseen visual conditions. Experimental results show that UniControl often surpasses the performance of single-task-controlled methods of comparable model sizes. This control versatility positions UniControl as a significant advancement in the realm of controllable visual generation.
OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding
May 18, 2023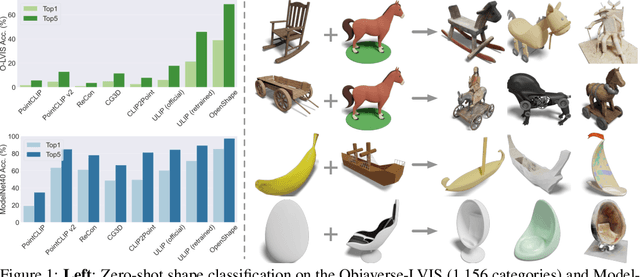
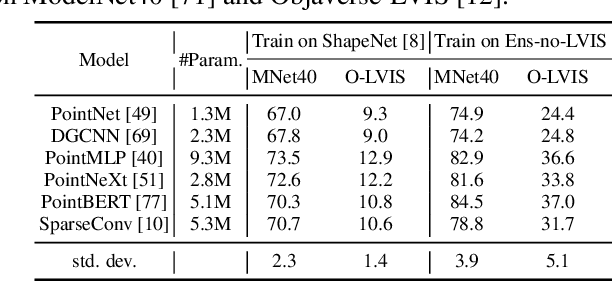
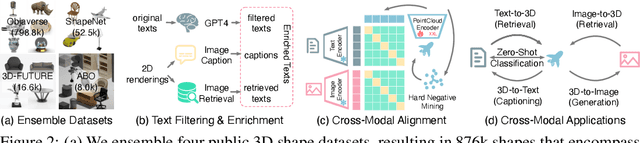
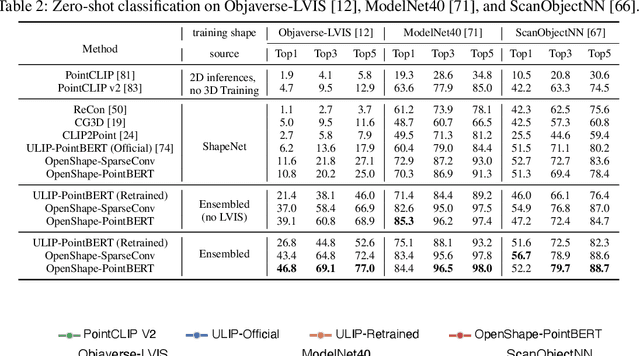
We introduce OpenShape, a method for learning multi-modal joint representations of text, image, and point clouds. We adopt the commonly used multi-modal contrastive learning framework for representation alignment, but with a specific focus on scaling up 3D representations to enable open-world 3D shape understanding. To achieve this, we scale up training data by ensembling multiple 3D datasets and propose several strategies to automatically filter and enrich noisy text descriptions. We also explore and compare strategies for scaling 3D backbone networks and introduce a novel hard negative mining module for more efficient training. We evaluate OpenShape on zero-shot 3D classification benchmarks and demonstrate its superior capabilities for open-world recognition. Specifically, OpenShape achieves a zero-shot accuracy of 46.8% on the 1,156-category Objaverse-LVIS benchmark, compared to less than 10% for existing methods. OpenShape also achieves an accuracy of 85.3% on ModelNet40, outperforming previous zero-shot baseline methods by 20% and performing on par with some fully-supervised methods. Furthermore, we show that our learned embeddings encode a wide range of visual and semantic concepts (e.g., subcategories, color, shape, style) and facilitate fine-grained text-3D and image-3D interactions. Due to their alignment with CLIP embeddings, our learned shape representations can also be integrated with off-the-shelf CLIP-based models for various applications, such as point cloud captioning and point cloud-conditioned image generation.
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Jan 30, 2023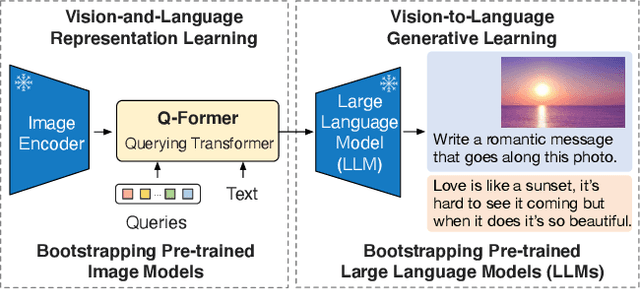

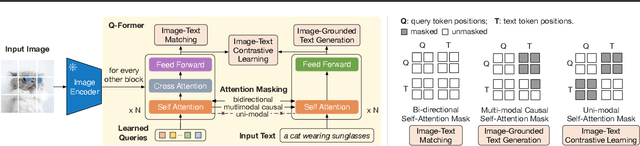
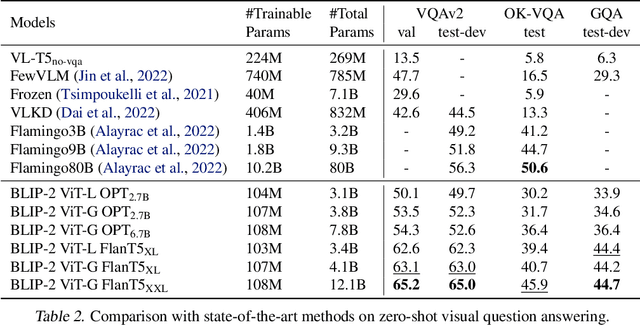
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
Fashionpedia-Taste: A Dataset towards Explaining Human Fashion Taste
May 03, 2023
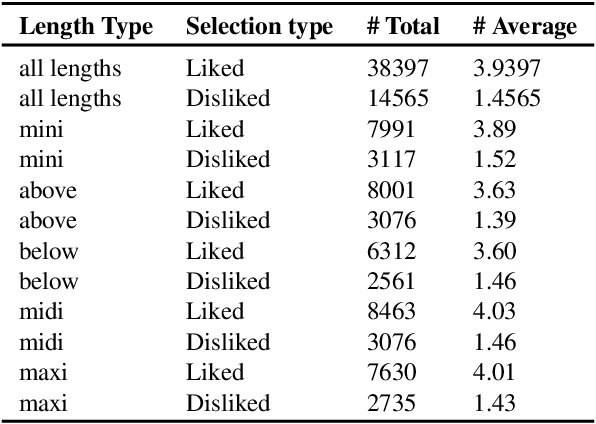

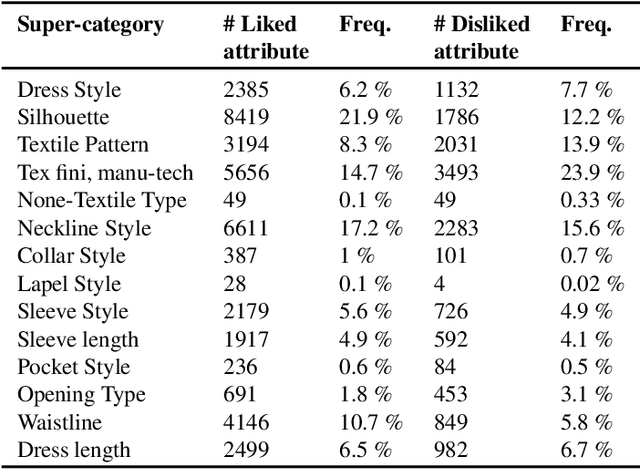
Existing fashion datasets do not consider the multi-facts that cause a consumer to like or dislike a fashion image. Even two consumers like a same fashion image, they could like this image for total different reasons. In this paper, we study the reason why a consumer like a certain fashion image. Towards this goal, we introduce an interpretability dataset, Fashionpedia-taste, consist of rich annotation to explain why a subject like or dislike a fashion image from the following 3 perspectives: 1) localized attributes; 2) human attention; 3) caption. Furthermore, subjects are asked to provide their personal attributes and preference on fashion, such as personality and preferred fashion brands. Our dataset makes it possible for researchers to build computational models to fully understand and interpret human fashion taste from different humanistic perspectives and modalities.
Towards L-System Captioning for Tree Reconstruction
May 10, 2023
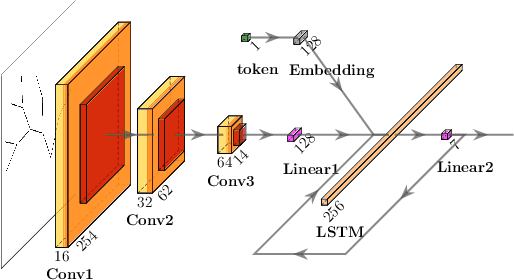
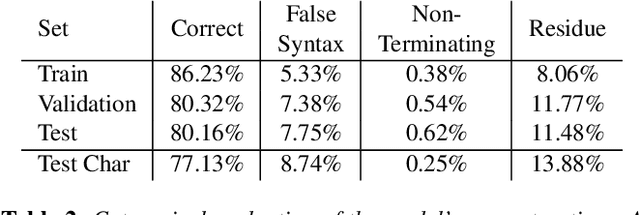
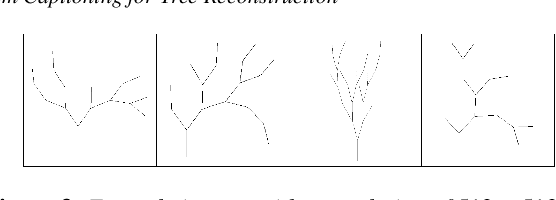
This work proposes a novel concept for tree and plant reconstruction by directly inferring a Lindenmayer-System (L-System) word representation from image data in an image captioning approach. We train a model end-to-end which is able to translate given images into L-System words as a description of the displayed tree. To prove this concept, we demonstrate the applicability on 2D tree topologies. Transferred to real image data, this novel idea could lead to more efficient, accurate and semantically meaningful tree and plant reconstruction without using error-prone point cloud extraction, and other processes usually utilized in tree reconstruction. Furthermore, this approach bypasses the need for a predefined L-System grammar and enables species-specific L-System inference without biological knowledge.