 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scale-aware Super-resolution Network with Dual Affinity Learning for Lesion Segmentation from Medical Images
May 30, 2023
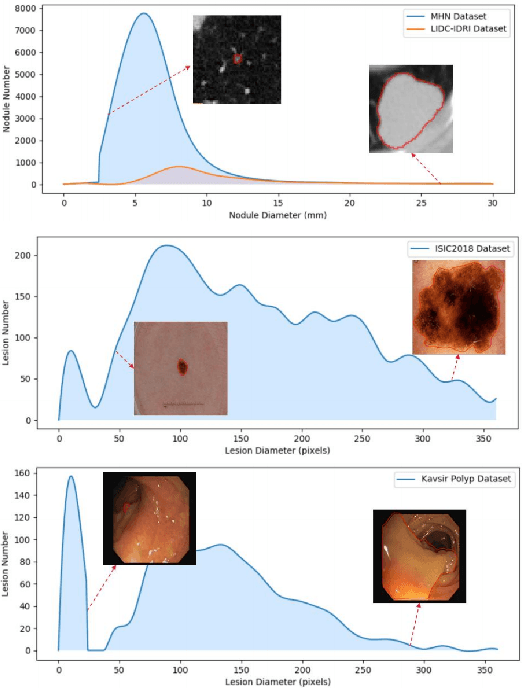
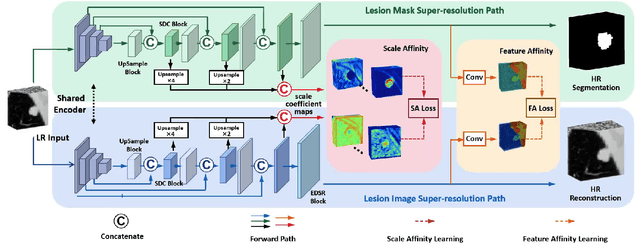
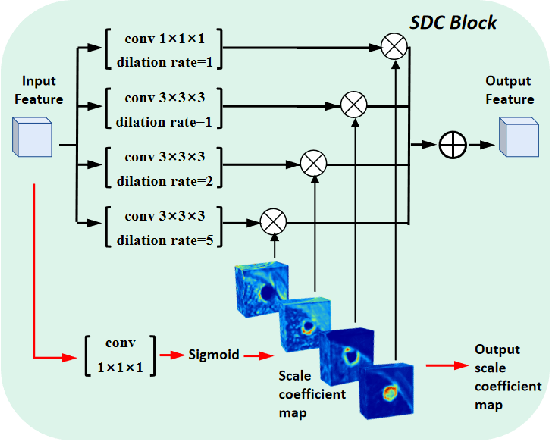

Convolutional Neural Networks (CNNs) have shown remarkable progress in medical image segmentation. However, lesion segmentation remains a challenge to state-of-the-art CNN-based algorithms due to the variance in scales and shapes. On the one hand, tiny lesions are hard to be delineated precisely from the medical images which are often of low resolutions. On the other hand, segmenting large-size lesions requires large receptive fields, which exacerbates the first challenge. In this paper, we present a scale-aware super-resolution network to adaptively segment lesions of various sizes from the low-resolution medical images. Our proposed network contains dual branches to simultaneously conduct lesion mask super-resolution and lesion image super-resolution. The image super-resolution branch will provide more detailed features for the segmentation branch, i.e., the mask super-resolution branch, for fine-grained segmentation. Meanwhile, we introduce scale-aware dilated convolution blocks into the multi-task decoders to adaptively adjust the receptive fields of the convolutional kernels according to the lesion sizes. To guide the segmentation branch to learn from richer high-resolution features, we propose a feature affinity module and a scale affinity module to enhance the multi-task learning of the dual branches. On multiple challenging lesion segmentation datasets, our proposed network achieved consistent improvements compared to other state-of-the-art methods.
A Byte Sequence is Worth an Image: CNN for File Fragment Classification Using Bit Shift and n-Gram Embeddings
Apr 14, 2023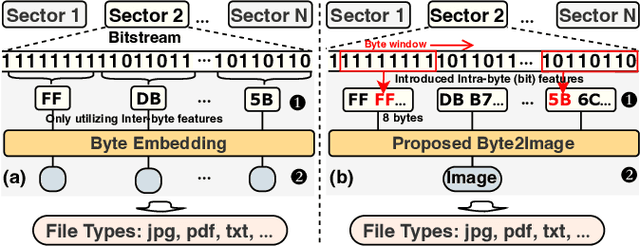
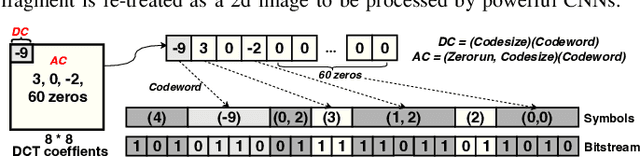
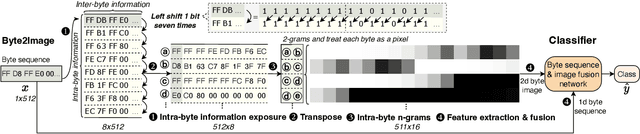
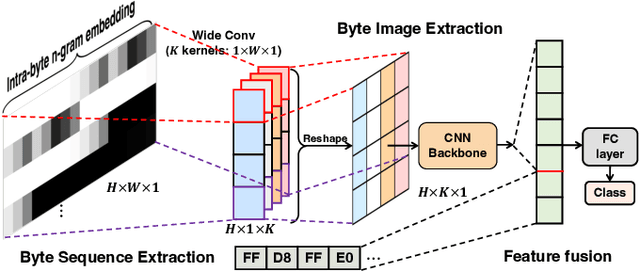
File fragment classification (FFC) on small chunks of memory is essential in memory forensics and Internet security. Existing methods mainly treat file fragments as 1d byte signals and utilize the captured inter-byte features for classification, while the bit information within bytes, i.e., intra-byte information, is seldom considered. This is inherently inapt for classifying variable-length coding files whose symbols are represented as the variable number of bits. Conversely, we propose Byte2Image, a novel data augmentation technique, to introduce the neglected intra-byte information into file fragments and re-treat them as 2d gray-scale images, which allows us to capture both inter-byte and intra-byte correlations simultaneously through powerful convolutional neural networks (CNNs). Specifically, to convert file fragments to 2d images, we employ a sliding byte window to expose the neglected intra-byte information and stack their n-gram features row by row. We further propose a byte sequence \& image fusion network as a classifier, which can jointly model the raw 1d byte sequence and the converted 2d image to perform FFC. Experiments on FFT-75 dataset validate that our proposed method can achieve notable accuracy improvements over state-of-the-art methods in nearly all scenarios. The code will be released at https://github.com/wenyang001/Byte2Image.
Leveraging Inpainting for Single-Image Shadow Removal
Feb 10, 2023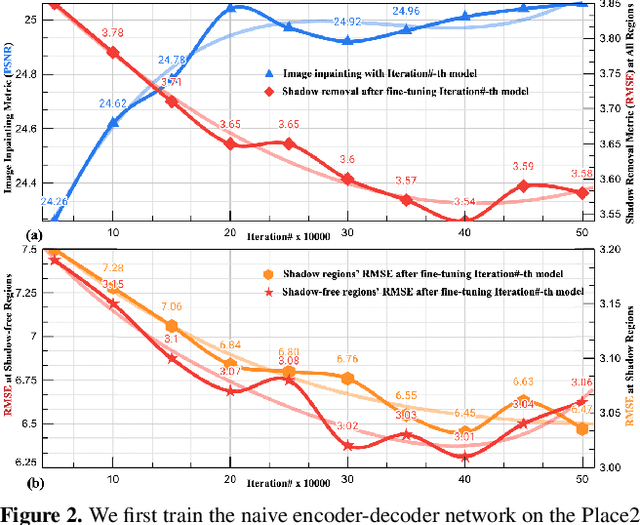
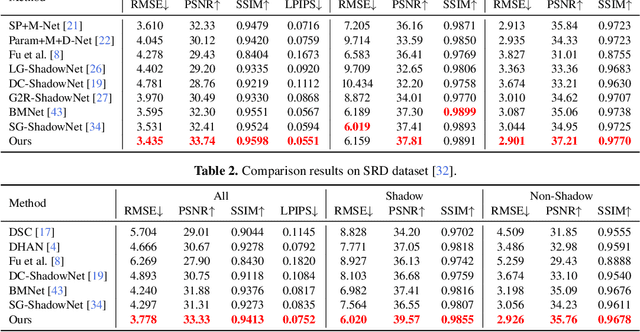
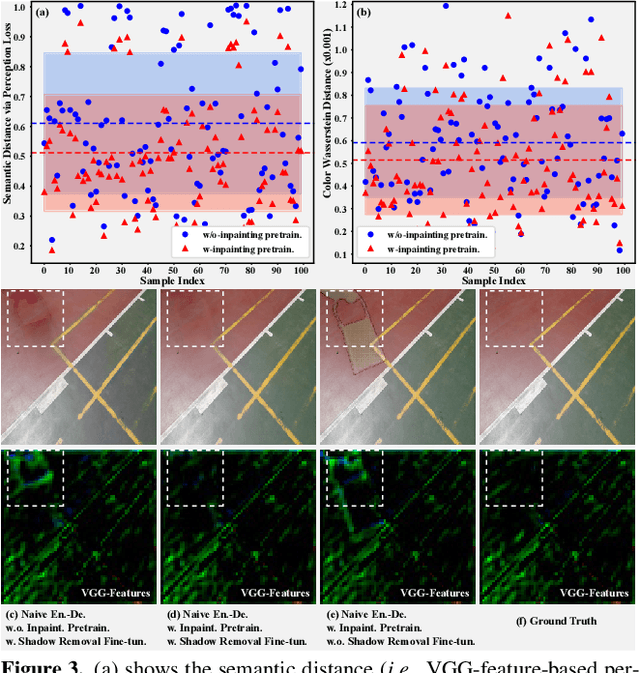
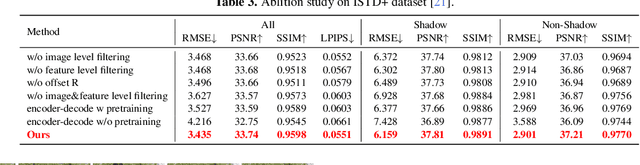
Fully-supervised shadow removal methods achieve top restoration qualities on public datasets but still generate some shadow remnants. One of the reasons is the lack of large-scale shadow & shadow-free image pairs. Unsupervised methods can alleviate the issue but their restoration qualities are much lower than those of fully-supervised methods. In this work, we find that pretraining shadow removal networks on the image inpainting dataset can reduce the shadow remnants significantly: a naive encoder-decoder network gets competitive restoration quality w.r.t. the state-of-the-art methods via only 10% shadow & shadow-free image pairs. We further analyze the difference between networks with/without inpainting pretraining and observe that: inpainting pretraining enhances networks' capability of filling missed semantic information; shadow removal fine-tuning makes the networks know how to fill details of the shadow regions. Inspired by the above observations, we formulate shadow removal as a shadow-guided inpainting task to take advantage of the shadow removal and image inpainting. Specifically, we build a shadow-informed dynamic filtering network with two branches: the image inpainting branch takes the shadow-masked image as input while the second branch takes the shadow image as input and is to estimate dynamic kernels and offsets for the first branch to provide missing semantic information and details. The extensive experiments show that our method empowered with inpainting outperforms all state-of-the-art methods.
No Wrong Turns: The Simple Geometry Of Neural Networks Optimization Paths
Jun 20, 2023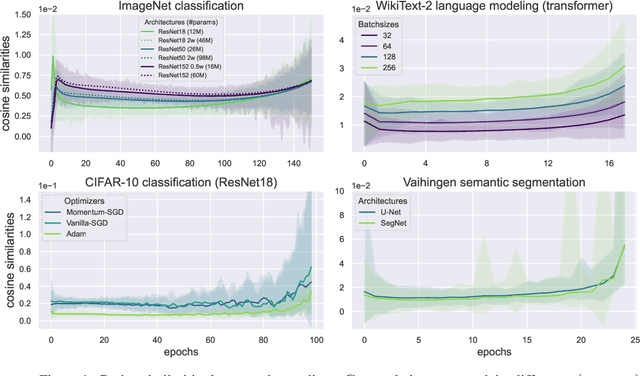
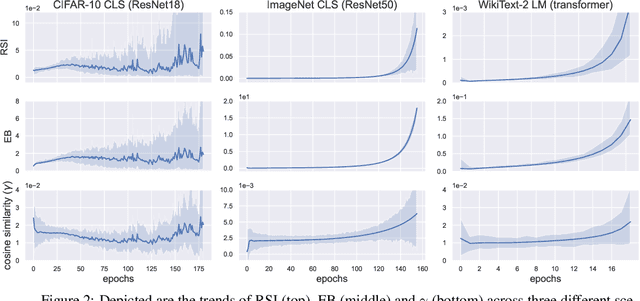

Understanding the optimization dynamics of neural networks is necessary for closing the gap between theory and practice. Stochastic first-order optimization algorithms are known to efficiently locate favorable minima in deep neural networks. This efficiency, however, contrasts with the non-convex and seemingly complex structure of neural loss landscapes. In this study, we delve into the fundamental geometric properties of sampled gradients along optimization paths. We focus on two key quantities, which appear in the restricted secant inequality and error bound. Both hold high significance for first-order optimization. Our analysis reveals that these quantities exhibit predictable, consistent behavior throughout training, despite the stochasticity induced by sampling minibatches. Our findings suggest that not only do optimization trajectories never encounter significant obstacles, but they also maintain stable dynamics during the majority of training. These observed properties are sufficiently expressive to theoretically guarantee linear convergence and prescribe learning rate schedules mirroring empirical practices. We conduct our experiments on image classification, semantic segmentation and language modeling across different batch sizes, network architectures, datasets, optimizers, and initialization seeds. We discuss the impact of each factor. Our work provides novel insights into the properties of neural network loss functions, and opens the door to theoretical frameworks more relevant to prevalent practice.
Hyperspectral Image Compression Using Implicit Neural Representation
Feb 08, 2023
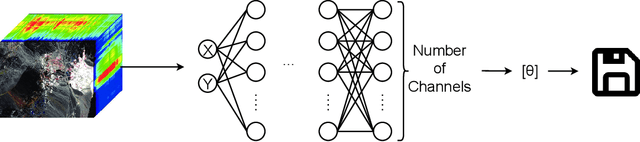

Hyperspectral images, which record the electromagnetic spectrum for a pixel in the image of a scene, often store hundreds of channels per pixel and contain an order of magnitude more information than a typical similarly-sized color image. Consequently, concomitant with the decreasing cost of capturing these images, there is a need to develop efficient techniques for storing, transmitting, and analyzing hyperspectral images. This paper develops a method for hyperspectral image compression using implicit neural representations where a multilayer perceptron network $\Phi_\theta$ with sinusoidal activation functions ``learns'' to map pixel locations to pixel intensities for a given hyperspectral image $I$. $\Phi_\theta$ thus acts as a compressed encoding of this image. The original image is reconstructed by evaluating $\Phi_\theta$ at each pixel location. We have evaluated our method on four benchmarks -- Indian Pines, Cuprite, Pavia University, and Jasper Ridge -- and we show the proposed method achieves better compression than JPEG, JPEG2000, PCA-DCT, and HVEC at low bitrates.
StructuredMesh: 3D Structured Optimization of Façade Components on Photogrammetric Mesh Models using Binary Integer Programming
Jun 07, 2023
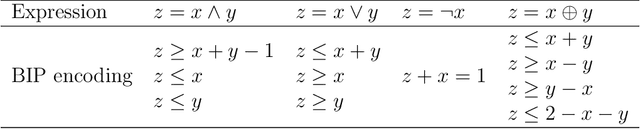
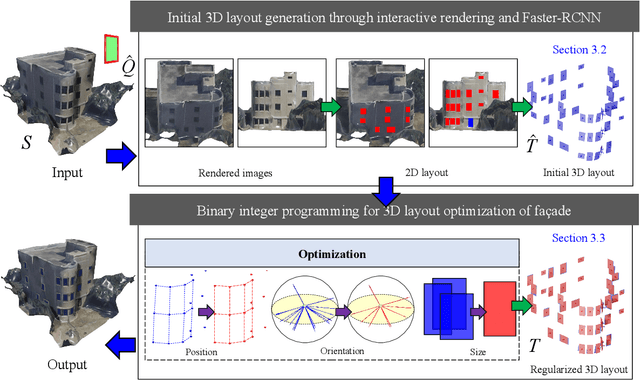
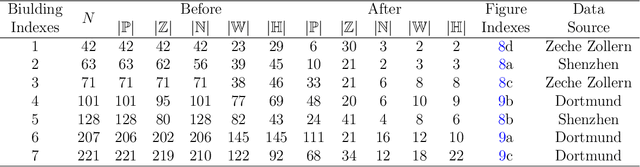
The lack of fa\c{c}ade structures in photogrammetric mesh models renders them inadequate for meeting the demands of intricate applications. Moreover, these mesh models exhibit irregular surfaces with considerable geometric noise and texture quality imperfections, making the restoration of structures challenging. To address these shortcomings, we present StructuredMesh, a novel approach for reconstructing fa\c{c}ade structures conforming to the regularity of buildings within photogrammetric mesh models. Our method involves capturing multi-view color and depth images of the building model using a virtual camera and employing a deep learning object detection pipeline to semi-automatically extract the bounding boxes of fa\c{c}ade components such as windows, doors, and balconies from the color image. We then utilize the depth image to remap these boxes into 3D space, generating an initial fa\c{c}ade layout. Leveraging architectural knowledge, we apply binary integer programming (BIP) to optimize the 3D layout's structure, encompassing the positions, orientations, and sizes of all components. The refined layout subsequently informs fa\c{c}ade modeling through instance replacement. We conducted experiments utilizing building mesh models from three distinct datasets, demonstrating the adaptability, robustness, and noise resistance of our proposed methodology. Furthermore, our 3D layout evaluation metrics reveal that the optimized layout enhances precision, recall, and F-score by 6.5%, 4.5%, and 5.5%, respectively, in comparison to the initial layout.
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023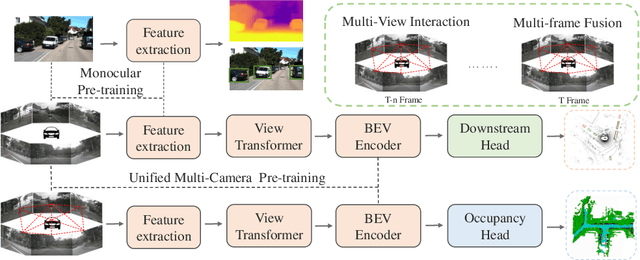
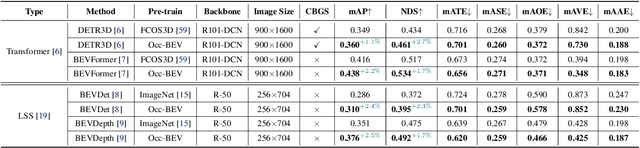
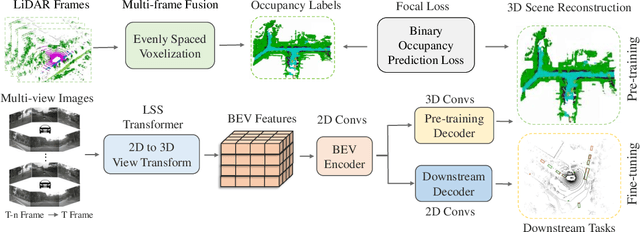

Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023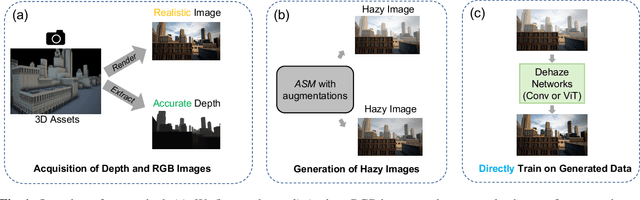
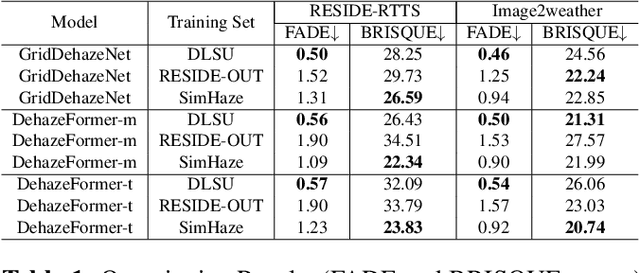

Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.
Understanding and Mitigating Copying in Diffusion Models
May 31, 2023
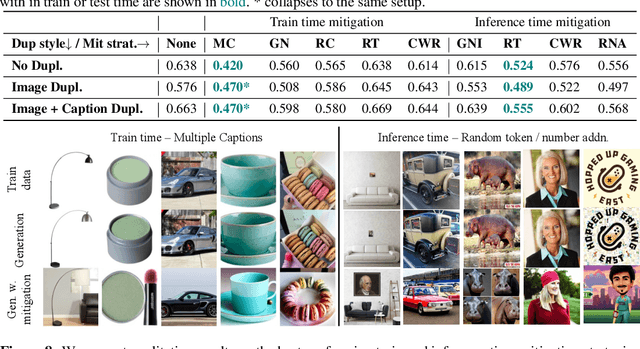

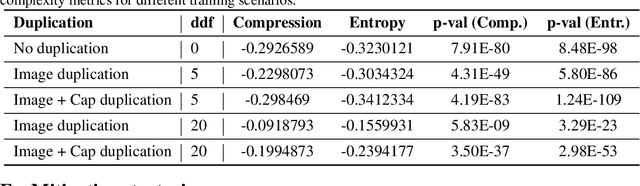
Images generated by diffusion models like Stable Diffusion are increasingly widespread. Recent works and even lawsuits have shown that these models are prone to replicating their training data, unbeknownst to the user. In this paper, we first analyze this memorization problem in text-to-image diffusion models. While it is widely believed that duplicated images in the training set are responsible for content replication at inference time, we observe that the text conditioning of the model plays a similarly important role. In fact, we see in our experiments that data replication often does not happen for unconditional models, while it is common in the text-conditional case. Motivated by our findings, we then propose several techniques for reducing data replication at both training and inference time by randomizing and augmenting image captions in the training set.
Using VGG16 Algorithms for classification of lung cancer in CT scans Image
May 27, 2023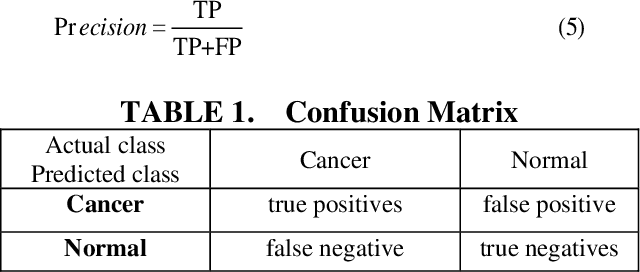
Lung cancer is the leading reason behind cancer-related deaths within the world. Early detection of lung nodules is vital for increasing the survival rate of cancer patients. Traditionally, physicians should manually identify the world suspected of getting carcinoma. When developing these detection systems, the arbitrariness of lung nodules' shape, size, and texture could be a challenge. Many studies showed the applied of computer vision algorithms to accurate diagnosis and classification of lung nodules. A deep learning algorithm called the VGG16 was developed during this paper to help medical professionals diagnose and classify carcinoma nodules. VGG16 can classify medical images of carcinoma in malignant, benign, and healthy patients. This paper showed that nodule detection using this single neural network had 92.08% sensitivity, 91% accuracy, and an AUC of 93%.