 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Vision Encoder Grafting via LLM Surrogates
May 28, 2025



Vision language models (VLMs) typically pair a modestly sized vision encoder with a large language model (LLM), e.g., Llama-70B, making the decoder the primary computational burden during training. To reduce costs, a potential promising strategy is to first train the vision encoder using a small language model before transferring it to the large one. We construct small "surrogate models" that share the same embedding space and representation language as the large target LLM by directly inheriting its shallow layers. Vision encoders trained on the surrogate can then be directly transferred to the larger model, a process we call zero-shot grafting -- when plugged directly into the full-size target LLM, the grafted pair surpasses the encoder-surrogate pair and, on some benchmarks, even performs on par with full decoder training with the target LLM. Furthermore, our surrogate training approach reduces overall VLM training costs by ~45% when using Llama-70B as the decoder.
Speedy-Splat: Fast 3D Gaussian Splatting with Sparse Pixels and Sparse Primitives
Nov 30, 20243D Gaussian Splatting (3D-GS) is a recent 3D scene reconstruction technique that enables real-time rendering of novel views by modeling scenes as parametric point clouds of differentiable 3D Gaussians. However, its rendering speed and model size still present bottlenecks, especially in resource-constrained settings. In this paper, we identify and address two key inefficiencies in 3D-GS, achieving substantial improvements in rendering speed, model size, and training time. First, we optimize the rendering pipeline to precisely localize Gaussians in the scene, boosting rendering speed without altering visual fidelity. Second, we introduce a novel pruning technique and integrate it into the training pipeline, significantly reducing model size and training time while further raising rendering speed. Our Speedy-Splat approach combines these techniques to accelerate average rendering speed by a drastic $6.71\times$ across scenes from the Mip-NeRF 360, Tanks & Temples, and Deep Blending datasets with $10.6\times$ fewer primitives than 3D-GS.
PUP 3D-GS: Principled Uncertainty Pruning for 3D Gaussian Splatting
Jun 14, 2024



Recent advancements in novel view synthesis have enabled real-time rendering speeds and high reconstruction accuracy. 3D Gaussian Splatting (3D-GS), a foundational point-based parametric 3D scene representation, models scenes as large sets of 3D Gaussians. Complex scenes can comprise of millions of Gaussians, amounting to large storage and memory requirements that limit the viability of 3D-GS on devices with limited resources. Current techniques for compressing these pretrained models by pruning Gaussians rely on combining heuristics to determine which ones to remove. In this paper, we propose a principled spatial sensitivity pruning score that outperforms these approaches. It is computed as a second-order approximation of the reconstruction error on the training views with respect to the spatial parameters of each Gaussian. Additionally, we propose a multi-round prune-refine pipeline that can be applied to any pretrained 3D-GS model without changing the training pipeline. After pruning 88.44% of the Gaussians, we observe that our PUP 3D-GS pipeline increases the average rendering speed of 3D-GS by 2.65$\times$ while retaining more salient foreground information and achieving higher image quality metrics than previous pruning techniques on scenes from the Mip-NeRF 360, Tanks & Temples, and Deep Blending datasets.
From Pixels to Prose: A Large Dataset of Dense Image Captions
Jun 14, 2024



Training large vision-language models requires extensive, high-quality image-text pairs. Existing web-scraped datasets, however, are noisy and lack detailed image descriptions. To bridge this gap, we introduce PixelProse, a comprehensive dataset of over 16M (million) synthetically generated captions, leveraging cutting-edge vision-language models for detailed and accurate descriptions. To ensure data integrity, we rigorously analyze our dataset for problematic content, including child sexual abuse material (CSAM), personally identifiable information (PII), and toxicity. We also provide valuable metadata such as watermark presence and aesthetic scores, aiding in further dataset filtering. We hope PixelProse will be a valuable resource for future vision-language research. PixelProse is available at https://huggingface.co/datasets/tomg-group-umd/pixelprose
A Simple and Efficient Baseline for Data Attribution on Images
Nov 03, 2023Data attribution methods play a crucial role in understanding machine learning models, providing insight into which training data points are most responsible for model outputs during deployment. However, current state-of-the-art approaches require a large ensemble of as many as 300,000 models to accurately attribute model predictions. These approaches therefore come at a high computational cost, are memory intensive, and are hard to scale to large models or datasets. In this work, we focus on a minimalist baseline, utilizing the feature space of a backbone pretrained via self-supervised learning to perform data attribution. Our method is model-agnostic and scales easily to large datasets. We show results on CIFAR-10 and ImageNet, achieving strong performance that rivals or outperforms state-of-the-art approaches at a fraction of the compute or memory cost. Contrary to prior work, our results reinforce the intuition that a model's prediction on one image is most impacted by visually similar training samples. Our approach serves as a simple and efficient baseline for data attribution on images.
Understanding and Mitigating Copying in Diffusion Models
May 31, 2023



Images generated by diffusion models like Stable Diffusion are increasingly widespread. Recent works and even lawsuits have shown that these models are prone to replicating their training data, unbeknownst to the user. In this paper, we first analyze this memorization problem in text-to-image diffusion models. While it is widely believed that duplicated images in the training set are responsible for content replication at inference time, we observe that the text conditioning of the model plays a similarly important role. In fact, we see in our experiments that data replication often does not happen for unconditional models, while it is common in the text-conditional case. Motivated by our findings, we then propose several techniques for reducing data replication at both training and inference time by randomizing and augmenting image captions in the training set.
What Can We Learn from Unlearnable Datasets?
May 30, 2023In an era of widespread web scraping, unlearnable dataset methods have the potential to protect data privacy by preventing deep neural networks from generalizing. But in addition to a number of practical limitations that make their use unlikely, we make a number of findings that call into question their ability to safeguard data. First, it is widely believed that neural networks trained on unlearnable datasets only learn shortcuts, simpler rules that are not useful for generalization. In contrast, we find that networks actually can learn useful features that can be reweighed for high test performance, suggesting that image privacy is not preserved. Unlearnable datasets are also believed to induce learning shortcuts through linear separability of added perturbations. We provide a counterexample, demonstrating that linear separability of perturbations is not a necessary condition. To emphasize why linearly separable perturbations should not be relied upon, we propose an orthogonal projection attack which allows learning from unlearnable datasets published in ICML 2021 and ICLR 2023. Our proposed attack is significantly less complex than recently proposed techniques.
Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models
Dec 12, 2022



Cutting-edge diffusion models produce images with high quality and customizability, enabling them to be used for commercial art and graphic design purposes. But do diffusion models create unique works of art, or are they replicating content directly from their training sets? In this work, we study image retrieval frameworks that enable us to compare generated images with training samples and detect when content has been replicated. Applying our frameworks to diffusion models trained on multiple datasets including Oxford flowers, Celeb-A, ImageNet, and LAION, we discuss how factors such as training set size impact rates of content replication. We also identify cases where diffusion models, including the popular Stable Diffusion model, blatantly copy from their training data.
Autoregressive Perturbations for Data Poisoning
Jun 15, 2022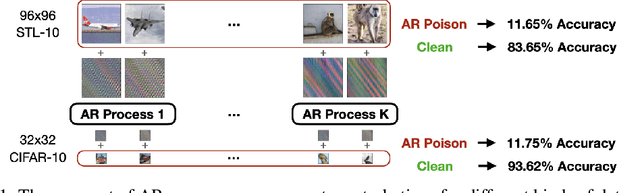
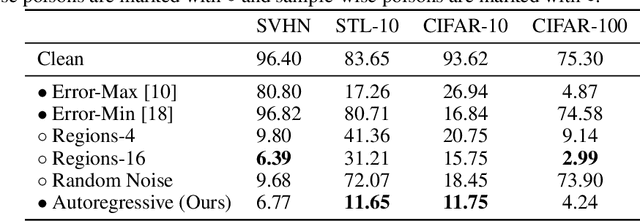
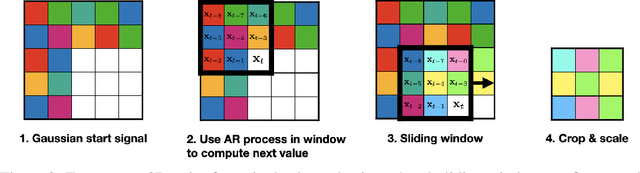
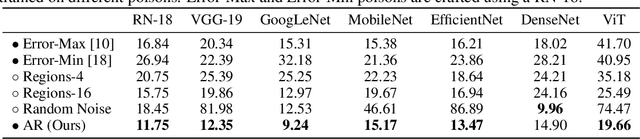
The prevalence of data scraping from social media as a means to obtain datasets has led to growing concerns regarding unauthorized use of data. Data poisoning attacks have been proposed as a bulwark against scraping, as they make data "unlearnable" by adding small, imperceptible perturbations. Unfortunately, existing methods require knowledge of both the target architecture and the complete dataset so that a surrogate network can be trained, the parameters of which are used to generate the attack. In this work, we introduce autoregressive (AR) poisoning, a method that can generate poisoned data without access to the broader dataset. The proposed AR perturbations are generic, can be applied across different datasets, and can poison different architectures. Compared to existing unlearnable methods, our AR poisons are more resistant against common defenses such as adversarial training and strong data augmentations. Our analysis further provides insight into what makes an effective data poison.
Poisons that are learned faster are more effective
Apr 19, 2022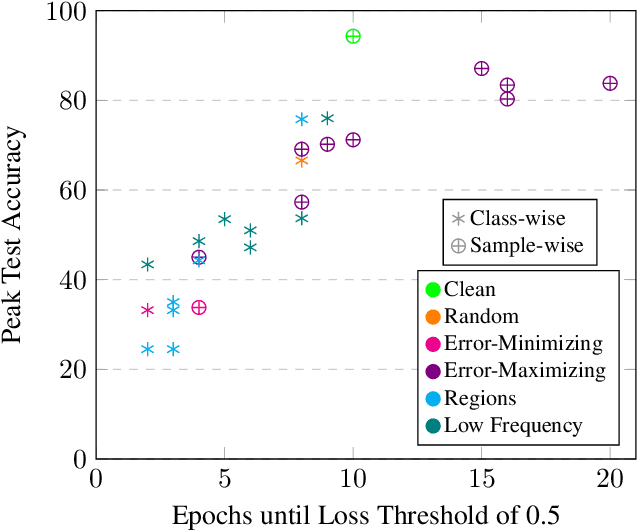
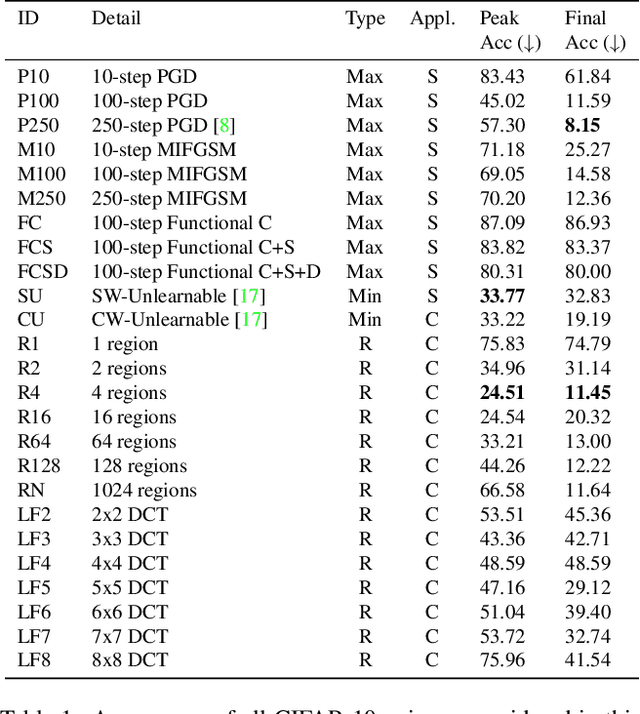
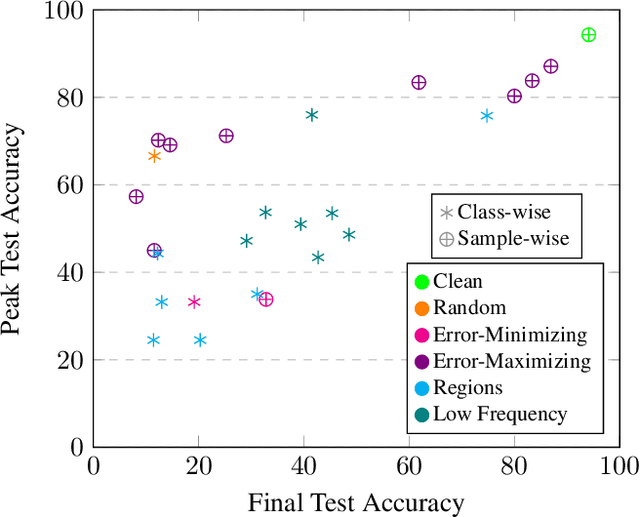
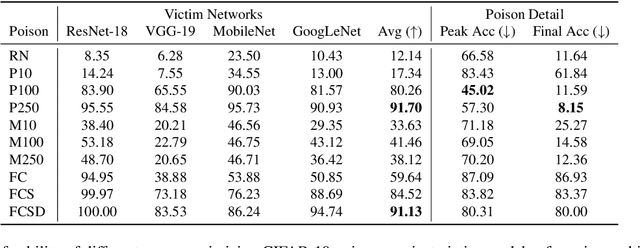
Imperceptible poisoning attacks on entire datasets have recently been touted as methods for protecting data privacy. However, among a number of defenses preventing the practical use of these techniques, early-stopping stands out as a simple, yet effective defense. To gauge poisons' vulnerability to early-stopping, we benchmark error-minimizing, error-maximizing, and synthetic poisons in terms of peak test accuracy over 100 epochs and make a number of surprising observations. First, we find that poisons that reach a low training loss faster have lower peak test accuracy. Second, we find that a current state-of-the-art error-maximizing poison is 7 times less effective when poison training is stopped at epoch 8. Third, we find that stronger, more transferable adversarial attacks do not make stronger poisons. We advocate for evaluating poisons in terms of peak test accuracy.