 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UnLoc: A Universal Localization Method for Autonomous Vehicles using LiDAR, Radar and/or Camera Input
Jul 03, 2023
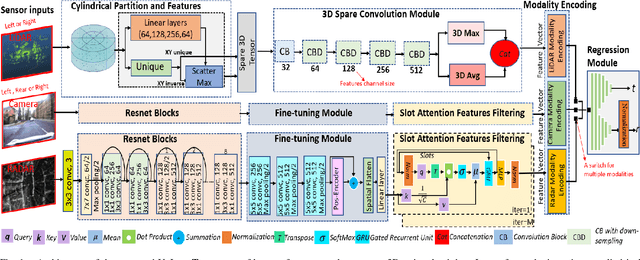
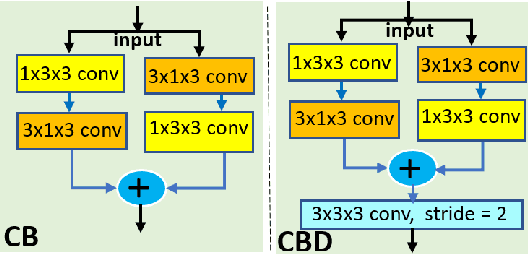
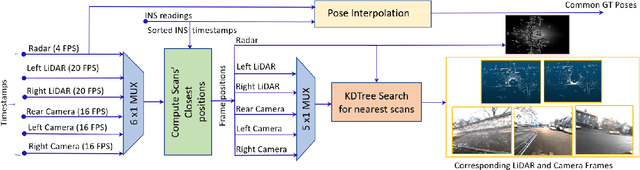
Localization is a fundamental task in robotics for autonomous navigation. Existing localization methods rely on a single input data modality or train several computational models to process different modalities. This leads to stringent computational requirements and sub-optimal results that fail to capitalize on the complementary information in other data streams. This paper proposes UnLoc, a novel unified neural modeling approach for localization with multi-sensor input in all weather conditions. Our multi-stream network can handle LiDAR, Camera and RADAR inputs for localization on demand, i.e., it can work with one or more input sensors, making it robust to sensor failure. UnLoc uses 3D sparse convolutions and cylindrical partitioning of the space to process LiDAR frames and implements ResNet blocks with a slot attention-based feature filtering module for the Radar and image modalities. We introduce a unique learnable modality encoding scheme to distinguish between the input sensor data. Our method is extensively evaluated on Oxford Radar RobotCar, ApolloSouthBay and Perth-WA datasets. The results ascertain the efficacy of our technique.
A CNN regression model to estimate buildings height maps using Sentinel-1 SAR and Sentinel-2 MSI time series
Jul 03, 2023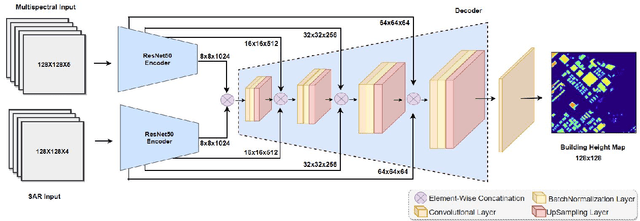
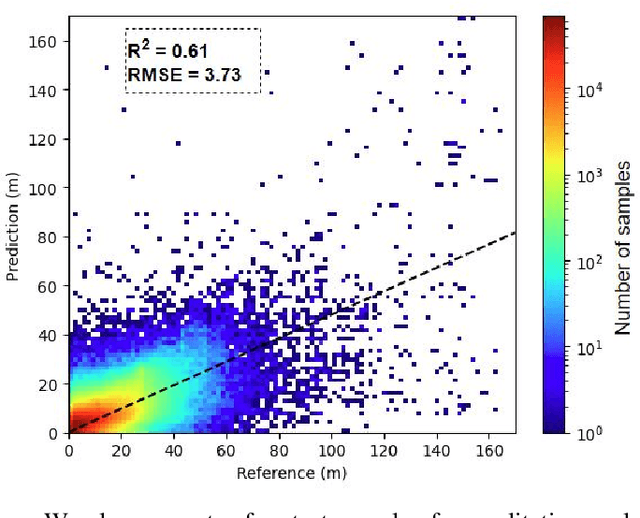

Accurate estimation of building heights is essential for urban planning, infrastructure management, and environmental analysis. In this study, we propose a supervised Multimodal Building Height Regression Network (MBHR-Net) for estimating building heights at 10m spatial resolution using Sentinel-1 (S1) and Sentinel-2 (S2) satellite time series. S1 provides Synthetic Aperture Radar (SAR) data that offers valuable information on building structures, while S2 provides multispectral data that is sensitive to different land cover types, vegetation phenology, and building shadows. Our MBHR-Net aims to extract meaningful features from the S1 and S2 images to learn complex spatio-temporal relationships between image patterns and building heights. The model is trained and tested in 10 cities in the Netherlands. Root Mean Squared Error (RMSE), Intersection over Union (IOU), and R-squared (R2) score metrics are used to evaluate the performance of the model. The preliminary results (3.73m RMSE, 0.95 IoU, 0.61 R2) demonstrate the effectiveness of our deep learning model in accurately estimating building heights, showcasing its potential for urban planning, environmental impact analysis, and other related applications.
Text-to-image Diffusion Model in Generative AI: A Survey
Mar 14, 2023


This survey reviews text-to-image diffusion models in the context that diffusion models have emerged to be popular for a wide range of generative tasks. As a self-contained work, this survey starts with a brief introduction of how a basic diffusion model works for image synthesis, followed by how condition or guidance improves learning. Based on that, we present a review of state-of-the-art methods on text-conditioned image synthesis, i.e., text-to-image. We further summarize applications beyond text-to-image generation: text-guided creative generation and text-guided image editing. Beyond the progress made so far, we discuss existing challenges and promising future directions.
Learning with Explicit Shape Priors for Medical Image Segmentation
Mar 31, 2023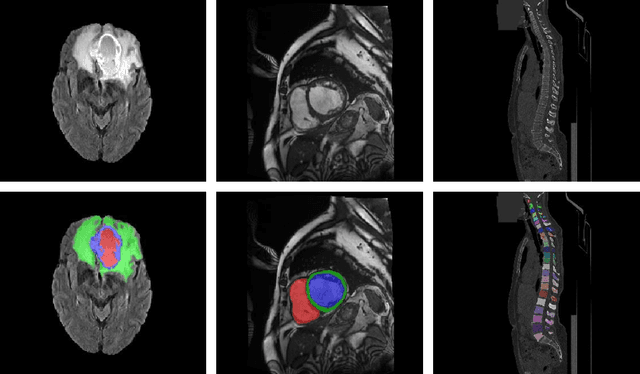
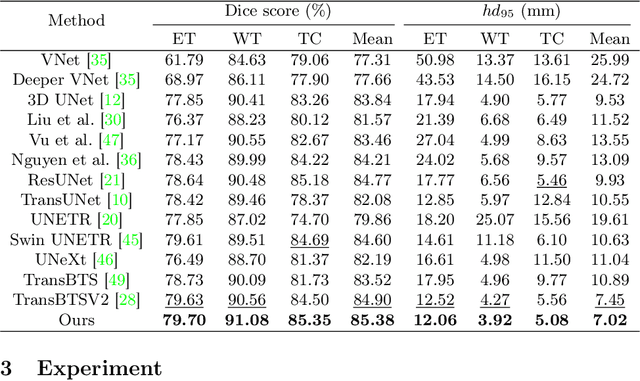
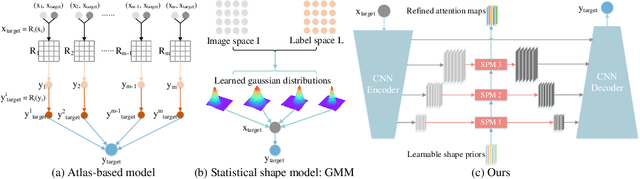
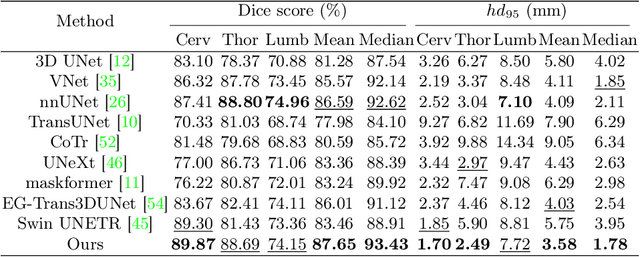
Medical image segmentation is considered as the basic step for medical image analysis and surgical intervention. And many previous works attempted to incorporate shape priors for designing segmentation models, which is beneficial to attain finer masks with anatomical shape information. Here in our work, we detailedly discuss three types of segmentation models with shape priors, which consist of atlas-based models, statistical-based models and UNet-based models. On the ground that the former two kinds of methods show a poor generalization ability, UNet-based models have dominated the field of medical image segmentation in recent years. However, existing UNet-based models tend to employ implicit shape priors, which do not have a good interpretability and generalization ability on different organs with distinctive shapes. Thus, we proposed a novel shape prior module (SPM), which could explicitly introduce shape priors to promote the segmentation performance of UNet-based models. To evaluate the effectiveness of SPM, we conduct experiments on three challenging public datasets. And our proposed model achieves state-of-the-art performance. Furthermore, SPM shows an outstanding generalization ability on different classic convolution-neural-networks (CNNs) and recent Transformer-based backbones, which can serve as a plug-and-play structure for the segmentation task of different datasets.
SMRVIS: Point cloud extraction from 3-D ultrasound for non-destructive testing
Jun 16, 2023
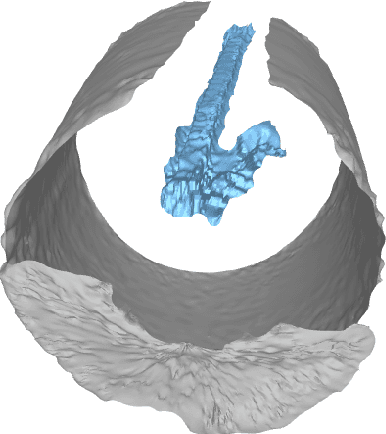

We propose to formulate point cloud extraction from ultrasound volumes as an image segmentation problem. Through this convenient formulation, a quick prototype exploring various variants of the Residual Network, U-Net, and the Squeeze and Excitation Network was developed and evaluated. This report documents the experimental results compiled using a training dataset of five labeled ultrasound volumes and 84 unlabeled volumes that got completed in a two-week period as part of a submission to the open challenge "3D Surface Mesh Estimation for CVPR workshop on Deep Learning in Ultrasound Image Analysis". Based on external evaluation performed by the challenge's organizers, the framework came first place on the challenge's \href{https://www.cvpr2023-dl-ultrasound.com/}{Leaderboard}. Source code is shared with the research community at a \href{https://github.com/lisatwyw/smrvis}{public repository}.
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023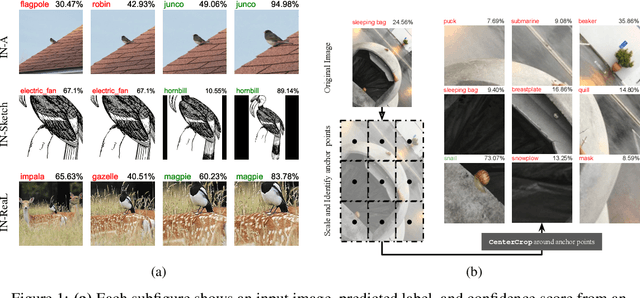



Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.
FlowFace++: Explicit Semantic Flow-supervised End-to-End Face Swapping
Jun 22, 2023


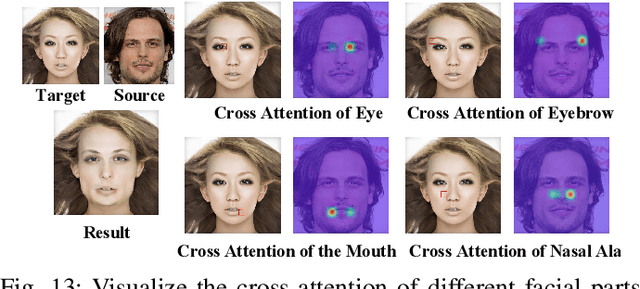
This work proposes a novel face-swapping framework FlowFace++, utilizing explicit semantic flow supervision and end-to-end architecture to facilitate shape-aware face-swapping. Specifically, our work pretrains a facial shape discriminator to supervise the face swapping network. The discriminator is shape-aware and relies on a semantic flow-guided operation to explicitly calculate the shape discrepancies between the target and source faces, thus optimizing the face swapping network to generate highly realistic results. The face swapping network is a stack of a pre-trained face-masked autoencoder (MAE), a cross-attention fusion module, and a convolutional decoder. The MAE provides a fine-grained facial image representation space, which is unified for the target and source faces and thus facilitates final realistic results. The cross-attention fusion module carries out the source-to-target face swapping in a fine-grained latent space while preserving other attributes of the target image (e.g. expression, head pose, hair, background, illumination, etc). Lastly, the convolutional decoder further synthesizes the swapping results according to the face-swapping latent embedding from the cross-attention fusion module. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace++ outperforms the state-of-the-art significantly, particularly while the source face is obstructed by uneven lighting or angle offset.
Deep learning estimation of modified Zernike coefficients for image point spread functions
Apr 05, 2023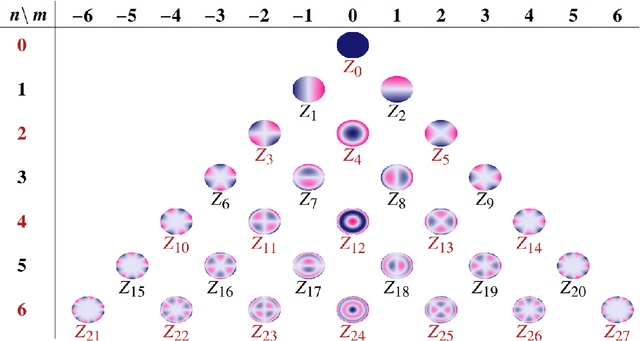
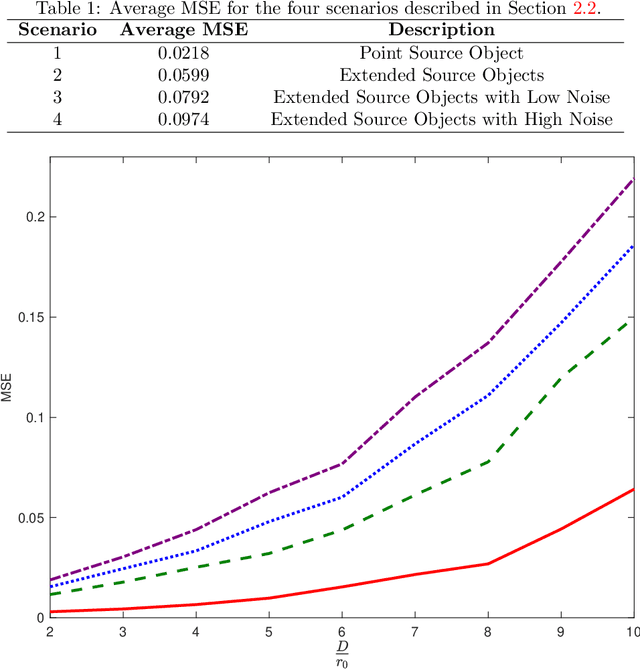
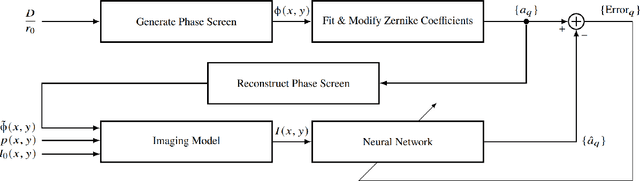
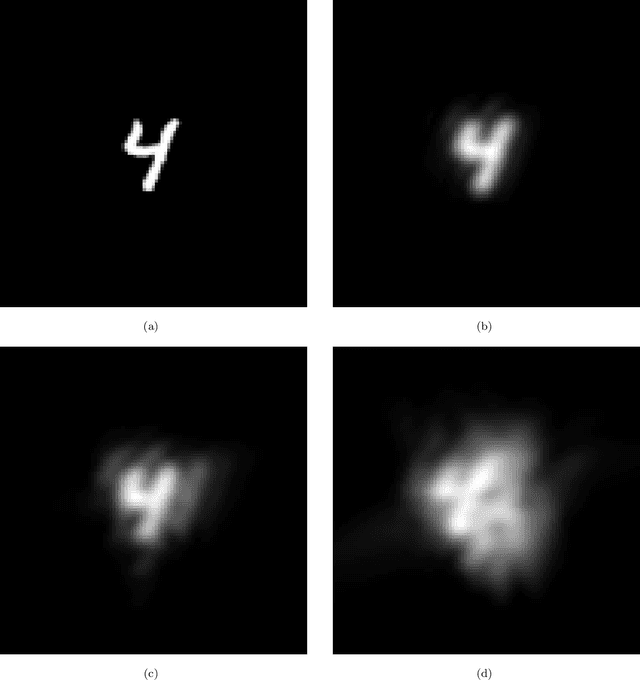
Recovering the turbulence-degraded point spread function from a single intensity image is important for a variety of imaging applications. Here, a deep learning model based on a convolution neural network is applied to intensity images to predict a modified set of Zernike polynomial coefficients corresponding to wavefront aberrations in the pupil due to turbulence. The modified set assigns an absolute value to coefficients of even radial orders due to a sign ambiguity associated with this problem and is shown to be sufficient for specifying the intensity point spread function. Simulated image data of a point object and simple extended objects over a range of turbulence and detection noise levels are created for the learning model. The MSE results for the learning model show that the best prediction is found when observing a point object, but it is possible to recover a useful set of modified Zernike coefficients from an extended object image that is subject to detection noise and turbulence.
DeepMIM: Deep Supervision for Masked Image Modeling
Mar 16, 2023Deep supervision, which involves extra supervisions to the intermediate features of a neural network, was widely used in image classification in the early deep learning era since it significantly reduces the training difficulty and eases the optimization like avoiding gradient vanish over the vanilla training. Nevertheless, with the emergence of normalization techniques and residual connection, deep supervision in image classification was gradually phased out. In this paper, we revisit deep supervision for masked image modeling (MIM) that pre-trains a Vision Transformer (ViT) via a mask-and-predict scheme. Experimentally, we find that deep supervision drives the shallower layers to learn more meaningful representations, accelerates model convergence, and expands attention diversities. Our approach, called DeepMIM, significantly boosts the representation capability of each layer. In addition, DeepMIM is compatible with many MIM models across a range of reconstruction targets. For instance, using ViT-B, DeepMIM on MAE achieves 84.2 top-1 accuracy on ImageNet, outperforming MAE by +0.6. By combining DeepMIM with a stronger tokenizer CLIP, our model achieves state-of-the-art performance on various downstream tasks, including image classification (85.6 top-1 accuracy on ImageNet-1K, outperforming MAE-CLIP by +0.8), object detection (52.8 APbox on COCO) and semantic segmentation (53.1 mIoU on ADE20K). Code and models are available at https://github.com/OliverRensu/DeepMIM.
EANet: Enhanced Attribute-based RGBT Tracker Network
Jul 04, 2023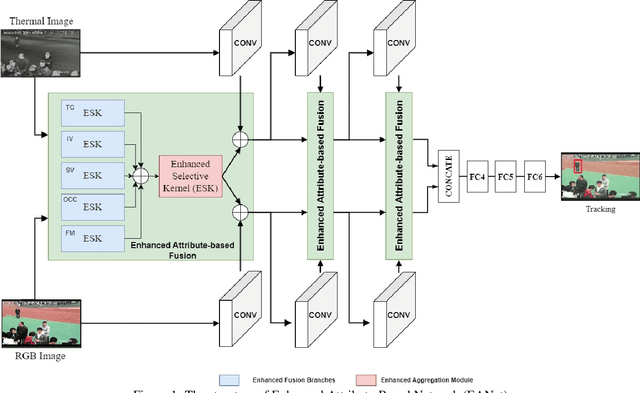
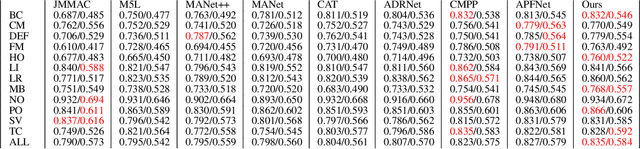
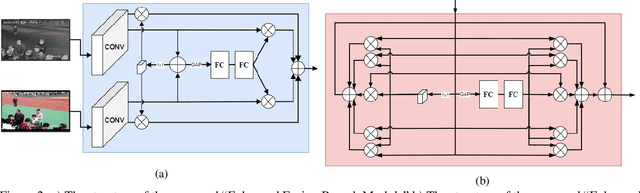
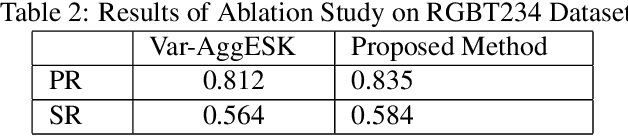
Tracking objects can be a difficult task in computer vision, especially when faced with challenges such as occlusion, changes in lighting, and motion blur. Recent advances in deep learning have shown promise in challenging these conditions. However, most deep learning-based object trackers only use visible band (RGB) images. Thermal infrared electromagnetic waves (TIR) can provide additional information about an object, including its temperature, when faced with challenging conditions. We propose a deep learning-based image tracking approach that fuses RGB and thermal images (RGBT). The proposed model consists of two main components: a feature extractor and a tracker. The feature extractor encodes deep features from both the RGB and the TIR images. The tracker then uses these features to track the object using an enhanced attribute-based architecture. We propose a fusion of attribute-specific feature selection with an aggregation module. The proposed methods are evaluated on the RGBT234 \cite{LiCLiang2018} and LasHeR \cite{LiLasher2021} datasets, which are the most widely used RGBT object-tracking datasets in the literature. The results show that the proposed system outperforms state-of-the-art RGBT object trackers on these datasets, with a relatively smaller number of parameters.