 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explainable Image Quality Assessment for Medical Imaging
Mar 25, 2023
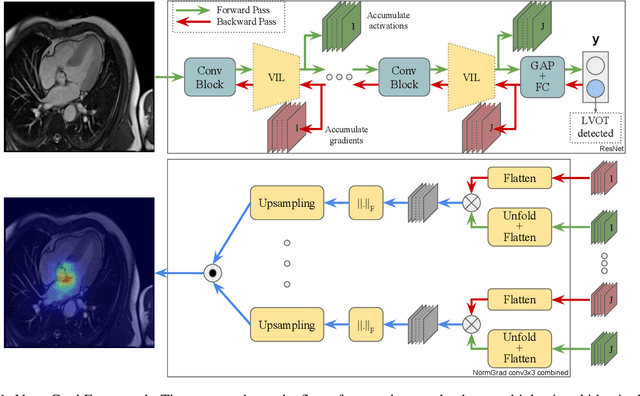

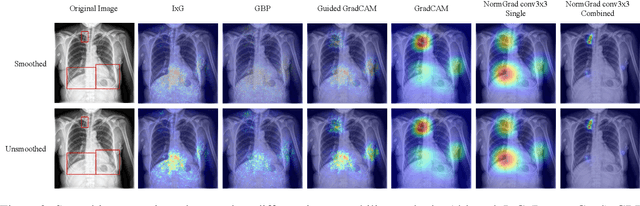
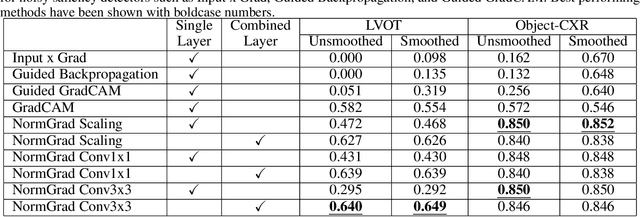
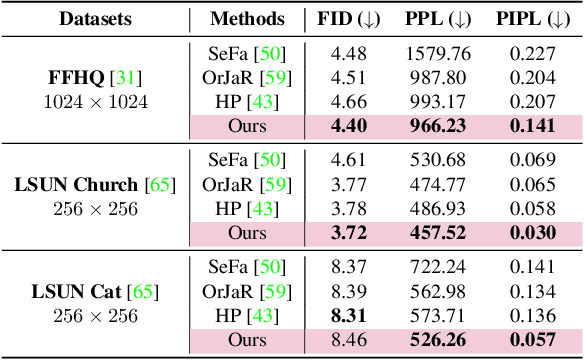
Medical image quality assessment is an important aspect of image acquisition, as poor-quality images may lead to misdiagnosis. Manual labelling of image quality is a tedious task for population studies and can lead to misleading results. While much research has been done on automated analysis of image quality to address this issue, relatively little work has been done to explain the methodologies. In this work, we propose an explainable image quality assessment system and validate our idea on two different objectives which are foreign object detection on Chest X-Rays (Object-CXR) and Left Ventricular Outflow Tract (LVOT) detection on Cardiac Magnetic Resonance (CMR) volumes. We apply a variety of techniques to measure the faithfulness of the saliency detectors, and our explainable pipeline relies on NormGrad, an algorithm which can efficiently localise image quality issues with saliency maps of the classifier. We compare NormGrad with a range of saliency detection methods and illustrate its superior performance as a result of applying these methodologies for measuring the faithfulness of the saliency detectors. We see that NormGrad has significant gains over other saliency detectors by reaching a repeated Pointing Game score of 0.853 for Object-CXR and 0.611 for LVOT datasets.
IRGen: Generative Modeling for Image Retrieval
Mar 27, 2023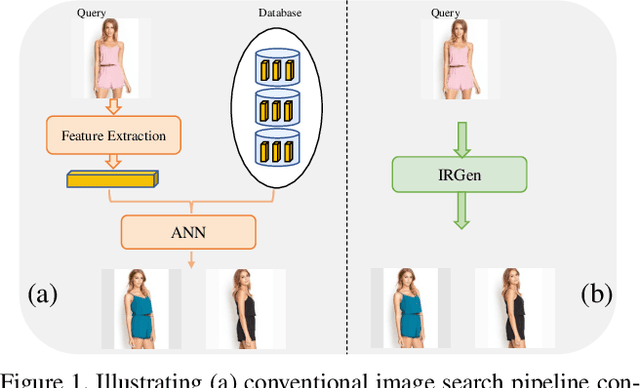
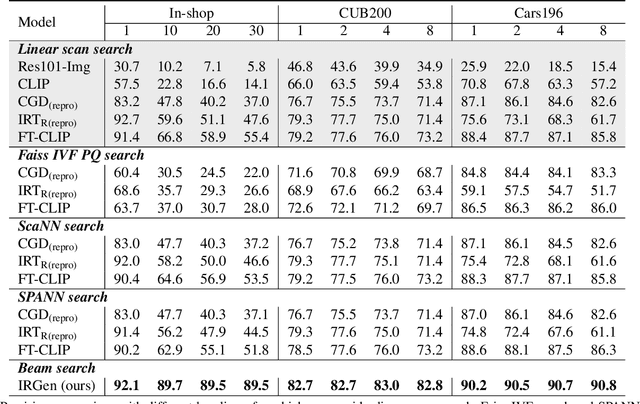
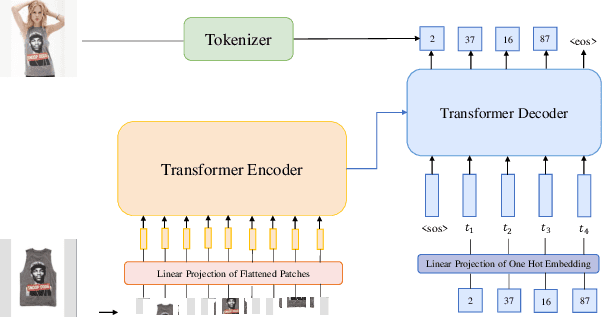
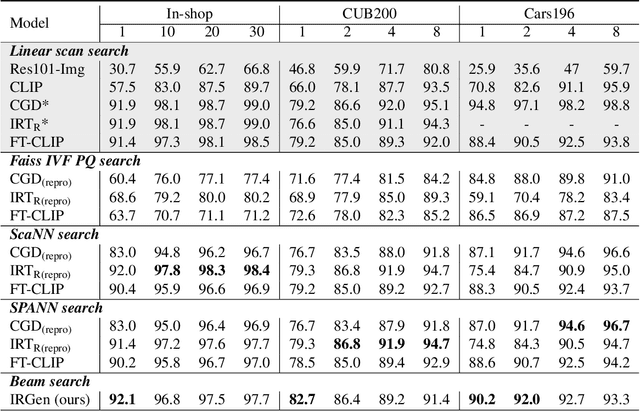
While generative modeling has been ubiquitous in natural language processing and computer vision, its application to image retrieval remains unexplored. In this paper, we recast image retrieval as a form of generative modeling by employing a sequence-to-sequence model, contributing to the current unified theme. Our framework, IRGen, is a unified model that enables end-to-end differentiable search, thus achieving superior performance thanks to direct optimization. While developing IRGen we tackle the key technical challenge of converting an image into quite a short sequence of semantic units in order to enable efficient and effective retrieval. Empirical experiments demonstrate that our model yields significant improvement over three commonly used benchmarks, for example, 22.9\% higher than the best baseline method in precision@10 on In-shop dataset with comparable recall@10 score.
RFR-WWANet: Weighted Window Attention-Based Recovery Feature Resolution Network for Unsupervised Image Registration
May 07, 2023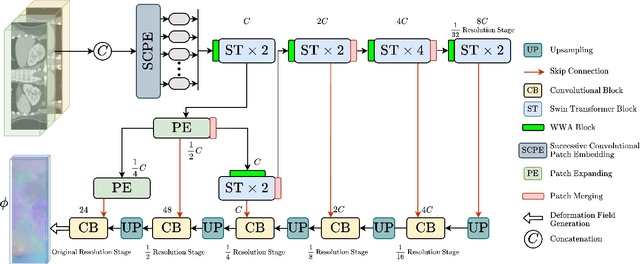
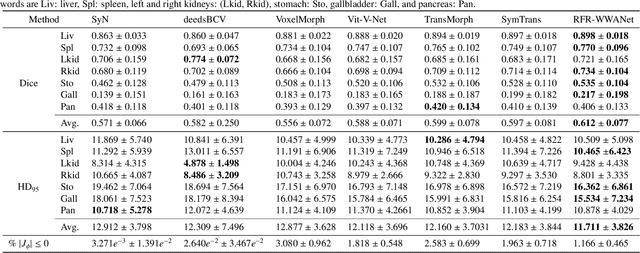
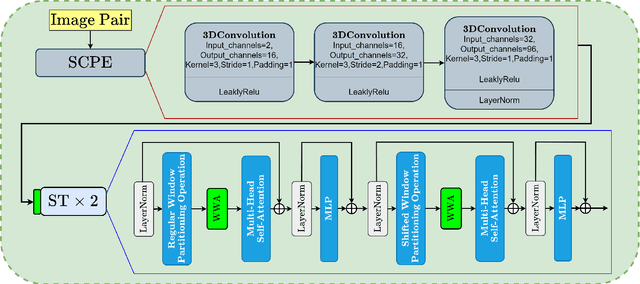
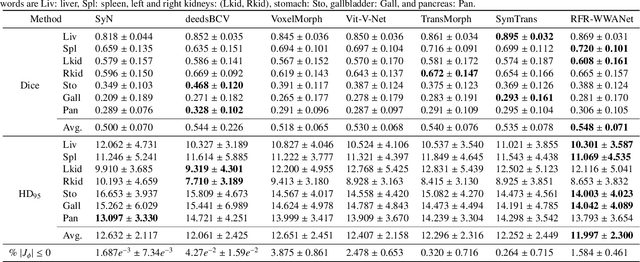
The Swin transformer has recently attracted attention in medical image analysis due to its computational efficiency and long-range modeling capability, which enables the establishment of more distant relationships between corresponding voxels. However, transformer-based models split images into tokens, which results in transformers that can only model and output coarse-grained spatial information representations. To address this issue, we propose Recovery Feature Resolution Network (RFRNet), which enables the transformer to contribute with fine-grained spatial information and rich semantic correspondences. Furthermore, shifted window partitioning operations are inflexible, indicating that they cannot perceive the semantic information over uncertain distances and automatically bridge the global connections between windows. Therefore, we present a Weighted Window Attention (WWA) to automatically build global interactions between windows after the regular and cyclic shifted window partitioning operations for Swin transformer blocks. The proposed unsupervised deformable image registration model, named RFR-WWANet, senses the long-range correlations, thereby facilitating meaningful semantic relevance of anatomical structures. Qualitative and quantitative results show that RFR-WWANet achieves significant performance improvements over baseline methods. Ablation experiments demonstrate the effectiveness of the RFRNet and WWA designs.
Discrepancy-Guided Reconstruction Learning for Image Forgery Detection
May 03, 2023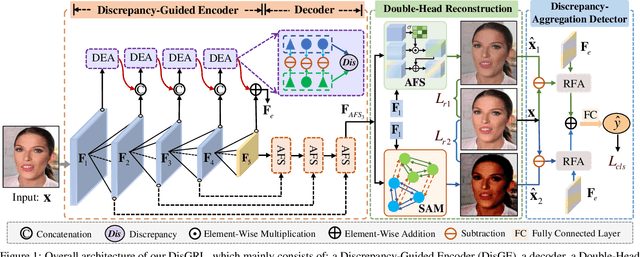
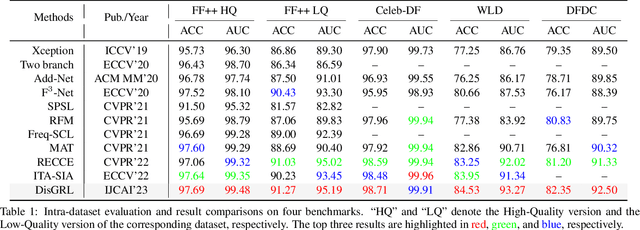
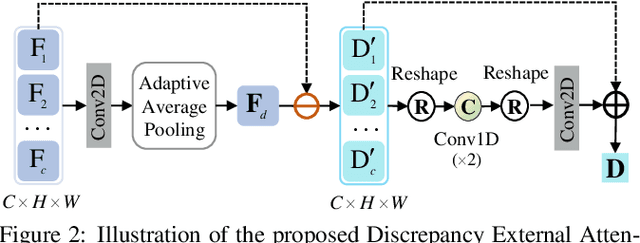
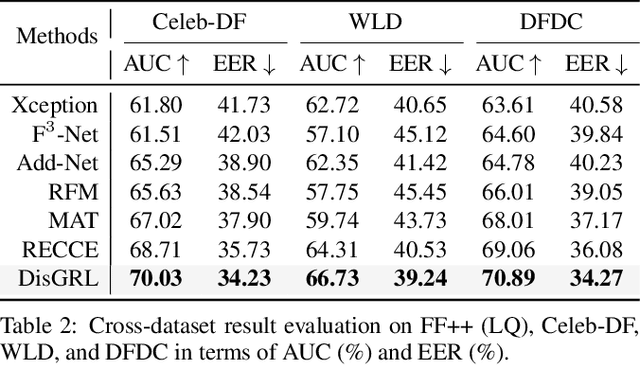
In this paper, we propose a novel image forgery detection paradigm for boosting the model learning capacity on both forgery-sensitive and genuine compact visual patterns. Compared to the existing methods that only focus on the discrepant-specific patterns (\eg, noises, textures, and frequencies), our method has a greater generalization. Specifically, we first propose a Discrepancy-Guided Encoder (DisGE) to extract forgery-sensitive visual patterns. DisGE consists of two branches, where the mainstream backbone branch is used to extract general semantic features, and the accessorial discrepant external attention branch is used to extract explicit forgery cues. Besides, a Double-Head Reconstruction (DouHR) module is proposed to enhance genuine compact visual patterns in different granular spaces. Under DouHR, we further introduce a Discrepancy-Aggregation Detector (DisAD) to aggregate these genuine compact visual patterns, such that the forgery detection capability on unknown patterns can be improved. Extensive experimental results on four challenging datasets validate the effectiveness of our proposed method against state-of-the-art competitors.
INVE: Interactive Neural Video Editing
Jul 15, 2023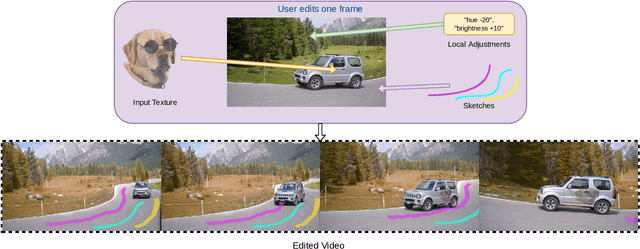
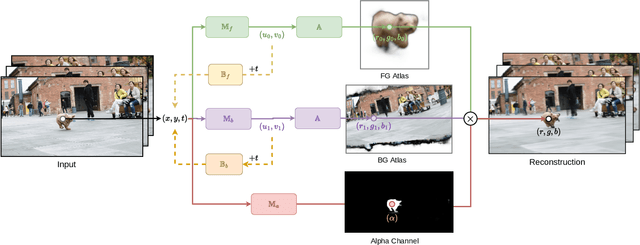
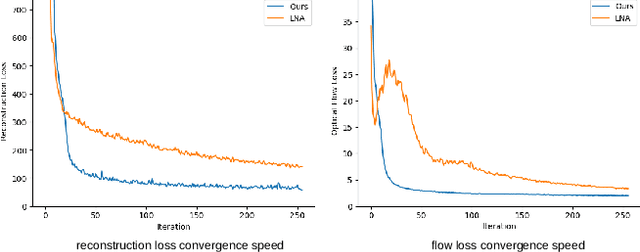
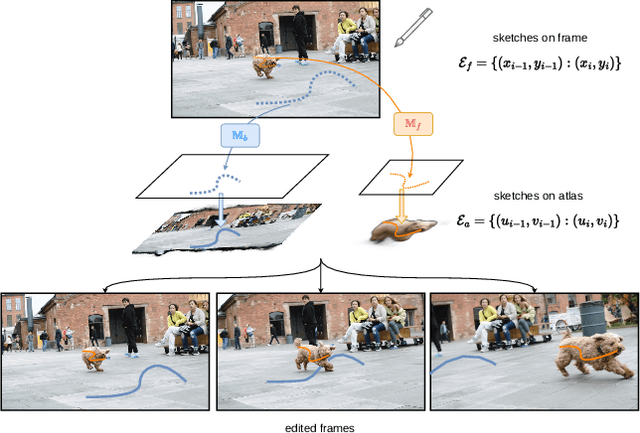
We present Interactive Neural Video Editing (INVE), a real-time video editing solution, which can assist the video editing process by consistently propagating sparse frame edits to the entire video clip. Our method is inspired by the recent work on Layered Neural Atlas (LNA). LNA, however, suffers from two major drawbacks: (1) the method is too slow for interactive editing, and (2) it offers insufficient support for some editing use cases, including direct frame editing and rigid texture tracking. To address these challenges we leverage and adopt highly efficient network architectures, powered by hash-grids encoding, to substantially improve processing speed. In addition, we learn bi-directional functions between image-atlas and introduce vectorized editing, which collectively enables a much greater variety of edits in both the atlas and the frames directly. Compared to LNA, our INVE reduces the learning and inference time by a factor of 5, and supports various video editing operations that LNA cannot. We showcase the superiority of INVE over LNA in interactive video editing through a comprehensive quantitative and qualitative analysis, highlighting its numerous advantages and improved performance. For video results, please see https://gabriel-huang.github.io/inve/
3D-aware Image Generation using 2D Diffusion Models
Mar 31, 2023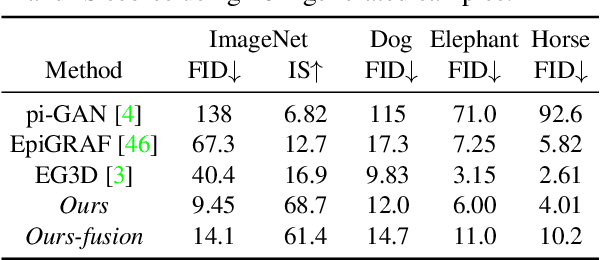
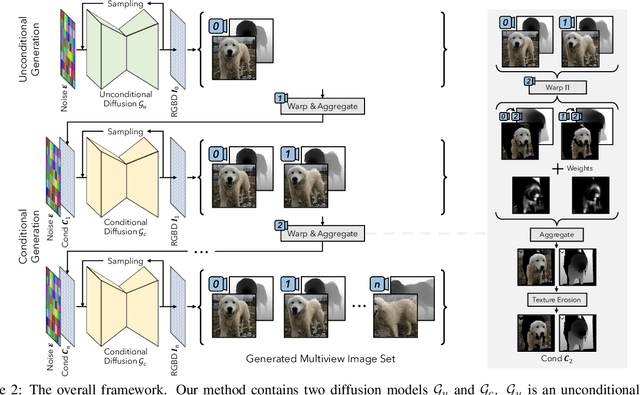
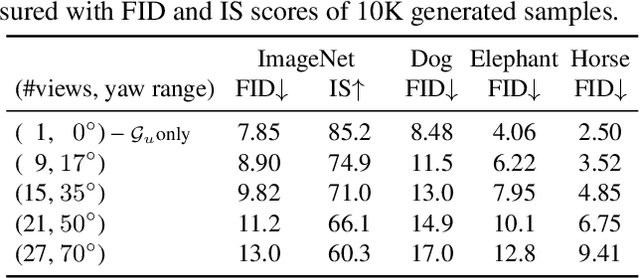
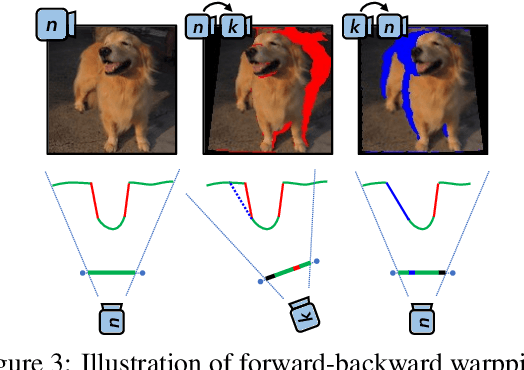
In this paper, we introduce a novel 3D-aware image generation method that leverages 2D diffusion models. We formulate the 3D-aware image generation task as multiview 2D image set generation, and further to a sequential unconditional-conditional multiview image generation process. This allows us to utilize 2D diffusion models to boost the generative modeling power of the method. Additionally, we incorporate depth information from monocular depth estimators to construct the training data for the conditional diffusion model using only still images. We train our method on a large-scale dataset, i.e., ImageNet, which is not addressed by previous methods. It produces high-quality images that significantly outperform prior methods. Furthermore, our approach showcases its capability to generate instances with large view angles, even though the training images are diverse and unaligned, gathered from "in-the-wild" real-world environments.
As large as it gets: Learning infinitely large Filters via Neural Implicit Functions in the Fourier Domain
Jul 19, 2023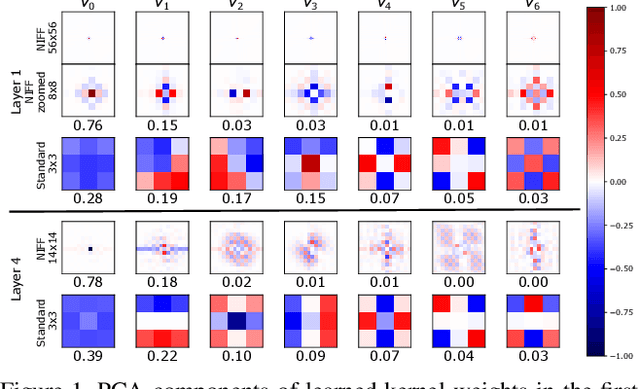
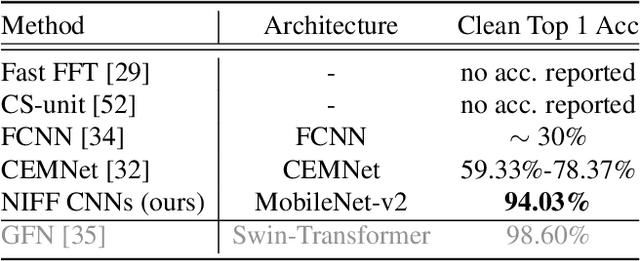
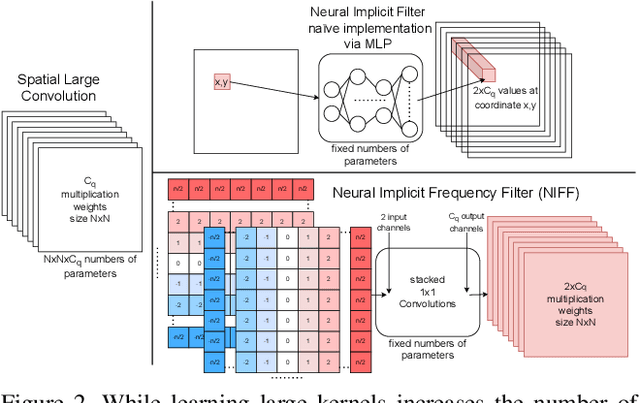
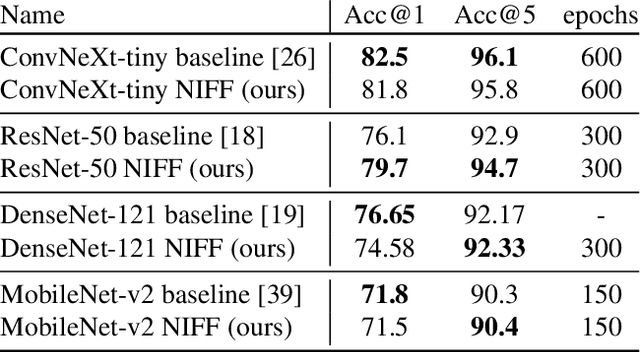
Motivated by the recent trend towards the usage of larger receptive fields for more context-aware neural networks in vision applications, we aim to investigate how large these receptive fields really need to be. To facilitate such study, several challenges need to be addressed, most importantly: (i) We need to provide an effective way for models to learn large filters (potentially as large as the input data) without increasing their memory consumption during training or inference, (ii) the study of filter sizes has to be decoupled from other effects such as the network width or number of learnable parameters, and (iii) the employed convolution operation should be a plug-and-play module that can replace any conventional convolution in a Convolutional Neural Network (CNN) and allow for an efficient implementation in current frameworks. To facilitate such models, we propose to learn not spatial but frequency representations of filter weights as neural implicit functions, such that even infinitely large filters can be parameterized by only a few learnable weights. The resulting neural implicit frequency CNNs are the first models to achieve results on par with the state-of-the-art on large image classification benchmarks while executing convolutions solely in the frequency domain and can be employed within any CNN architecture. They allow us to provide an extensive analysis of the learned receptive fields. Interestingly, our analysis shows that, although the proposed networks could learn very large convolution kernels, the learned filters practically translate into well-localized and relatively small convolution kernels in the spatial domain.
Householder Projector for Unsupervised Latent Semantics Discovery
Jul 16, 2023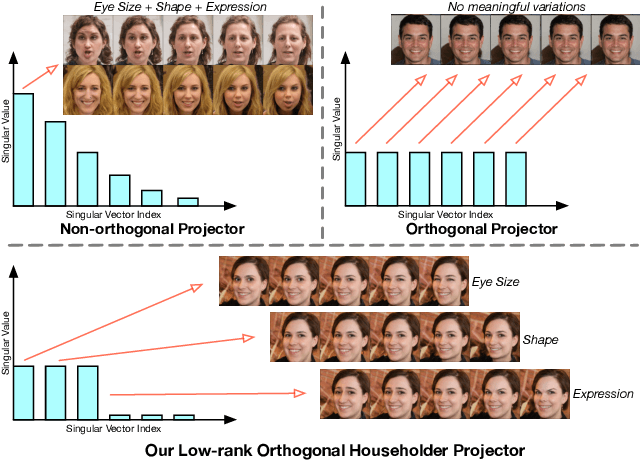


Generative Adversarial Networks (GANs), especially the recent style-based generators (StyleGANs), have versatile semantics in the structured latent space. Latent semantics discovery methods emerge to move around the latent code such that only one factor varies during the traversal. Recently, an unsupervised method proposed a promising direction to directly use the eigenvectors of the projection matrix that maps latent codes to features as the interpretable directions. However, one overlooked fact is that the projection matrix is non-orthogonal and the number of eigenvectors is too large. The non-orthogonality would entangle semantic attributes in the top few eigenvectors, and the large dimensionality might result in meaningless variations among the directions even if the matrix is orthogonal. To avoid these issues, we propose Householder Projector, a flexible and general low-rank orthogonal matrix representation based on Householder transformations, to parameterize the projection matrix. The orthogonality guarantees that the eigenvectors correspond to disentangled interpretable semantics, while the low-rank property encourages that each identified direction has meaningful variations. We integrate our projector into pre-trained StyleGAN2/StyleGAN3 and evaluate the models on several benchmarks. Within only $1\%$ of the original training steps for fine-tuning, our projector helps StyleGANs to discover more disentangled and precise semantic attributes without sacrificing image fidelity.
DreamTime: An Improved Optimization Strategy for Text-to-3D Content Creation
Jun 21, 2023Text-to-image diffusion models pre-trained on billions of image-text pairs have recently enabled text-to-3D content creation by optimizing a randomly initialized Neural Radiance Fields (NeRF) with score distillation. However, the resultant 3D models exhibit two limitations: (a) quality concerns such as saturated color and the Janus problem; (b) extremely low diversity comparing to text-guided image synthesis. In this paper, we show that the conflict between NeRF optimization process and uniform timestep sampling in score distillation is the main reason for these limitations. To resolve this conflict, we propose to prioritize timestep sampling with monotonically non-increasing functions, which aligns NeRF optimization with the sampling process of diffusion model. Extensive experiments show that our simple redesign significantly improves text-to-3D content creation with higher quality and diversity.
Multi-class point cloud completion networks for 3D cardiac anatomy reconstruction from cine magnetic resonance images
Jul 18, 2023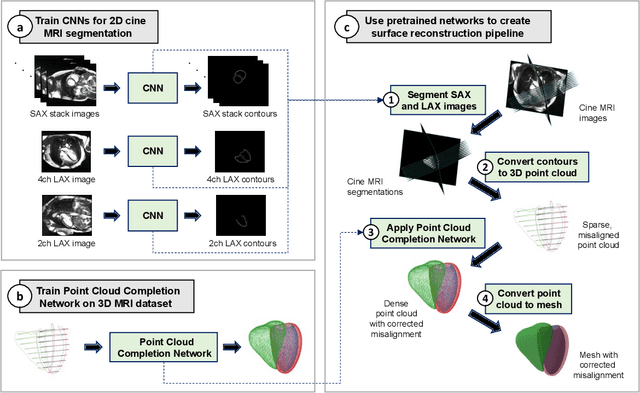
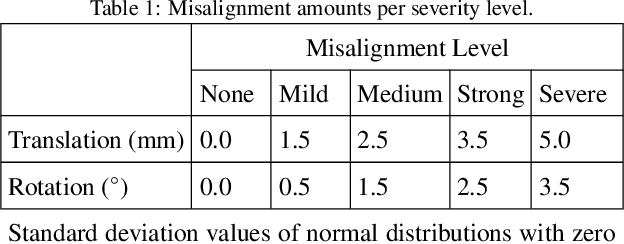
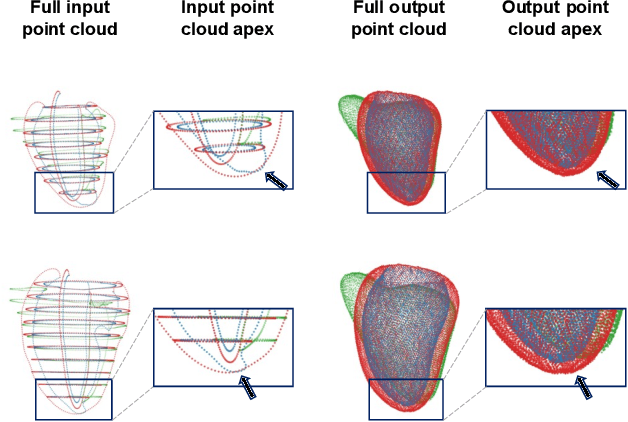
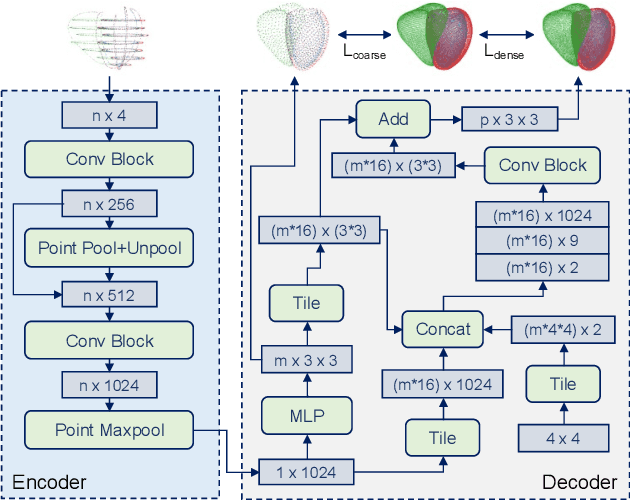
Cine magnetic resonance imaging (MRI) is the current gold standard for the assessment of cardiac anatomy and function. However, it typically only acquires a set of two-dimensional (2D) slices of the underlying three-dimensional (3D) anatomy of the heart, thus limiting the understanding and analysis of both healthy and pathological cardiac morphology and physiology. In this paper, we propose a novel fully automatic surface reconstruction pipeline capable of reconstructing multi-class 3D cardiac anatomy meshes from raw cine MRI acquisitions. Its key component is a multi-class point cloud completion network (PCCN) capable of correcting both the sparsity and misalignment issues of the 3D reconstruction task in a unified model. We first evaluate the PCCN on a large synthetic dataset of biventricular anatomies and observe Chamfer distances between reconstructed and gold standard anatomies below or similar to the underlying image resolution for multiple levels of slice misalignment. Furthermore, we find a reduction in reconstruction error compared to a benchmark 3D U-Net by 32% and 24% in terms of Hausdorff distance and mean surface distance, respectively. We then apply the PCCN as part of our automated reconstruction pipeline to 1000 subjects from the UK Biobank study in a cross-domain transfer setting and demonstrate its ability to reconstruct accurate and topologically plausible biventricular heart meshes with clinical metrics comparable to the previous literature. Finally, we investigate the robustness of our proposed approach and observe its capacity to successfully handle multiple common outlier conditions.