 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parameter-Efficient Long-Tailed Recognition
Sep 18, 2023
The "pre-training and fine-tuning" paradigm in addressing long-tailed recognition tasks has sparked significant interest since the emergence of large vision-language models like the contrastive language-image pre-training (CLIP). While previous studies have shown promise in adapting pre-trained models for these tasks, they often undesirably require extensive training epochs or additional training data to maintain good performance. In this paper, we propose PEL, a fine-tuning method that can effectively adapt pre-trained models to long-tailed recognition tasks in fewer than 20 epochs without the need for extra data. We first empirically find that commonly used fine-tuning methods, such as full fine-tuning and classifier fine-tuning, suffer from overfitting, resulting in performance deterioration on tail classes. To mitigate this issue, PEL introduces a small number of task-specific parameters by adopting the design of any existing parameter-efficient fine-tuning method. Additionally, to expedite convergence, PEL presents a novel semantic-aware classifier initialization technique derived from the CLIP textual encoder without adding any computational overhead. Our experimental results on four long-tailed datasets demonstrate that PEL consistently outperforms previous state-of-the-art approaches. The source code is available at https://github.com/shijxcs/PEL.
Face-Driven Zero-Shot Voice Conversion with Memory-based Face-Voice Alignment
Sep 18, 2023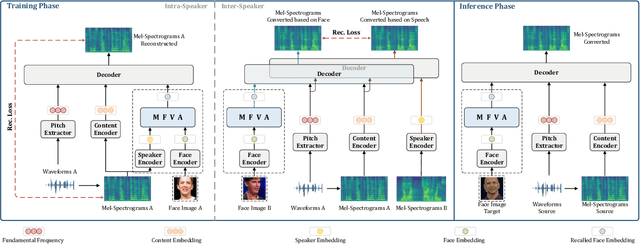
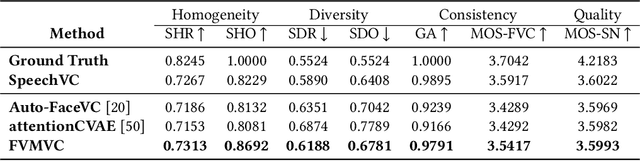
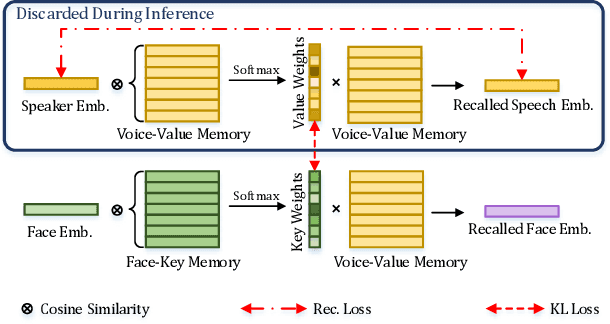
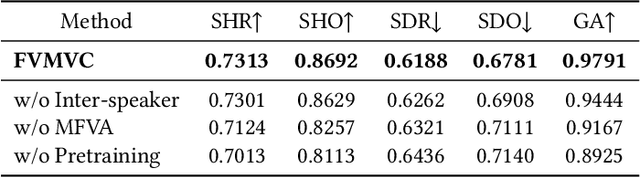
This paper presents a novel task, zero-shot voice conversion based on face images (zero-shot FaceVC), which aims at converting the voice characteristics of an utterance from any source speaker to a newly coming target speaker, solely relying on a single face image of the target speaker. To address this task, we propose a face-voice memory-based zero-shot FaceVC method. This method leverages a memory-based face-voice alignment module, in which slots act as the bridge to align these two modalities, allowing for the capture of voice characteristics from face images. A mixed supervision strategy is also introduced to mitigate the long-standing issue of the inconsistency between training and inference phases for voice conversion tasks. To obtain speaker-independent content-related representations, we transfer the knowledge from a pretrained zero-shot voice conversion model to our zero-shot FaceVC model. Considering the differences between FaceVC and traditional voice conversion tasks, systematic subjective and objective metrics are designed to thoroughly evaluate the homogeneity, diversity and consistency of voice characteristics controlled by face images. Through extensive experiments, we demonstrate the superiority of our proposed method on the zero-shot FaceVC task. Samples are presented on our demo website.
Causal Scoring Medical Image Explanations: A Case Study On Ex-vivo Kidney Stone Images
Sep 05, 2023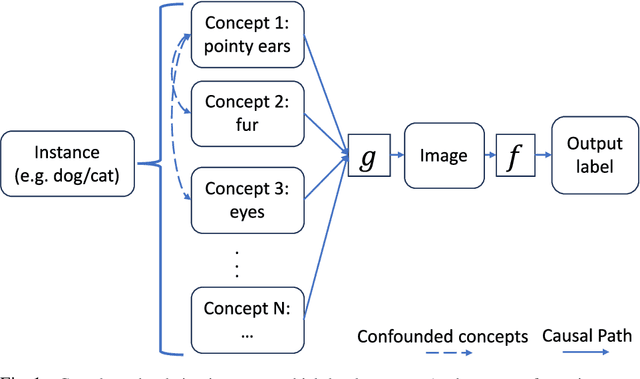

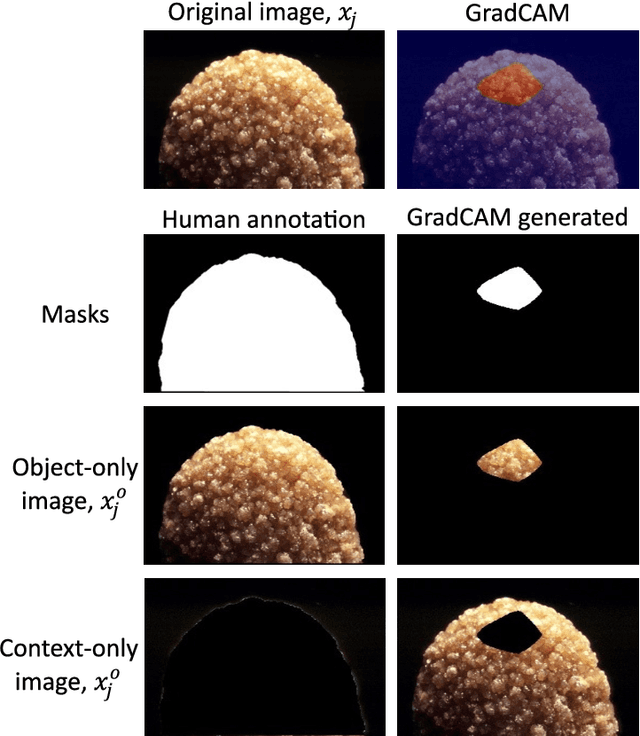
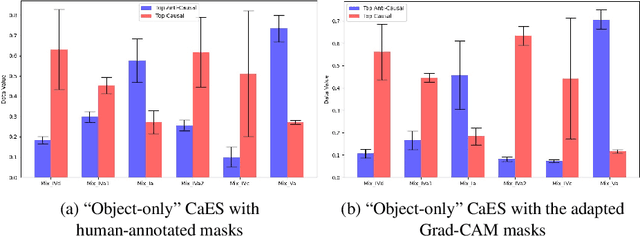
On the promise that if human users know the cause of an output, it would enable them to grasp the process responsible for the output, and hence provide understanding, many explainable methods have been proposed to indicate the cause for the output of a model based on its input. Nonetheless, little has been reported on quantitative measurements of such causal relationships between the inputs, the explanations, and the outputs of a model, leaving the assessment to the user, independent of his level of expertise in the subject. To address this situation, we explore a technique for measuring the causal relationship between the features from the area of the object of interest in the images of a class and the output of a classifier. Our experiments indicate improvement in the causal relationships measured when the area of the object of interest per class is indicated by a mask from an explainable method than when it is indicated by human annotators. Hence the chosen name of Causal Explanation Score (CaES)
Image Denoising and the Generative Accumulation of Photons
Jul 13, 2023
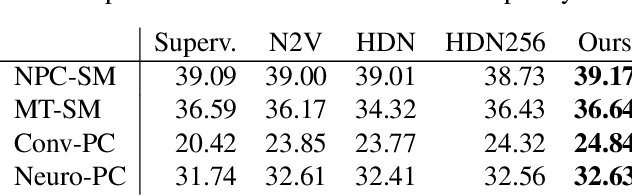
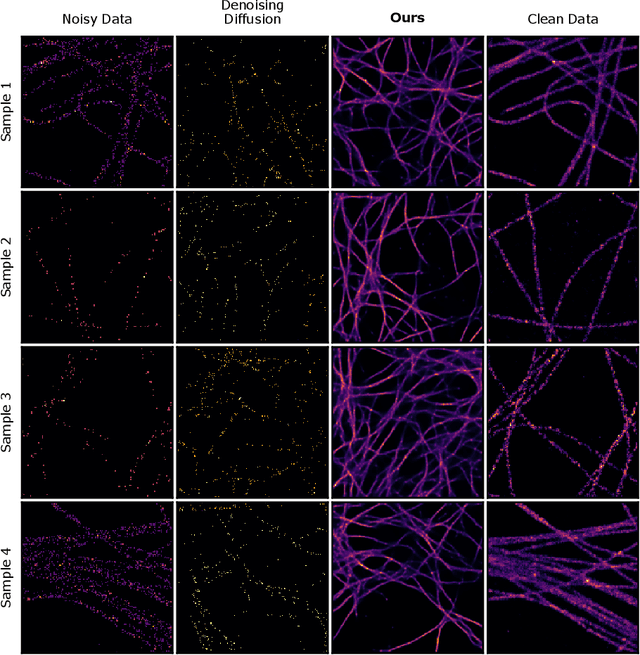

We present a fresh perspective on shot noise corrupted images and noise removal. By viewing image formation as the sequential accumulation of photons on a detector grid, we show that a network trained to predict where the next photon could arrive is in fact solving the minimum mean square error (MMSE) denoising task. This new perspective allows us to make three contributions: We present a new strategy for self-supervised denoising, We present a new method for sampling from the posterior of possible solutions by iteratively sampling and adding small numbers of photons to the image. We derive a full generative model by starting this process from an empty canvas. We evaluate our method quantitatively and qualitatively on 4 new fluorescence microscopy datasets, which will be made available to the community. We find that it outperforms supervised, self-supervised and unsupervised baselines or performs on-par.
CoNeS: Conditional neural fields with shift modulation for multi-sequence MRI translation
Sep 06, 2023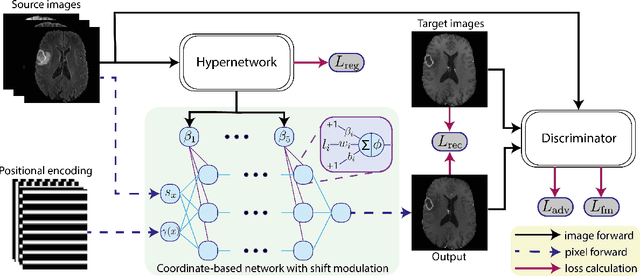
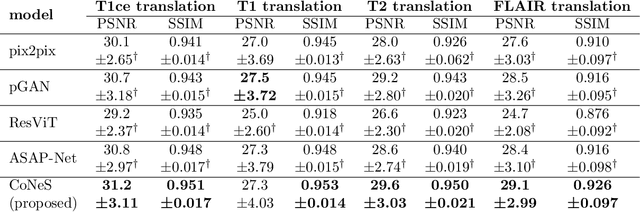
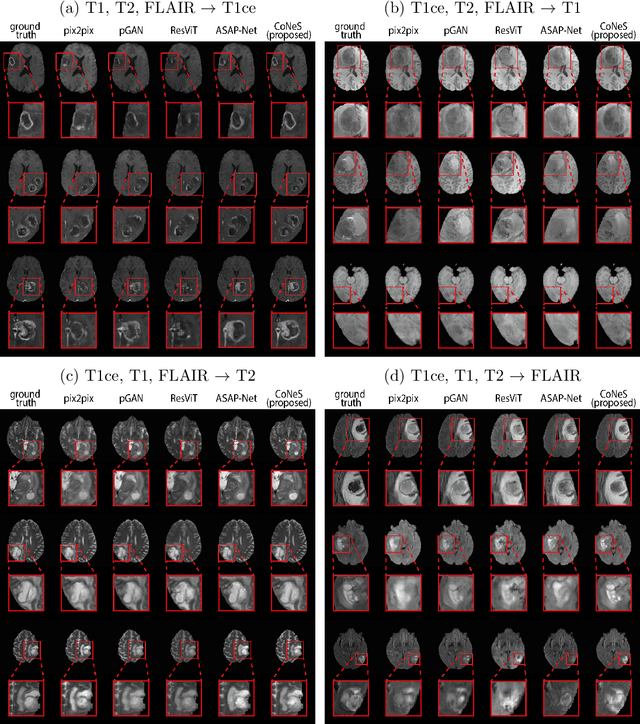
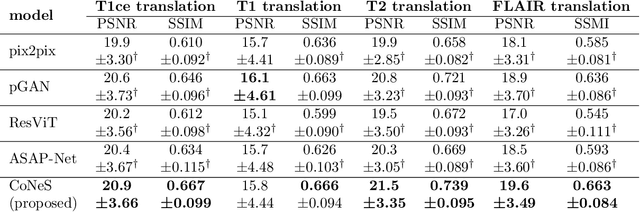
Multi-sequence magnetic resonance imaging (MRI) has found wide applications in both modern clinical studies and deep learning research. However, in clinical practice, it frequently occurs that one or more of the MRI sequences are missing due to different image acquisition protocols or contrast agent contraindications of patients, limiting the utilization of deep learning models trained on multi-sequence data. One promising approach is to leverage generative models to synthesize the missing sequences, which can serve as a surrogate acquisition. State-of-the-art methods tackling this problem are based on convolutional neural networks (CNN) which usually suffer from spectral biases, resulting in poor reconstruction of high-frequency fine details. In this paper, we propose Conditional Neural fields with Shift modulation (CoNeS), a model that takes voxel coordinates as input and learns a representation of the target images for multi-sequence MRI translation. The proposed model uses a multi-layer perceptron (MLP) instead of a CNN as the decoder for pixel-to-pixel mapping. Hence, each target image is represented as a neural field that is conditioned on the source image via shift modulation with a learned latent code. Experiments on BraTS 2018 and an in-house clinical dataset of vestibular schwannoma patients showed that the proposed method outperformed state-of-the-art methods for multi-sequence MRI translation both visually and quantitatively. Moreover, we conducted spectral analysis, showing that CoNeS was able to overcome the spectral bias issue common in conventional CNN models. To further evaluate the usage of synthesized images in clinical downstream tasks, we tested a segmentation network using the synthesized images at inference.
FDCNet: Feature Drift Compensation Network for Class-Incremental Weakly Supervised Object Localization
Sep 17, 2023
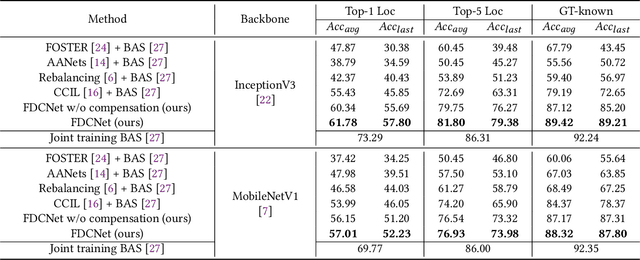
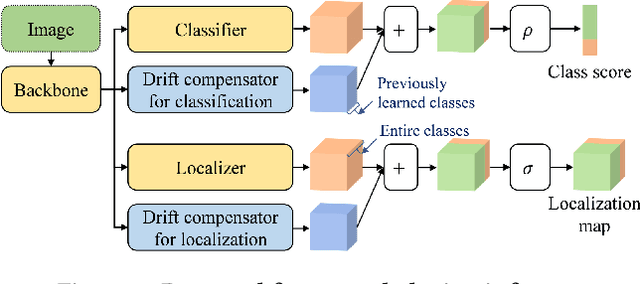
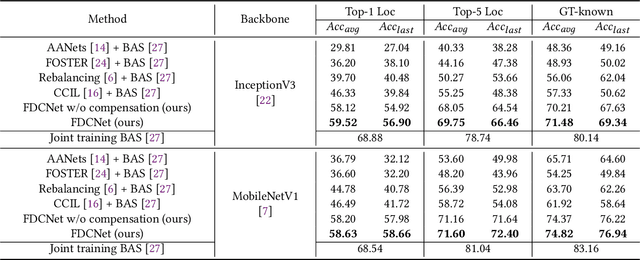
This work addresses the task of class-incremental weakly supervised object localization (CI-WSOL). The goal is to incrementally learn object localization for novel classes using only image-level annotations while retaining the ability to localize previously learned classes. This task is important because annotating bounding boxes for every new incoming data is expensive, although object localization is crucial in various applications. To the best of our knowledge, we are the first to address this task. Thus, we first present a strong baseline method for CI-WSOL by adapting the strategies of class-incremental classifiers to mitigate catastrophic forgetting. These strategies include applying knowledge distillation, maintaining a small data set from previous tasks, and using cosine normalization. We then propose the feature drift compensation network to compensate for the effects of feature drifts on class scores and localization maps. Since updating network parameters to learn new tasks causes feature drifts, compensating for the final outputs is necessary. Finally, we evaluate our proposed method by conducting experiments on two publicly available datasets (ImageNet-100 and CUB-200). The experimental results demonstrate that the proposed method outperforms other baseline methods.
T2I-CompBench: A Comprehensive Benchmark for Open-world Compositional Text-to-image Generation
Jul 12, 2023
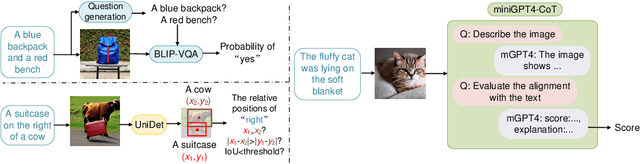
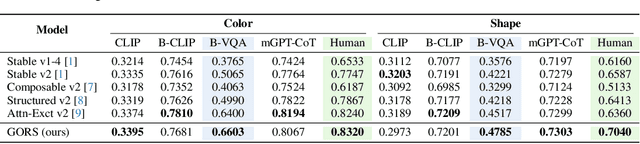
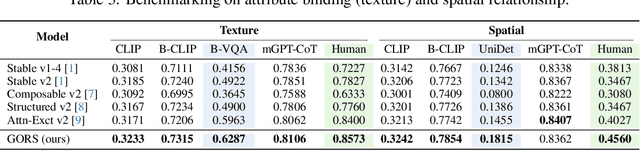
Despite the stunning ability to generate high-quality images by recent text-to-image models, current approaches often struggle to effectively compose objects with different attributes and relationships into a complex and coherent scene. We propose T2I-CompBench, a comprehensive benchmark for open-world compositional text-to-image generation, consisting of 6,000 compositional text prompts from 3 categories (attribute binding, object relationships, and complex compositions) and 6 sub-categories (color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions). We further propose several evaluation metrics specifically designed to evaluate compositional text-to-image generation. We introduce a new approach, Generative mOdel fine-tuning with Reward-driven Sample selection (GORS), to boost the compositional text-to-image generation abilities of pretrained text-to-image models. Extensive experiments and evaluations are conducted to benchmark previous methods on T2I-CompBench, and to validate the effectiveness of our proposed evaluation metrics and GORS approach. Project page is available at https://karine-h.github.io/T2I-CompBench/.
ARTxAI: Explainable Artificial Intelligence Curates Deep Representation Learning for Artistic Images using Fuzzy Techniques
Aug 29, 2023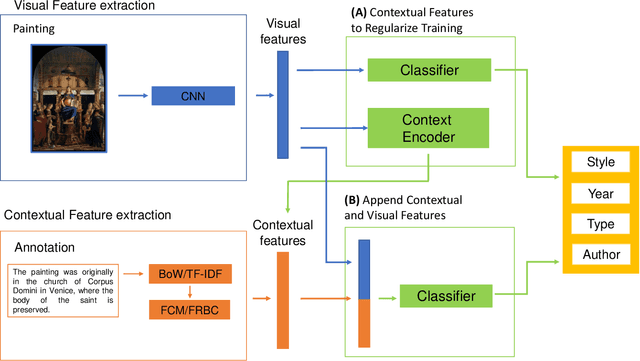
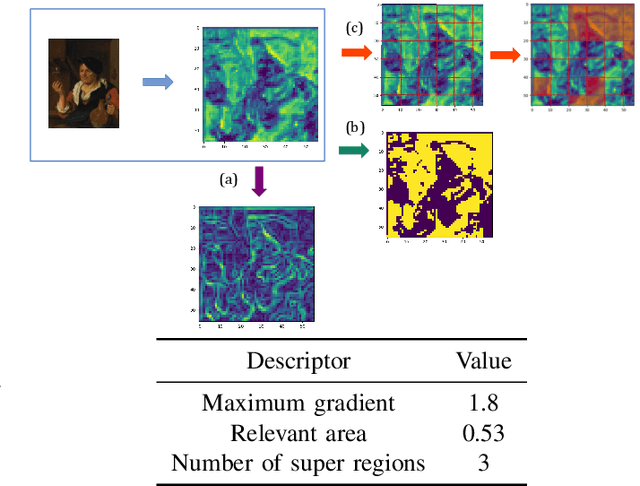
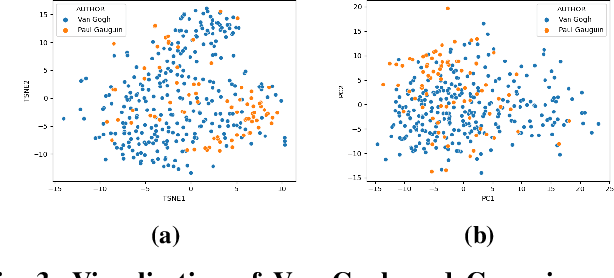

Automatic art analysis employs different image processing techniques to classify and categorize works of art. When working with artistic images, we need to take into account further considerations compared to classical image processing. This is because such artistic paintings change drastically depending on the author, the scene depicted, and their artistic style. This can result in features that perform very well in a given task but do not grasp the whole of the visual and symbolic information contained in a painting. In this paper, we show how the features obtained from different tasks in artistic image classification are suitable to solve other ones of similar nature. We present different methods to improve the generalization capabilities and performance of artistic classification systems. Furthermore, we propose an explainable artificial intelligence method to map known visual traits of an image with the features used by the deep learning model considering fuzzy rules. These rules show the patterns and variables that are relevant to solve each task and how effective is each of the patterns found. Our results show that our proposed context-aware features can achieve up to $6\%$ and $26\%$ more accurate results than other context- and non-context-aware solutions, respectively, depending on the specific task. We also show that some of the features used by these models can be more clearly correlated to visual traits in the original image than others.
Depth Completion with Multiple Balanced Bases and Confidence for Dense Monocular SLAM
Sep 20, 2023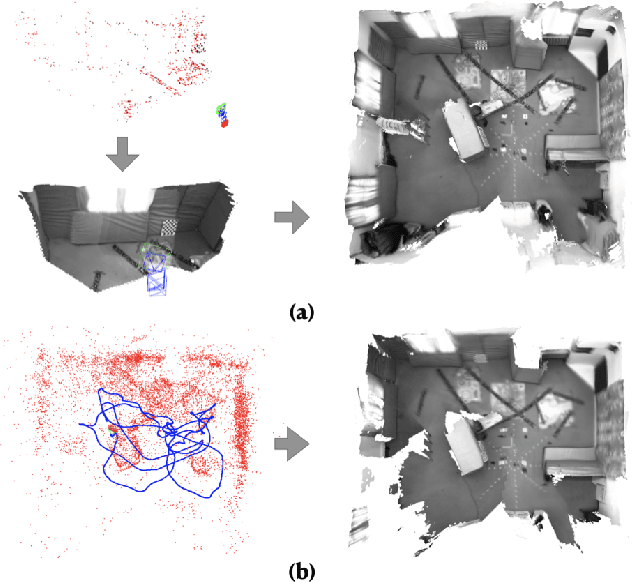



Dense SLAM based on monocular cameras does indeed have immense application value in the field of AR/VR, especially when it is performed on a mobile device. In this paper, we propose a novel method that integrates a light-weight depth completion network into a sparse SLAM system using a multi-basis depth representation, so that dense mapping can be performed online even on a mobile phone. Specifically, we present a specifically optimized multi-basis depth completion network, called BBC-Net, tailored to the characteristics of traditional sparse SLAM systems. BBC-Net can predict multiple balanced bases and a confidence map from a monocular image with sparse points generated by off-the-shelf keypoint-based SLAM systems. The final depth is a linear combination of predicted depth bases that can be optimized by tuning the corresponding weights. To seamlessly incorporate the weights into traditional SLAM optimization and ensure efficiency and robustness, we design a set of depth weight factors, which makes our network a versatile plug-in module, facilitating easy integration into various existing sparse SLAM systems and significantly enhancing global depth consistency through bundle adjustment. To verify the portability of our method, we integrate BBC-Net into two representative SLAM systems. The experimental results on various datasets show that the proposed method achieves better performance in monocular dense mapping than the state-of-the-art methods. We provide an online demo running on a mobile phone, which verifies the efficiency and mapping quality of the proposed method in real-world scenarios.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023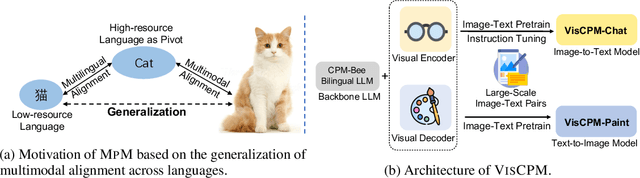
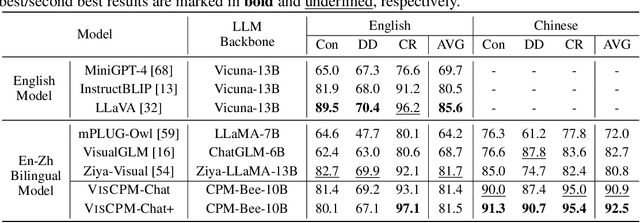
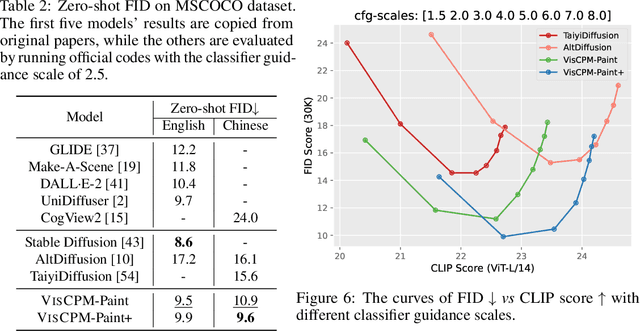
Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.