 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic dental superimposition of 3D intraorals and 2D photographs for human identification
Apr 07, 2026Dental comparison is considered a primary identification method, at the level of fingerprints and DNA profiling. One crucial but time-consuming step of this method is the morphological comparison. One of the main challenges to apply this method is the lack of ante-mortem medical records, specially on scenarios such as migrant death at the border and/or in countries where there is no universal healthcare. The availability of photos on social media where teeth are visible has led many odontologists to consider morphological comparison using them. However, state-of-the-art proposals have significant limitations, including the lack of proper modeling of perspective distortion and the absence of objective approaches that quantify morphological differences. Our proposal involves a 3D (post-mortem scan) - 2D (ante-mortem photos) approach. Using computer vision and optimization techniques, we replicate the ante-mortem image with the 3D model to perform the morphological comparison. Two automatic approaches have been developed: i) using paired landmarks and ii) using a segmentation of the teeth region to estimate camera parameters. Both are capable of obtaining very promising results over 20,164 cross comparisons from 142 samples, obtaining mean ranking values of 1.6 and 1.5, respectively. These results clearly outperform filtering capabilities of automatic dental chart comparison approaches, while providing an automatic, objective and quantitative score of the morphological correspondence, easily to interpret and analyze by visualizing superimposed images.
On the use of Aggregation Operators to improve Human Identification using Dental Records
Mar 24, 2026The comparison of dental records is a standardized technique in forensic dentistry used to speed up the identification of individuals in multiple-comparison scenarios. Specifically, the odontogram comparison is a procedure to compute criteria that will be used to perform a ranking. State-of-the-art automatic methods either make use of simple techniques, without utilizing the full potential of the information obtained from a comparison, or their internal behavior is not known due to the lack of peer-reviewed publications. This work aims to design aggregation mechanisms to automatically compare pairs of dental records that can be understood and validated by experts, improving the current methods. To do so, we introduce different aggregation approaches using the state-of-the-art codification, based on seven different criteria. In particular, we study the performance of i) data-driven lexicographical order-based aggregations, ii) well-known fuzzy logic aggregation methods and iii) machine learning techniques as aggregation mechanisms. To validate our proposals, 215 forensic cases from two different populations have been used. The results obtained show how the use of white-box machine learning techniques as aggregation models (average ranking from 2.02 to 2.21) are able to improve the state-of-the-art (average ranking of 3.91) without compromising the explainability and interpretability of the method.
Don't Forget your Inverse DDIM for Image Editing
May 14, 2025



The field of text-to-image generation has undergone significant advancements with the introduction of diffusion models. Nevertheless, the challenge of editing real images persists, as most methods are either computationally intensive or produce poor reconstructions. This paper introduces SAGE (Self-Attention Guidance for image Editing) - a novel technique leveraging pre-trained diffusion models for image editing. SAGE builds upon the DDIM algorithm and incorporates a novel guidance mechanism utilizing the self-attention layers of the diffusion U-Net. This mechanism computes a reconstruction objective based on attention maps generated during the inverse DDIM process, enabling efficient reconstruction of unedited regions without the need to precisely reconstruct the entire input image. Thus, SAGE directly addresses the key challenges in image editing. The superiority of SAGE over other methods is demonstrated through quantitative and qualitative evaluations and confirmed by a statistically validated comprehensive user study, in which all 47 surveyed users preferred SAGE over competing methods. Additionally, SAGE ranks as the top-performing method in seven out of 10 quantitative analyses and secures second and third places in the remaining three.
ARTxAI: Explainable Artificial Intelligence Curates Deep Representation Learning for Artistic Images using Fuzzy Techniques
Aug 29, 2023



Automatic art analysis employs different image processing techniques to classify and categorize works of art. When working with artistic images, we need to take into account further considerations compared to classical image processing. This is because such artistic paintings change drastically depending on the author, the scene depicted, and their artistic style. This can result in features that perform very well in a given task but do not grasp the whole of the visual and symbolic information contained in a painting. In this paper, we show how the features obtained from different tasks in artistic image classification are suitable to solve other ones of similar nature. We present different methods to improve the generalization capabilities and performance of artistic classification systems. Furthermore, we propose an explainable artificial intelligence method to map known visual traits of an image with the features used by the deep learning model considering fuzzy rules. These rules show the patterns and variables that are relevant to solve each task and how effective is each of the patterns found. Our results show that our proposed context-aware features can achieve up to $6\%$ and $26\%$ more accurate results than other context- and non-context-aware solutions, respectively, depending on the specific task. We also show that some of the features used by these models can be more clearly correlated to visual traits in the original image than others.
The Concept of Semantic Value in Social Network Analysis: an Application to Comparative Mythology
Sep 13, 2021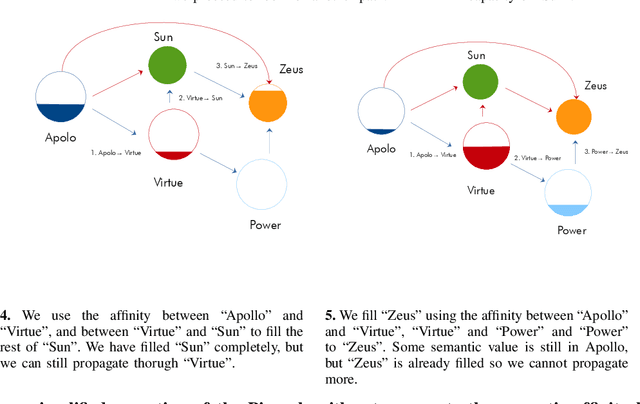
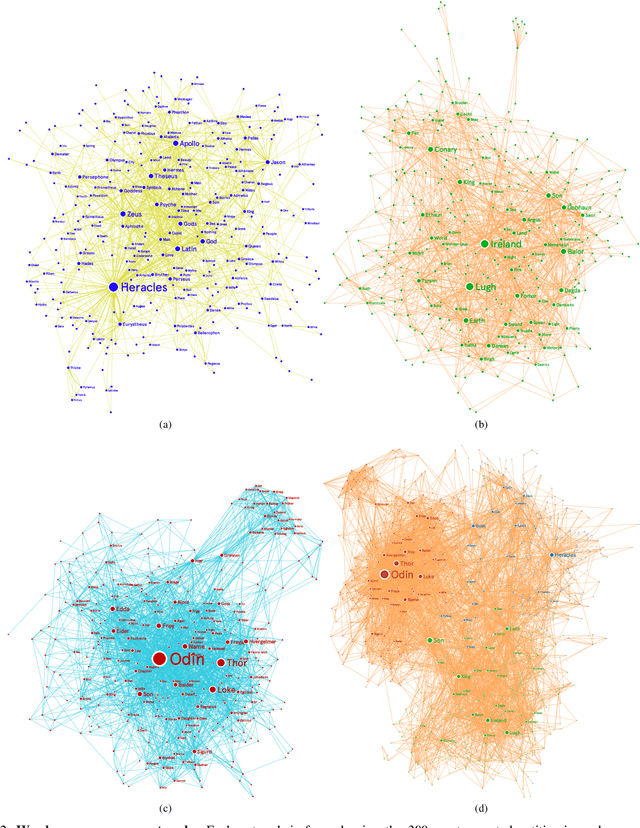
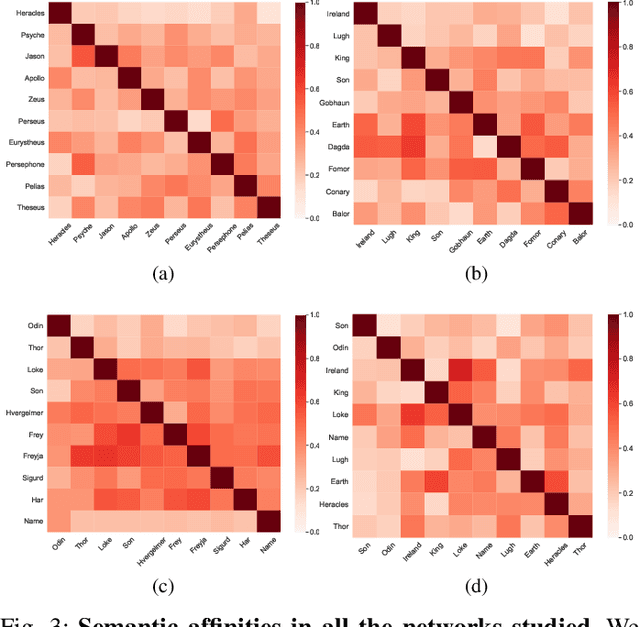
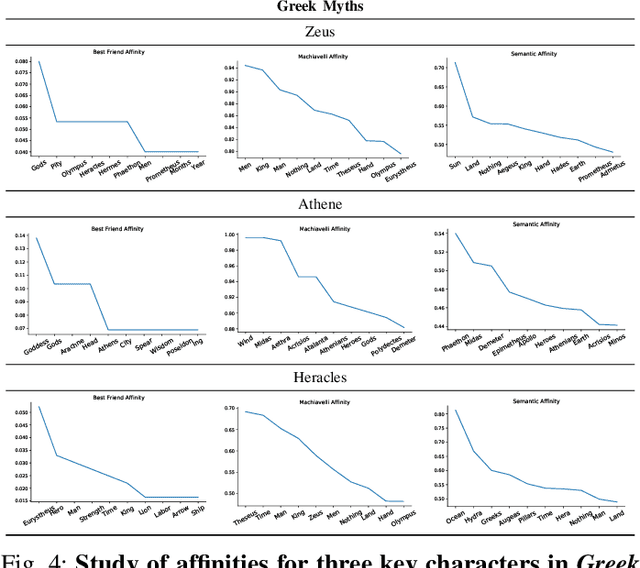
Human sciences have traditionally relied on human reasoning and intelligence to infer knowledge from a wide range of sources, such as oral and written narrations, reports, and traditions. Here we develop an extension of classical social network analysis approaches to incorporate the concept of meaning in each actor, as a mean to quantify and infer further knowledge from the original source of the network. This extension is based on a new affinity function, the semantic affinity, that establishes fuzzy-like relationships between the different actors in the network, using combinations of affinity functions. We also propose a new heuristic algorithm based on the shortest capacity problem to compute this affinity function. We use these concept of meaning and semantic affinity to analyze and compare the gods and heroes from three different classical mythologies: Greek, Celtic and Nordic. We study the relationships of each individual mythology and those of common structure that is formed when we fuse the three of them. We show a strong connection between the Celtic and Nordic gods and that Greeks put more emphasis on heroic characters rather than deities. Our approach provides a technique to highlight and quantify important relationships in the original domain of the network not deducible from its structural properties.