 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Not All Steps are Created Equal: Selective Diffusion Distillation for Image Manipulation
Jul 17, 2023

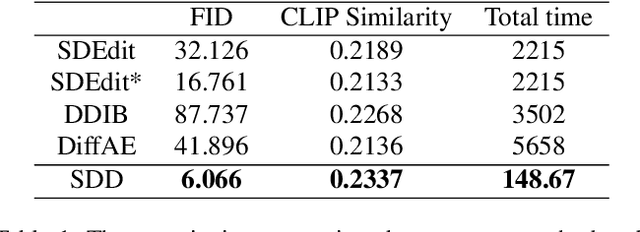

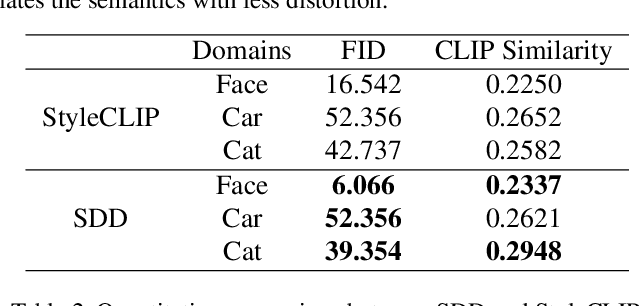
Conditional diffusion models have demonstrated impressive performance in image manipulation tasks. The general pipeline involves adding noise to the image and then denoising it. However, this method faces a trade-off problem: adding too much noise affects the fidelity of the image while adding too little affects its editability. This largely limits their practical applicability. In this paper, we propose a novel framework, Selective Diffusion Distillation (SDD), that ensures both the fidelity and editability of images. Instead of directly editing images with a diffusion model, we train a feedforward image manipulation network under the guidance of the diffusion model. Besides, we propose an effective indicator to select the semantic-related timestep to obtain the correct semantic guidance from the diffusion model. This approach successfully avoids the dilemma caused by the diffusion process. Our extensive experiments demonstrate the advantages of our framework. Code is released at https://github.com/AndysonYs/Selective-Diffusion-Distillation.
TSSAT: Two-Stage Statistics-Aware Transformation for Artistic Style Transfer
Sep 12, 2023
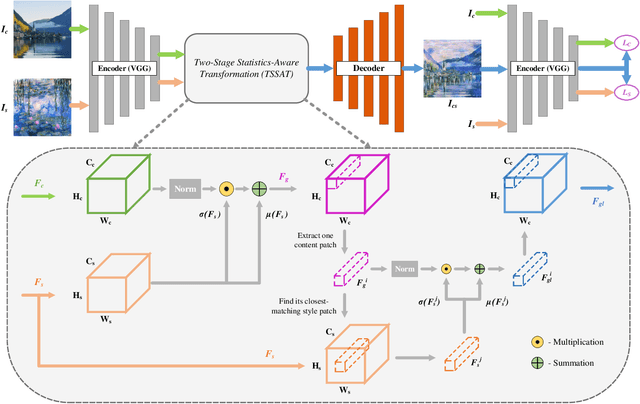
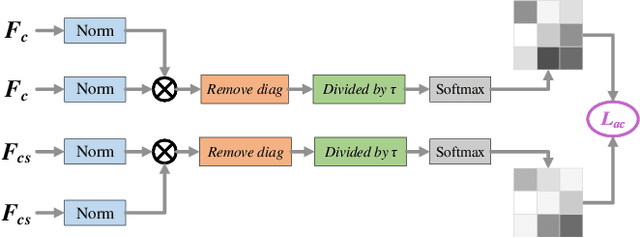

Artistic style transfer aims to create new artistic images by rendering a given photograph with the target artistic style. Existing methods learn styles simply based on global statistics or local patches, lacking careful consideration of the drawing process in practice. Consequently, the stylization results either fail to capture abundant and diversified local style patterns, or contain undesired semantic information of the style image and deviate from the global style distribution. To address this issue, we imitate the drawing process of humans and propose a Two-Stage Statistics-Aware Transformation (TSSAT) module, which first builds the global style foundation by aligning the global statistics of content and style features and then further enriches local style details by swapping the local statistics (instead of local features) in a patch-wise manner, significantly improving the stylization effects. Moreover, to further enhance both content and style representations, we introduce two novel losses: an attention-based content loss and a patch-based style loss, where the former enables better content preservation by enforcing the semantic relation in the content image to be retained during stylization, and the latter focuses on increasing the local style similarity between the style and stylized images. Extensive qualitative and quantitative experiments verify the effectiveness of our method.
Hyperbolic vs Euclidean Embeddings in Few-Shot Learning: Two Sides of the Same Coin
Sep 18, 2023Recent research in representation learning has shown that hierarchical data lends itself to low-dimensional and highly informative representations in hyperbolic space. However, even if hyperbolic embeddings have gathered attention in image recognition, their optimization is prone to numerical hurdles. Further, it remains unclear which applications stand to benefit the most from the implicit bias imposed by hyperbolicity, when compared to traditional Euclidean features. In this paper, we focus on prototypical hyperbolic neural networks. In particular, the tendency of hyperbolic embeddings to converge to the boundary of the Poincar\'e ball in high dimensions and the effect this has on few-shot classification. We show that the best few-shot results are attained for hyperbolic embeddings at a common hyperbolic radius. In contrast to prior benchmark results, we demonstrate that better performance can be achieved by a fixed-radius encoder equipped with the Euclidean metric, regardless of the embedding dimension.
Multi-log grasping using reinforcement learning and virtual visual servoing
Sep 06, 2023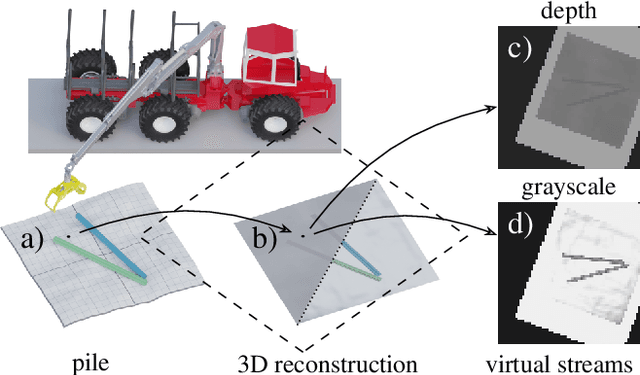
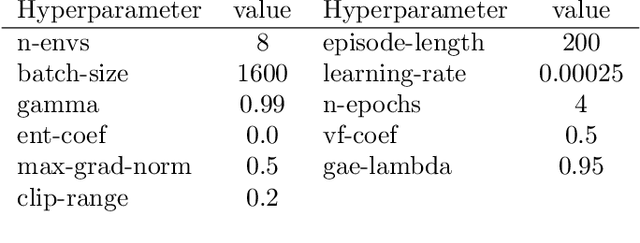


We explore multi-log grasping using reinforcement learning and virtual visual servoing for automated forwarding. Automation of forest processes is a major challenge, and many techniques regarding robot control pose different challenges due to the unstructured and harsh outdoor environment. Grasping multiple logs involves problems of dynamics and path planning, where the interaction between the grapple, logs, terrain, and obstacles requires visual information. To address these challenges, we separate image segmentation from crane control and utilize a virtual camera to provide an image stream from 3D reconstructed data. We use Cartesian control to simplify domain transfer. Since log piles are static, visual servoing using a 3D reconstruction of the pile and its surroundings is equivalent to using real camera data until the point of grasping. This relaxes the limit on computational resources and time for the challenge of image segmentation, and allows for collecting data in situations where the log piles are not occluded. The disadvantage is the lack of information during grasping. We demonstrate that this problem is manageable and present an agent that is 95% successful in picking one or several logs from challenging piles of 2--5 logs.
Visualizing Topological Importance: A Class-Driven Approach
Sep 22, 2023This paper presents the first approach to visualize the importance of topological features that define classes of data. Topological features, with their ability to abstract the fundamental structure of complex data, are an integral component of visualization and analysis pipelines. Although not all topological features present in data are of equal importance. To date, the default definition of feature importance is often assumed and fixed. This work shows how proven explainable deep learning approaches can be adapted for use in topological classification. In doing so, it provides the first technique that illuminates what topological structures are important in each dataset in regards to their class label. In particular, the approach uses a learned metric classifier with a density estimator of the points of a persistence diagram as input. This metric learns how to reweigh this density such that classification accuracy is high. By extracting this weight, an importance field on persistent point density can be created. This provides an intuitive representation of persistence point importance that can be used to drive new visualizations. This work provides two examples: Visualization on each diagram directly and, in the case of sublevel set filtrations on images, directly on the images themselves. This work highlights real-world examples of this approach visualizing the important topological features in graph, 3D shape, and medical image data.
Diff-Privacy: Diffusion-based Face Privacy Protection
Sep 11, 2023
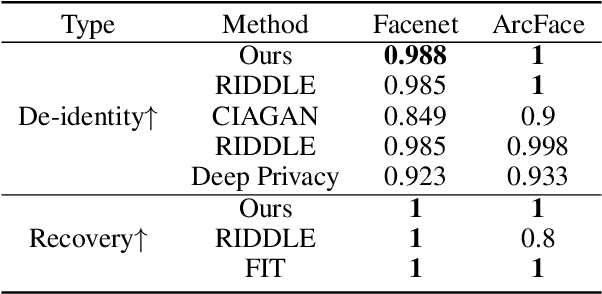
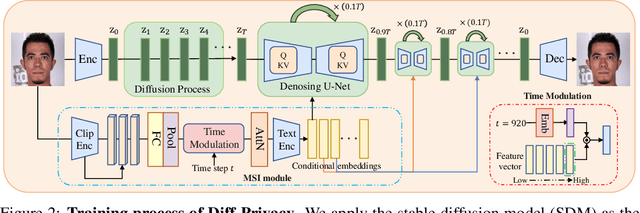
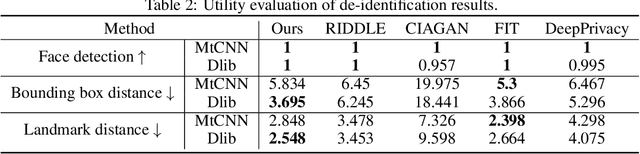
Privacy protection has become a top priority as the proliferation of AI techniques has led to widespread collection and misuse of personal data. Anonymization and visual identity information hiding are two important facial privacy protection tasks that aim to remove identification characteristics from facial images at the human perception level. However, they have a significant difference in that the former aims to prevent the machine from recognizing correctly, while the latter needs to ensure the accuracy of machine recognition. Therefore, it is difficult to train a model to complete these two tasks simultaneously. In this paper, we unify the task of anonymization and visual identity information hiding and propose a novel face privacy protection method based on diffusion models, dubbed Diff-Privacy. Specifically, we train our proposed multi-scale image inversion module (MSI) to obtain a set of SDM format conditional embeddings of the original image. Based on the conditional embeddings, we design corresponding embedding scheduling strategies and construct different energy functions during the denoising process to achieve anonymization and visual identity information hiding. Extensive experiments have been conducted to validate the effectiveness of our proposed framework in protecting facial privacy.
DiffuseGAE: Controllable and High-fidelity Image Manipulation from Disentangled Representation
Jul 12, 2023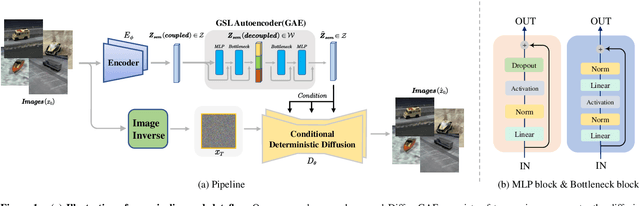
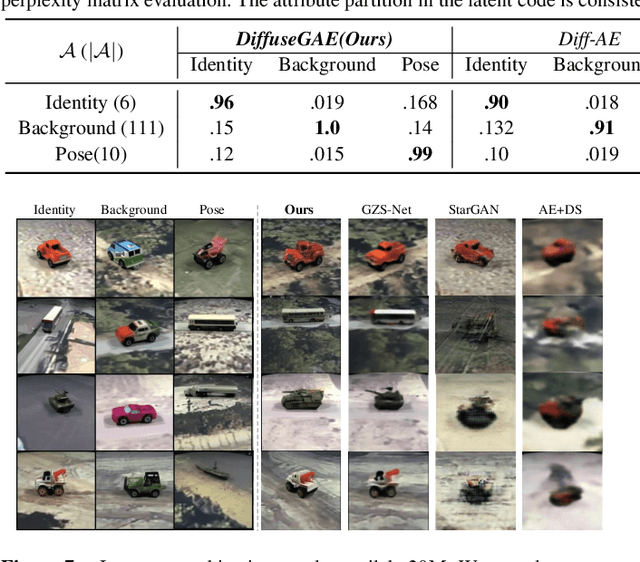
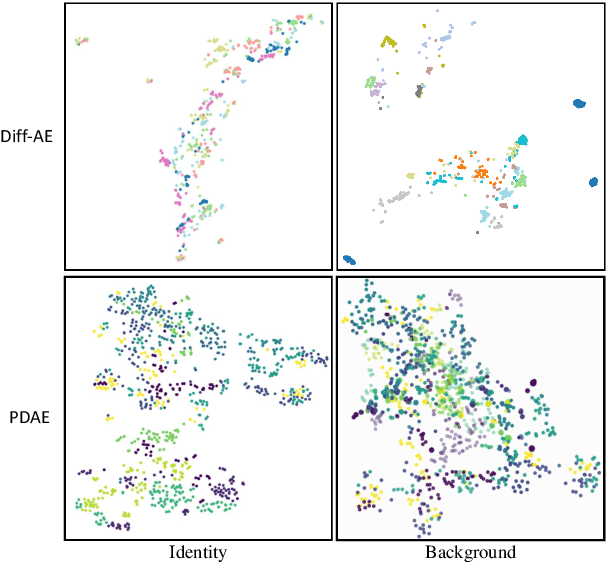
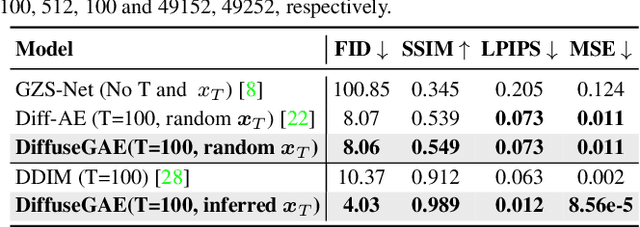
Diffusion probabilistic models (DPMs) have shown remarkable results on various image synthesis tasks such as text-to-image generation and image inpainting. However, compared to other generative methods like VAEs and GANs, DPMs lack a low-dimensional, interpretable, and well-decoupled latent code. Recently, diffusion autoencoders (Diff-AE) were proposed to explore the potential of DPMs for representation learning via autoencoding. Diff-AE provides an accessible latent space that exhibits remarkable interpretability, allowing us to manipulate image attributes based on latent codes from the space. However, previous works are not generic as they only operated on a few limited attributes. To further explore the latent space of Diff-AE and achieve a generic editing pipeline, we proposed a module called Group-supervised AutoEncoder(dubbed GAE) for Diff-AE to achieve better disentanglement on the latent code. Our proposed GAE has trained via an attribute-swap strategy to acquire the latent codes for multi-attribute image manipulation based on examples. We empirically demonstrate that our method enables multiple-attributes manipulation and achieves convincing sample quality and attribute alignments, while significantly reducing computational requirements compared to pixel-based approaches for representational decoupling. Code will be released soon.
RobustCLEVR: A Benchmark and Framework for Evaluating Robustness in Object-centric Learning
Aug 28, 2023Object-centric representation learning offers the potential to overcome limitations of image-level representations by explicitly parsing image scenes into their constituent components. While image-level representations typically lack robustness to natural image corruptions, the robustness of object-centric methods remains largely untested. To address this gap, we present the RobustCLEVR benchmark dataset and evaluation framework. Our framework takes a novel approach to evaluating robustness by enabling the specification of causal dependencies in the image generation process grounded in expert knowledge and capable of producing a wide range of image corruptions unattainable in existing robustness evaluations. Using our framework, we define several causal models of the image corruption process which explicitly encode assumptions about the causal relationships and distributions of each corruption type. We generate dataset variants for each causal model on which we evaluate state-of-the-art object-centric methods. Overall, we find that object-centric methods are not inherently robust to image corruptions. Our causal evaluation approach exposes model sensitivities not observed using conventional evaluation processes, yielding greater insight into robustness differences across algorithms. Lastly, while conventional robustness evaluations view corruptions as out-of-distribution, we use our causal framework to show that even training on in-distribution image corruptions does not guarantee increased model robustness. This work provides a step towards more concrete and substantiated understanding of model performance and deterioration under complex corruption processes of the real-world.
Doppelgangers: Learning to Disambiguate Images of Similar Structures
Sep 05, 2023
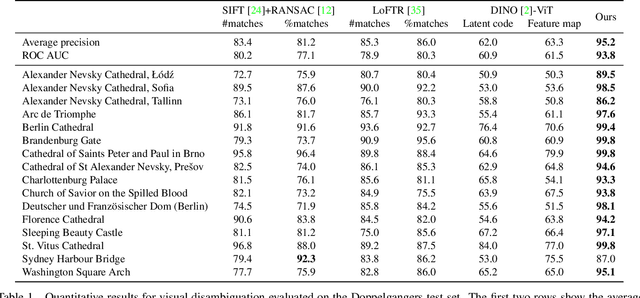
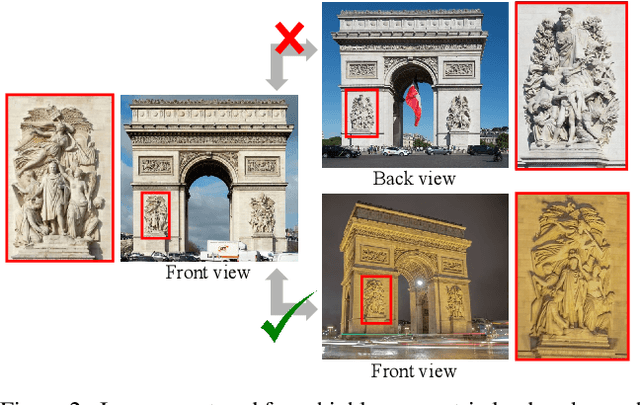
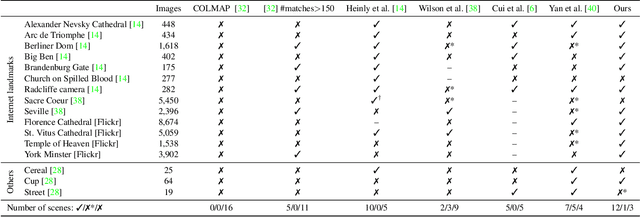
We consider the visual disambiguation task of determining whether a pair of visually similar images depict the same or distinct 3D surfaces (e.g., the same or opposite sides of a symmetric building). Illusory image matches, where two images observe distinct but visually similar 3D surfaces, can be challenging for humans to differentiate, and can also lead 3D reconstruction algorithms to produce erroneous results. We propose a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. To that end, we introduce a new dataset for this problem, Doppelgangers, which includes image pairs of similar structures with ground truth labels. We also design a network architecture that takes the spatial distribution of local keypoints and matches as input, allowing for better reasoning about both local and global cues. Our evaluation shows that our method can distinguish illusory matches in difficult cases, and can be integrated into SfM pipelines to produce correct, disambiguated 3D reconstructions. See our project page for our code, datasets, and more results: http://doppelgangers-3d.github.io/.
Quasi-Monte Carlo for 3D Sliced Wasserstein
Sep 21, 2023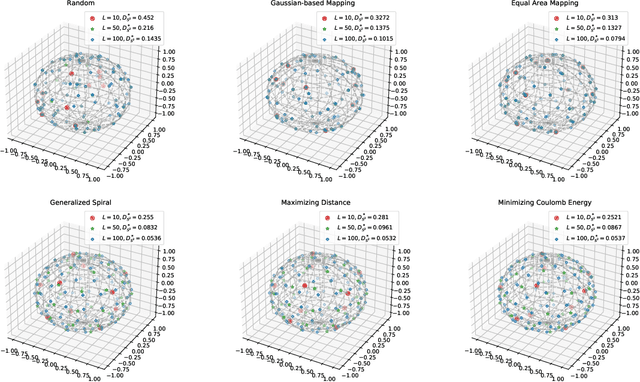
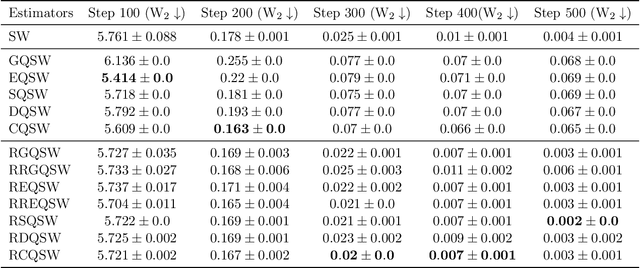
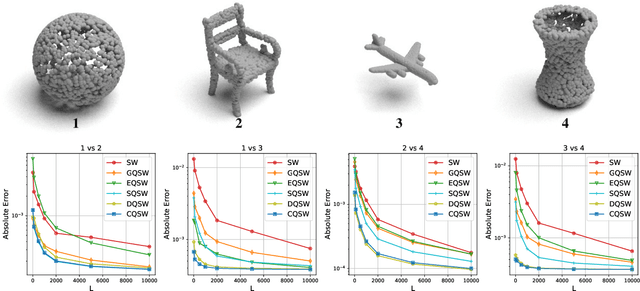
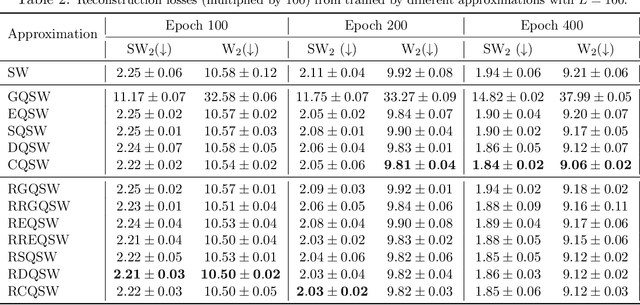
Monte Carlo (MC) approximation has been used as the standard computation approach for the Sliced Wasserstein (SW) distance, which has an intractable expectation in its analytical form. However, the MC method is not optimal in terms of minimizing the absolute approximation error. To provide a better class of empirical SW, we propose quasi-sliced Wasserstein (QSW) approximations that rely on Quasi-Monte Carlo (QMC) methods. For a comprehensive investigation of QMC for SW, we focus on the 3D setting, specifically computing the SW between probability measures in three dimensions. In greater detail, we empirically verify various ways of constructing QMC points sets on the 3D unit-hypersphere, including Gaussian-based mapping, equal area mapping, generalized spiral points, and optimizing discrepancy energies. Furthermore, to obtain an unbiased estimation for stochastic optimization, we extend QSW into Randomized Quasi-Sliced Wasserstein (RQSW) by introducing randomness to the discussed low-discrepancy sequences. For theoretical properties, we prove the asymptotic convergence of QSW and the unbiasedness of RQSW. Finally, we conduct experiments on various 3D tasks, such as point-cloud comparison, point-cloud interpolation, image style transfer, and training deep point-cloud autoencoders, to demonstrate the favorable performance of the proposed QSW and RQSW variants.