 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliced-Regularized Optimal Transport
Apr 27, 2026We propose a new regularized optimal transport (OT) formulation, termed sliced-regularized optimal transport (SROT). Unlike entropic OT (EOT), which regularizes the transport plan toward an independent coupling, SROT regularizes it toward a smoothened sliced OT (SOT) plan. To the best of our knowledge, SROT is the first approach to leverage a version of SOT plan as a reference to improve classical OT. We provide a formal definition of SROT, derive its dual formulation, and provide a post-Bayesian interpretation of SROT. We then develop a Sinkhorn-style algorithm for efficient computation, retaining the same scalability advantages as EOT. By incorporating a scalable SOT plan as a prior, SROT yields more accurate approximations of the exact OT plan than EOT under the same level of regularization. Moreover, the resulting transport plan improves upon the reference SOT plan itself. We further introduce the corresponding OT divergence induced by SROT, named SROT divergence, and analyze its topological and computational properties. Finally, we validate our approach through experiments on synthetic datasets and color transfer tasks, demonstrating that SROT is better than both EOT and SOT in approximating exact OT. Additional experiments on gradient flows further highlight the advantages of SROT divergence.
Amortized Optimal Transport from Sliced Potentials
Apr 16, 2026We propose a novel amortized optimization method for predicting optimal transport (OT) plans across multiple pairs of measures by leveraging Kantorovich potentials derived from sliced OT. We introduce two amortization strategies: regression-based amortization (RA-OT) and objective-based amortization (OA-OT). In RA-OT, we formulate a functional regression model that treats Kantorovich potentials from the original OT problem as responses and those obtained from sliced OT as predictors, and estimate these models via least-squares methods. In OA-OT, we estimate the parameters of the functional model by optimizing the Kantorovich dual objective. In both approaches, the predicted OT plan is subsequently recovered from the estimated potentials. As amortized OT methods, both RA-OT and OA-OT enable efficient solutions to repeated OT problems across different measure pairs by reusing information learned from prior instances to rapidly approximate new solutions. Moreover, by exploiting the structure provided by sliced OT, the proposed models are more parsimonious, independent of specific structures of the measures, such as the number of atoms in the discrete case, while achieving high accuracy. We demonstrate the effectiveness of our approaches on tasks including MNIST digit transport, color transfer, supply-demand transportation on spherical data, and mini-batch OT conditional flow matching.
Vertical Consensus Inference for High-Dimensional Random Partition
Mar 29, 2026We review recently proposed Bayesian approaches for clustering high-dimensional data. After identifying the main limitations of available approaches, we introduce an alternative framework based on vertical consensus inference (VCI) to mitigate the curse of dimensionality in high-dimensional Bayesian clustering. VCI builds on the idea of consensus Monte Carlo by dividing the data into multiple shards (smaller subsets of variables), performing posterior inference on each shard, and then combining the shard-level posteriors to obtain a consensus posterior. The key distinction is that VCI splits the data vertically, producing vertical shards that retain the same number of observations but have lower dimensionality. We use an entropic regularized Wasserstein barycenter to define a consensus posterior. The shard-specific barycenter weights are constructed to favor shards that provide meaningful partitions, distinct from a trivial single cluster or all singleton clusters, favoring balanced cluster sizes and precise shard-specific posterior random partitions. We show that VCI can be interpreted as a variational approximation to the posterior under a hierarchical model with a generalized Bayes prior. For relatively low-dimensional problems, experiments suggest that VCI closely approximates inference based on clustering the entire multivariate data. For high-dimensional data and in the presence of many noninformative dimensions, VCI introduces a new framework for model-based and principled inference on random partitions. Although our focus here is on random partitions, VCI can be applied to any dimension-independent parameters and serves as a bridge to emerging areas in statistics such as consensus Monte Carlo, optimal transport, variational inference, and generalized Bayes.
Cheap Thrills: Effective Amortized Optimization Using Inexpensive Labels
Mar 05, 2026To scale the solution of optimization and simulation problems, prior work has explored machine-learning surrogates that inexpensively map problem parameters to corresponding solutions. Commonly used approaches, including supervised and self-supervised learning with either soft or hard feasibility enforcement, face inherent challenges such as reliance on expensive, high-quality labels or difficult optimization landscapes. To address their trade-offs, we propose a novel framework that first collects "cheap" imperfect labels, then performs supervised pretraining, and finally refines the model through self-supervised learning to improve overall performance. Our theoretical analysis and merit-based criterion show that labeled data need only place the model within a basin of attraction, confirming that only modest numbers of inexact labels and training epochs are required. We empirically validate our simple three-stage strategy across challenging domains, including nonconvex constrained optimization, power-grid operation, and stiff dynamical systems, and show that it yields faster convergence; improved accuracy, feasibility, and optimality; and up to 59x reductions in total offline cost.
Bayesian Multiple Multivariate Density-Density Regression
Jan 06, 2026We propose the first approach for multiple multivariate density-density regression (MDDR), making it possible to consider the regression of a multivariate density-valued response on multiple multivariate density-valued predictors. The core idea is to define a fitted distribution using a sliced Wasserstein barycenter (SWB) of push-forwards of the predictors and to quantify deviations from the observed response using the sliced Wasserstein (SW) distance. Regression functions, which map predictors' supports to the response support, and barycenter weights are inferred within a generalized Bayes framework, enabling principled uncertainty quantification without requiring a fully specified likelihood. The inference process can be seen as an instance of an inverse SWB problem. We establish theoretical guarantees, including the stability of the SWB under perturbations of marginals and barycenter weights, sample complexity of the generalized likelihood, and posterior consistency. For practical inference, we introduce a differentiable approximation of the SWB and a smooth reparameterization to handle the simplex constraint on barycenter weights, allowing efficient gradient-based MCMC sampling. We demonstrate MDDR in an application to inference for population-scale single-cell data. Posterior analysis under the MDDR model in this example includes inference on communication between multiple source/sender cell types and a target/receiver cell type. The proposed approach provides accurate fits, reliable predictions, and interpretable posterior estimates of barycenter weights, which can be used to construct sparse cell-cell communication networks.
An Introduction to Sliced Optimal Transport
Aug 17, 2025Sliced Optimal Transport (SOT) is a rapidly developing branch of optimal transport (OT) that exploits the tractability of one-dimensional OT problems. By combining tools from OT, integral geometry, and computational statistics, SOT enables fast and scalable computation of distances, barycenters, and kernels for probability measures, while retaining rich geometric structure. This paper provides a comprehensive review of SOT, covering its mathematical foundations, methodological advances, computational methods, and applications. We discuss key concepts of OT and one-dimensional OT, the role of tools from integral geometry such as Radon transform in projecting measures, and statistical techniques for estimating sliced distances. The paper further explores recent methodological advances, including non-linear projections, improved Monte Carlo approximations, statistical estimation techniques for one-dimensional optimal transport, weighted slicing techniques, and transportation plan estimation methods. Variational problems, such as minimum sliced Wasserstein estimation, barycenters, gradient flows, kernel constructions, and embeddings are examined alongside extensions to unbalanced, partial, multi-marginal, and Gromov-Wasserstein settings. Applications span machine learning, statistics, computer graphics and computer visions, highlighting SOT's versatility as a practical computational tool. This work will be of interest to researchers and practitioners in machine learning, data sciences, and computational disciplines seeking efficient alternatives to classical OT.
Streaming Sliced Optimal Transport
May 11, 2025Sliced optimal transport (SOT) or sliced Wasserstein (SW) distance is widely recognized for its statistical and computational scalability. In this work, we further enhance the computational scalability by proposing the first method for computing SW from sample streams, called \emph{streaming sliced Wasserstein} (Stream-SW). To define Stream-SW, we first introduce the streaming computation of the one-dimensional Wasserstein distance. Since the one-dimensional Wasserstein (1DW) distance has a closed-form expression, given by the absolute difference between the quantile functions of the compared distributions, we leverage quantile approximation techniques for sample streams to define the streaming 1DW distance. By applying streaming 1DW to all projections, we obtain Stream-SW. The key advantage of Stream-SW is its low memory complexity while providing theoretical guarantees on the approximation error. We demonstrate that Stream-SW achieves a more accurate approximation of SW than random subsampling, with lower memory consumption, in comparing Gaussian distributions and mixtures of Gaussians from streaming samples. Additionally, we conduct experiments on point cloud classification, point cloud gradient flows, and streaming change point detection to further highlight the favorable performance of Stream-SW.
Model Tensor Planning
May 02, 2025



Sampling-based model predictive control (MPC) offers strong performance in nonlinear and contact-rich robotic tasks, yet often suffers from poor exploration due to locally greedy sampling schemes. We propose \emph{Model Tensor Planning} (MTP), a novel sampling-based MPC framework that introduces high-entropy control trajectory generation through structured tensor sampling. By sampling over randomized multipartite graphs and interpolating control trajectories with B-splines and Akima splines, MTP ensures smooth and globally diverse control candidates. We further propose a simple $\beta$-mixing strategy that blends local exploitative and global exploratory samples within the modified Cross-Entropy Method (CEM) update, balancing control refinement and exploration. Theoretically, we show that MTP achieves asymptotic path coverage and maximum entropy in the control trajectory space in the limit of infinite tensor depth and width. Our implementation is fully vectorized using JAX and compatible with MuJoCo XLA, supporting \emph{Just-in-time} (JIT) compilation and batched rollouts for real-time control with online domain randomization. Through experiments on various challenging robotic tasks, ranging from dexterous in-hand manipulation to humanoid locomotion, we demonstrate that MTP outperforms standard MPC and evolutionary strategy baselines in task success and control robustness. Design and sensitivity ablations confirm the effectiveness of MTP tensor sampling structure, spline interpolation choices, and mixing strategy. Altogether, MTP offers a scalable framework for robust exploration in model-based planning and control.
Improving Routing in Sparse Mixture of Experts with Graph of Tokens
May 01, 2025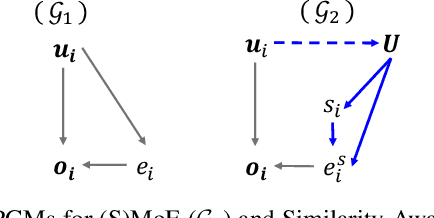
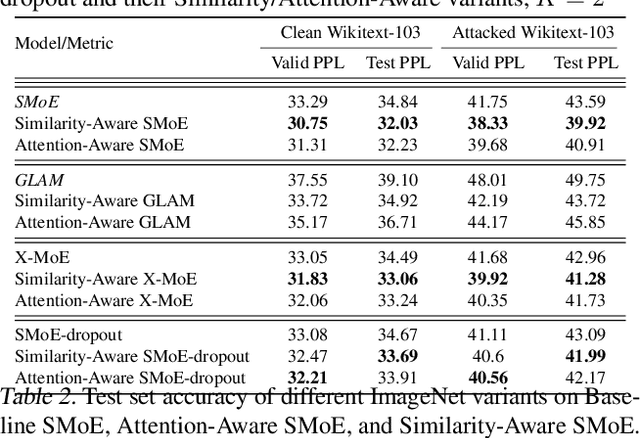
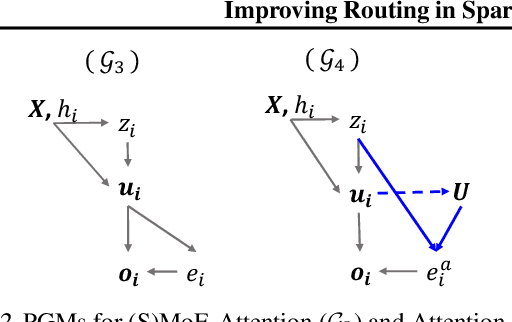
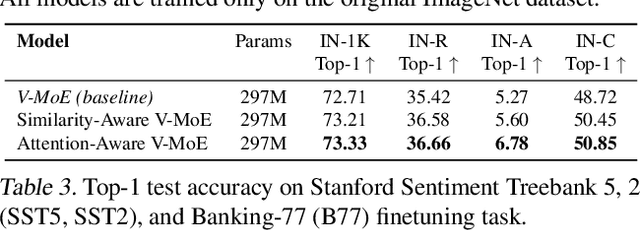
Sparse Mixture of Experts (SMoE) has emerged as a key to achieving unprecedented scalability in deep learning. By activating only a small subset of parameters per sample, SMoE achieves an exponential increase in parameter counts while maintaining a constant computational overhead. However, SMoE models are susceptible to routing fluctuations--changes in the routing of a given input to its target expert--at the late stage of model training, leading to model non-robustness. In this work, we unveil the limitation of SMoE through the perspective of the probabilistic graphical model (PGM). Through this PGM framework, we highlight the independence in the expert-selection of tokens, which exposes the model to routing fluctuation and non-robustness. Alleviating this independence, we propose the novel Similarity-Aware (S)MoE, which considers interactions between tokens during expert selection. We then derive a new PGM underlying an (S)MoE-Attention block, going beyond just a single (S)MoE layer. Leveraging the token similarities captured by the attention matrix, we propose the innovative Attention-Aware (S)MoE, which employs the attention matrix to guide the routing of tokens to appropriate experts in (S)MoE. We theoretically prove that Similarity/Attention-Aware routing help reduce the entropy of expert selection, resulting in more stable token routing mechanisms. We empirically validate our models on various tasks and domains, showing significant improvements in reducing routing fluctuations, enhancing accuracy, and increasing model robustness over the baseline MoE-Transformer with token routing via softmax gating.
Bayesian Density-Density Regression with Application to Cell-Cell Communications
Apr 17, 2025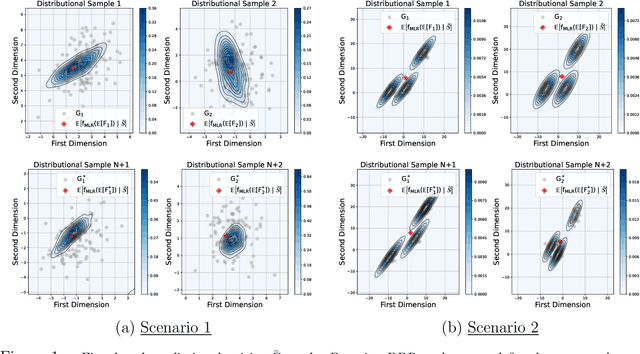
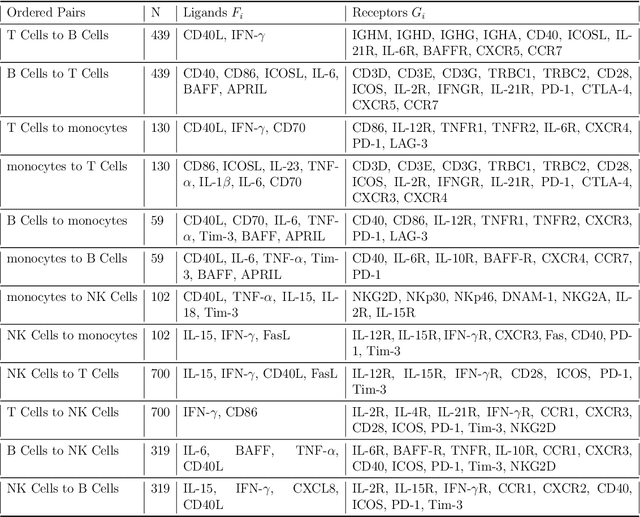
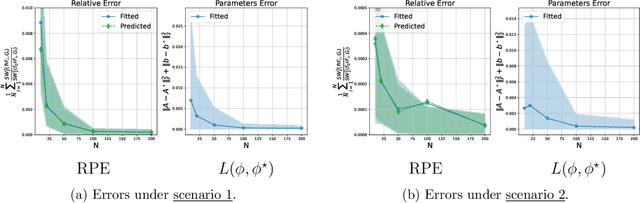
We introduce a scalable framework for regressing multivariate distributions onto multivariate distributions, motivated by the application of inferring cell-cell communication from population-scale single-cell data. The observed data consist of pairs of multivariate distributions for ligands from one cell type and corresponding receptors from another. For each ordered pair $e=(l,r)$ of cell types $(l \neq r)$ and each sample $i = 1, \ldots, n$, we observe a pair of distributions $(F_{ei}, G_{ei})$ of gene expressions for ligands and receptors of cell types $l$ and $r$, respectively. The aim is to set up a regression of receptor distributions $G_{ei}$ given ligand distributions $F_{ei}$. A key challenge is that these distributions reside in distinct spaces of differing dimensions. We formulate the regression of multivariate densities on multivariate densities using a generalized Bayes framework with the sliced Wasserstein distance between fitted and observed distributions. Finally, we use inference under such regressions to define a directed graph for cell-cell communications.