 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Elucidating the solution space of extended reverse-time SDE for diffusion models
Sep 26, 2023




Diffusion models (DMs) demonstrate potent image generation capabilities in various generative modeling tasks. Nevertheless, their primary limitation lies in slow sampling speed, requiring hundreds or thousands of sequential function evaluations through large neural networks to generate high-quality images. Sampling from DMs can be seen alternatively as solving corresponding stochastic differential equations (SDEs) or ordinary differential equations (ODEs). In this work, we formulate the sampling process as an extended reverse-time SDE (ER SDE), unifying prior explorations into ODEs and SDEs. Leveraging the semi-linear structure of ER SDE solutions, we offer exact solutions and arbitrarily high-order approximate solutions for VP SDE and VE SDE, respectively. Based on the solution space of the ER SDE, we yield mathematical insights elucidating the superior performance of ODE solvers over SDE solvers in terms of fast sampling. Additionally, we unveil that VP SDE solvers stand on par with their VE SDE counterparts. Finally, we devise fast and training-free samplers, ER-SDE-Solvers, achieving state-of-the-art performance across all stochastic samplers. Experimental results demonstrate achieving 3.45 FID in 20 function evaluations and 2.24 FID in 50 function evaluations on the ImageNet $64\times64$ dataset.
Stream-based Active Learning by Exploiting Temporal Properties in Perception with Temporal Predicted Loss
Sep 26, 2023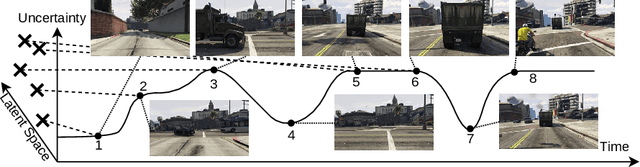
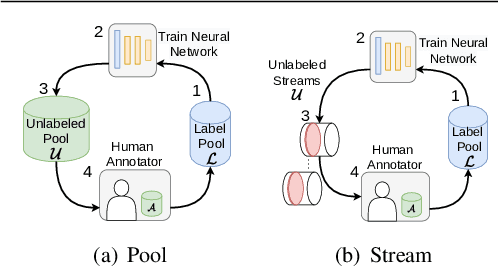
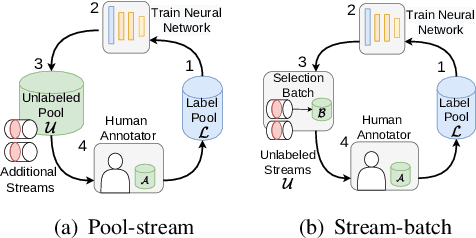

Active learning (AL) reduces the amount of labeled data needed to train a machine learning model by intelligently choosing which instances to label. Classic pool-based AL requires all data to be present in a datacenter, which can be challenging with the increasing amounts of data needed in deep learning. However, AL on mobile devices and robots, like autonomous cars, can filter the data from perception sensor streams before reaching the datacenter. We exploited the temporal properties for such image streams in our work and proposed the novel temporal predicted loss (TPL) method. To evaluate the stream-based setting properly, we introduced the GTA V streets and the A2D2 streets dataset and made both publicly available. Our experiments showed that our approach significantly improves the diversity of the selection while being an uncertainty-based method. As pool-based approaches are more common in perception applications, we derived a concept for comparing pool-based and stream-based AL, where TPL out-performed state-of-the-art pool- or stream-based approaches for different models. TPL demonstrated a gain of 2.5 precept points (pp) less required data while being significantly faster than pool-based methods.
Learning Spiking Neural Network from Easy to Hard task
Sep 26, 2023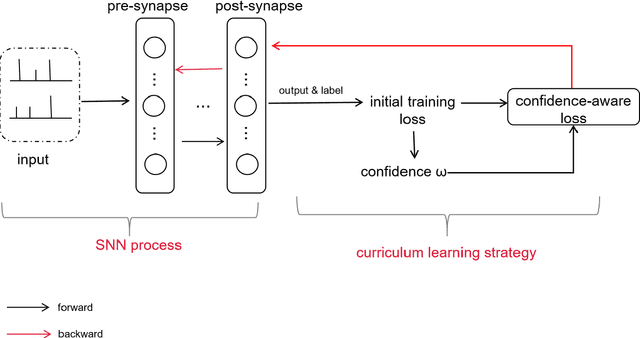
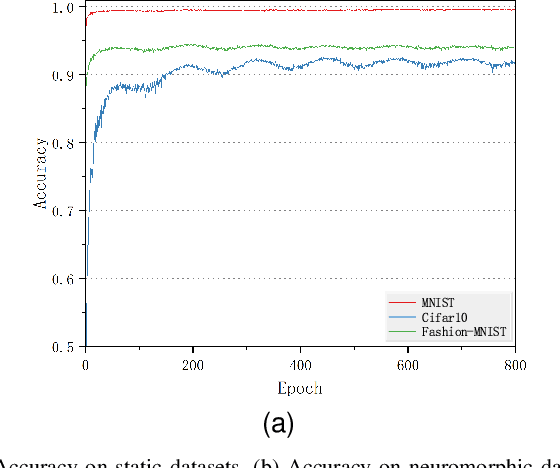
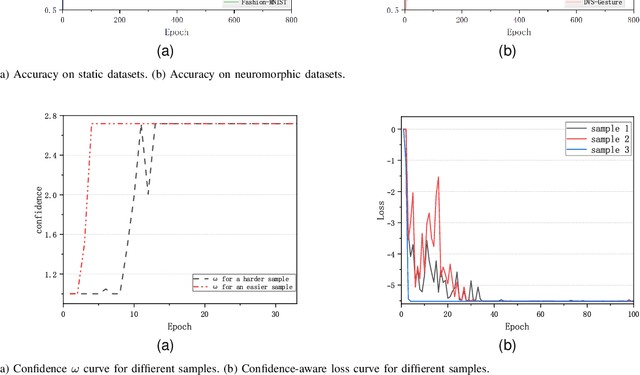
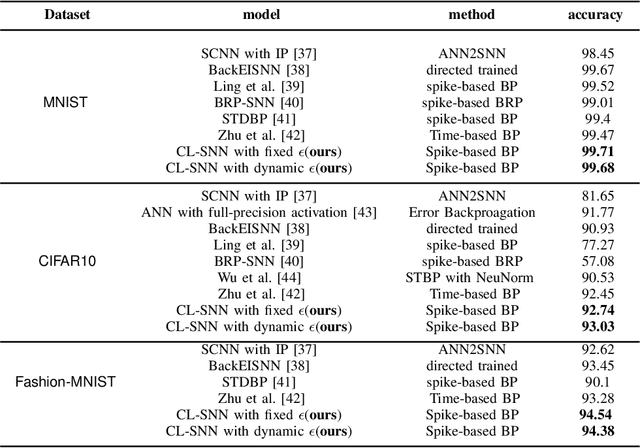
Starting with small and simple concepts, and gradually introducing complex and difficult concepts is the natural process of human learning. Spiking Neural Networks (SNNs) aim to mimic the way humans process information, but current SNNs models treat all samples equally, which does not align with the principles of human learning and overlooks the biological plausibility of SNNs. To address this, we propose a CL-SNN model that introduces Curriculum Learning(CL) into SNNs, making SNNs learn more like humans and providing higher biological interpretability. CL is a training strategy that advocates presenting easier data to models before gradually introducing more challenging data, mimicking the human learning process. We use a confidence-aware loss to measure and process the samples with different difficulty levels. By learning the confidence of different samples, the model reduces the contribution of difficult samples to parameter optimization automatically. We conducted experiments on static image datasets MNIST, Fashion-MNIST, CIFAR10, and neuromorphic datasets N-MNIST, CIFAR10-DVS, DVS-Gesture. The results are promising. To our best knowledge, this is the first proposal to enhance the biologically plausibility of SNNs by introducing CL.
Computer Vision Pipeline for Automated Antarctic Krill Analysis
Sep 12, 2023British Antarctic Survey (BAS) researchers launch annual expeditions to the Antarctic in order to estimate Antarctic Krill biomass and assess the change from previous years. These comparisons provide insight into the effects of the current environment on this key component of the marine food chain. In this work we have developed tools for automating the data collection and analysis process, using web-based image annotation tools and deep learning image classification and regression models. We achieve highly accurate krill instance segmentation results with an average 77.28% AP score, as well as separate maturity stage and length estimation of krill specimens with 62.99% accuracy and a 1.96 mm length error respectively.
An Improved Encoder-Decoder Framework for Food Energy Estimation
Sep 04, 2023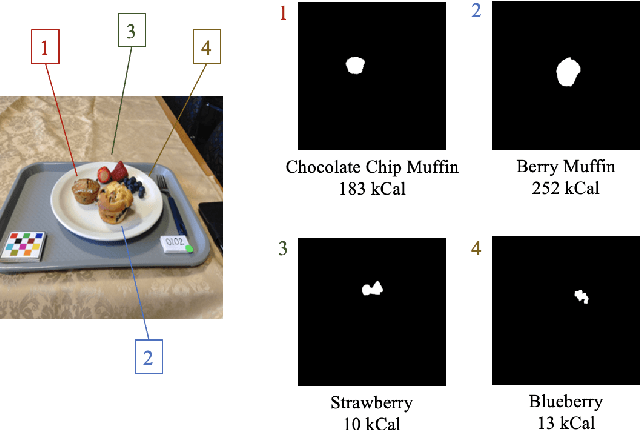

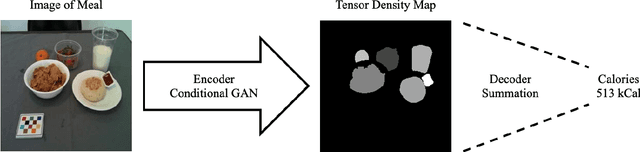

Dietary assessment is essential to maintaining a healthy lifestyle. Automatic image-based dietary assessment is a growing field of research due to the increasing prevalence of image capturing devices (e.g. mobile phones). In this work, we estimate food energy from a single monocular image, a difficult task due to the limited hard-to-extract amount of energy information present in an image. To do so, we employ an improved encoder-decoder framework for energy estimation; the encoder transforms the image into a representation embedded with food energy information in an easier-to-extract format, which the decoder then extracts the energy information from. To implement our method, we compile a high-quality food image dataset verified by registered dietitians containing eating scene images, food-item segmentation masks, and ground truth calorie values. Our method improves upon previous caloric estimation methods by over 10\% and 30 kCal in terms of MAPE and MAE respectively.
Unsupervised Decomposition Networks for Bias Field Correction in MR Image
Jul 30, 2023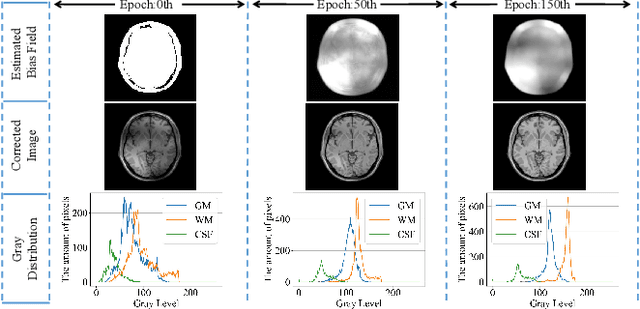
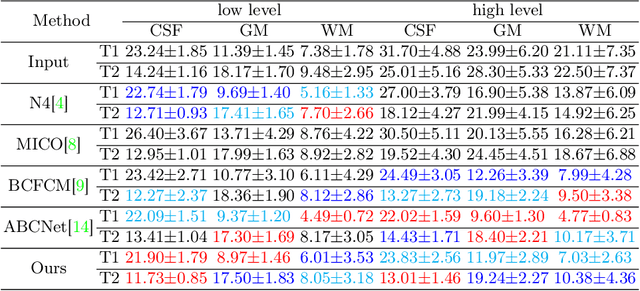
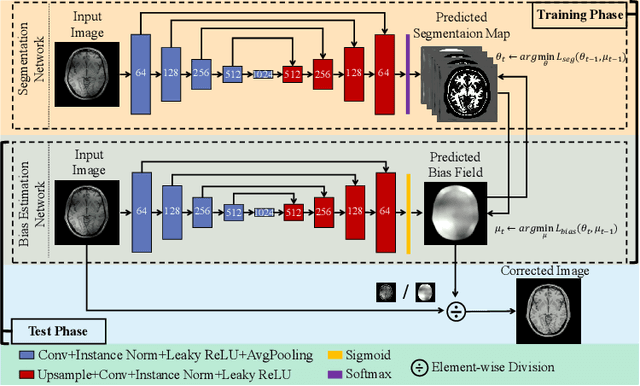
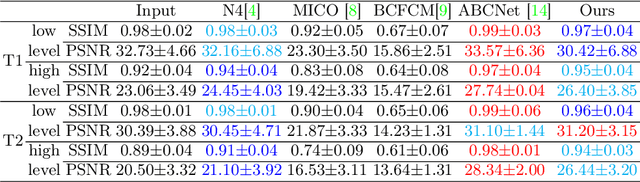
Bias field, which is caused by imperfect MR devices or imaged objects, introduces intensity inhomogeneity into MR images and degrades the performance of MR image analysis methods. Many retrospective algorithms were developed to facilitate the bias correction, to which the deep learning-based methods outperformed. However, in the training phase, the supervised deep learning-based methods heavily rely on the synthesized bias field. As the formation of the bias field is extremely complex, it is difficult to mimic the true physical property of MR images by synthesized data. While bias field correction and image segmentation are strongly related, the segmentation map is precisely obtained by decoupling the bias field from the original MR image, and the bias value is indicated by the segmentation map in reverse. Thus, we proposed novel unsupervised decomposition networks that are trained only with biased data to obtain the bias-free MR images. Networks are made up of: a segmentation part to predict the probability of every pixel belonging to each class, and an estimation part to calculate the bias field, which are optimized alternately. Furthermore, loss functions based on the combination of fuzzy clustering and the multiplicative bias field are also devised. The proposed loss functions introduce the smoothness of bias field and construct the soft relationships among different classes under intra-consistency constraints. Extensive experiments demonstrate that the proposed method can accurately estimate bias fields and produce better bias correction results. The code is available on the link: https://github.com/LeongDong/Bias-Decomposition-Networks.
ExBluRF: Efficient Radiance Fields for Extreme Motion Blurred Images
Sep 16, 2023

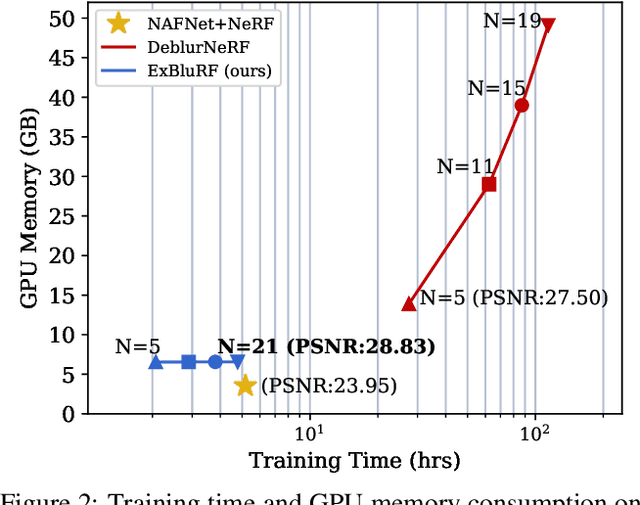
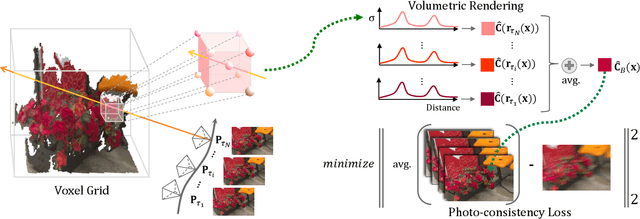
We present ExBluRF, a novel view synthesis method for extreme motion blurred images based on efficient radiance fields optimization. Our approach consists of two main components: 6-DOF camera trajectory-based motion blur formulation and voxel-based radiance fields. From extremely blurred images, we optimize the sharp radiance fields by jointly estimating the camera trajectories that generate the blurry images. In training, multiple rays along the camera trajectory are accumulated to reconstruct single blurry color, which is equivalent to the physical motion blur operation. We minimize the photo-consistency loss on blurred image space and obtain the sharp radiance fields with camera trajectories that explain the blur of all images. The joint optimization on the blurred image space demands painfully increasing computation and resources proportional to the blur size. Our method solves this problem by replacing the MLP-based framework to low-dimensional 6-DOF camera poses and voxel-based radiance fields. Compared with the existing works, our approach restores much sharper 3D scenes from challenging motion blurred views with the order of 10 times less training time and GPU memory consumption.
Order-preserving Consistency Regularization for Domain Adaptation and Generalization
Sep 23, 2023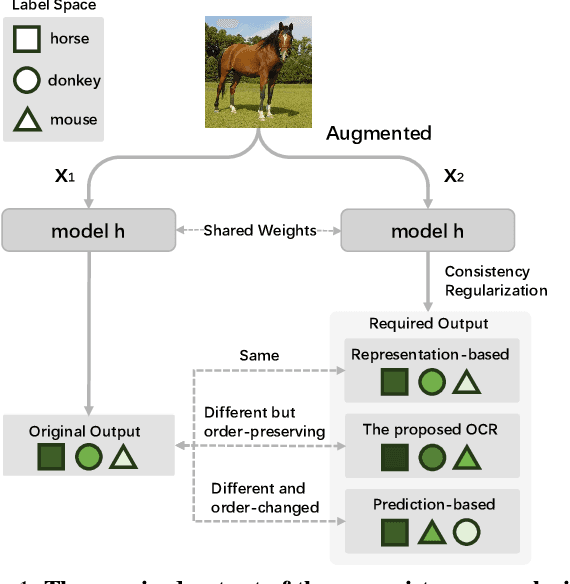

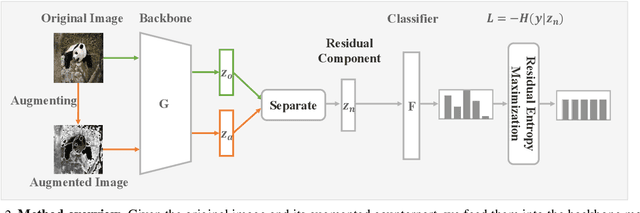
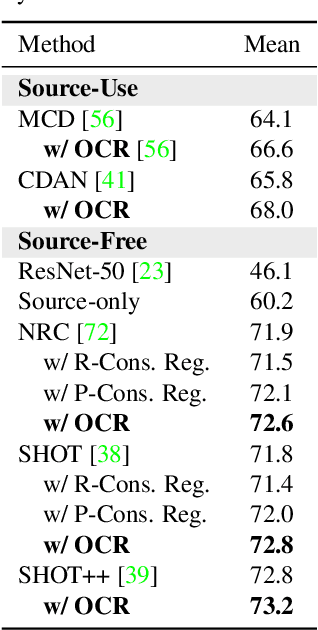
Deep learning models fail on cross-domain challenges if the model is oversensitive to domain-specific attributes, e.g., lightning, background, camera angle, etc. To alleviate this problem, data augmentation coupled with consistency regularization are commonly adopted to make the model less sensitive to domain-specific attributes. Consistency regularization enforces the model to output the same representation or prediction for two views of one image. These constraints, however, are either too strict or not order-preserving for the classification probabilities. In this work, we propose the Order-preserving Consistency Regularization (OCR) for cross-domain tasks. The order-preserving property for the prediction makes the model robust to task-irrelevant transformations. As a result, the model becomes less sensitive to the domain-specific attributes. The comprehensive experiments show that our method achieves clear advantages on five different cross-domain tasks.
PNN: From proximal algorithms to robust unfolded image denoising networks and Plug-and-Play methods
Aug 06, 2023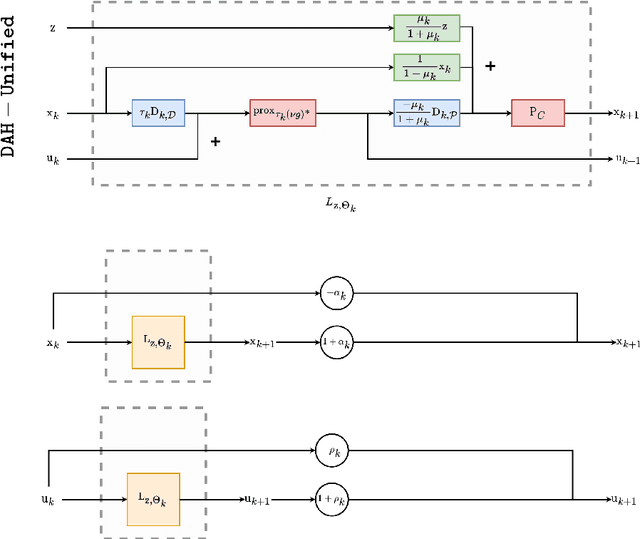

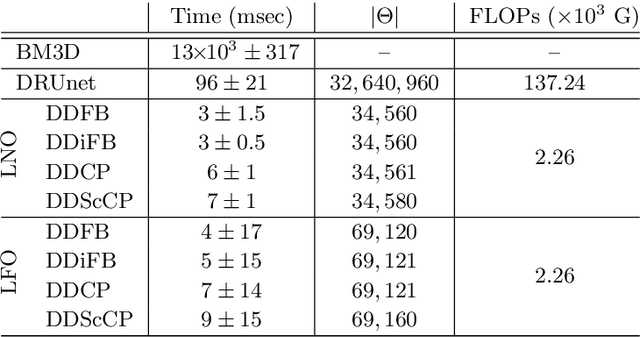
A common approach to solve inverse imaging problems relies on finding a maximum a posteriori (MAP) estimate of the original unknown image, by solving a minimization problem. In thiscontext, iterative proximal algorithms are widely used, enabling to handle non-smooth functions and linear operators. Recently, these algorithms have been paired with deep learning strategies, to further improve the estimate quality. In particular, proximal neural networks (PNNs) have been introduced, obtained by unrolling a proximal algorithm as for finding a MAP estimate, but over a fixed number of iterations, with learned linear operators and parameters. As PNNs are based on optimization theory, they are very flexible, and can be adapted to any image restoration task, as soon as a proximal algorithm can solve it. They further have much lighter architectures than traditional networks. In this article we propose a unified framework to build PNNs for the Gaussian denoising task, based on both the dual-FB and the primal-dual Chambolle-Pock algorithms. We further show that accelerated inertial versions of these algorithms enable skip connections in the associated NN layers. We propose different learning strategies for our PNN framework, and investigate their robustness (Lipschitz property) and denoising efficiency. Finally, we assess the robustness of our PNNs when plugged in a forward-backward algorithm for an image deblurring problem.
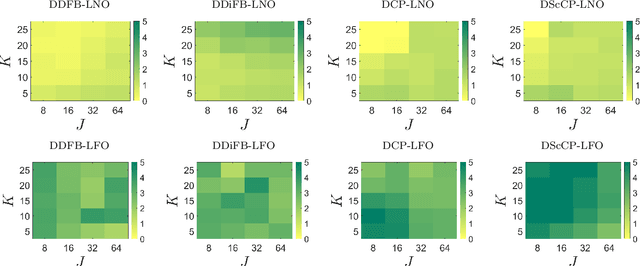
MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation
Sep 24, 2023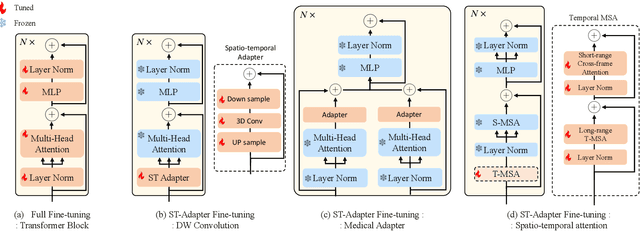
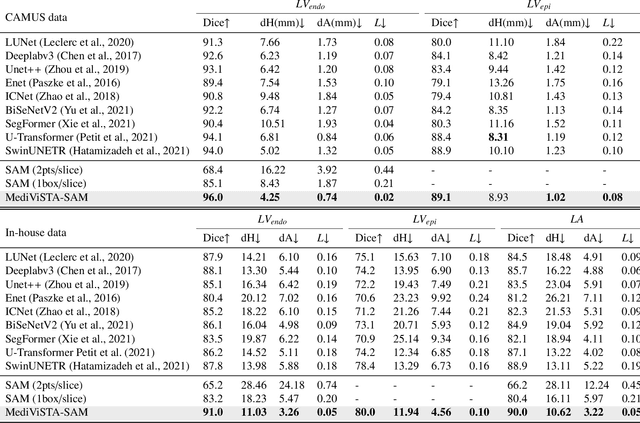
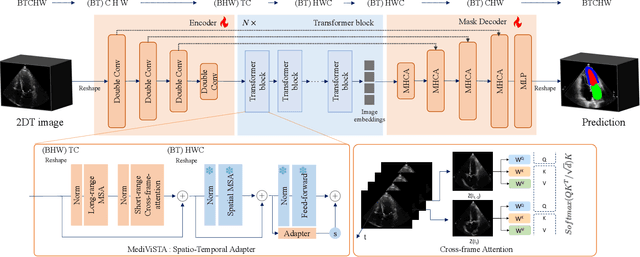
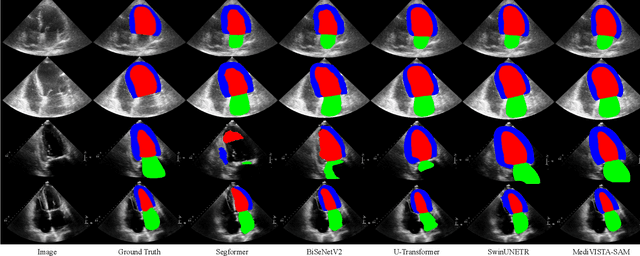
In recent years, the Segmentation Anything Model (SAM) has attracted considerable attention as a foundational model well-known for its robust generalization capabilities across various downstream tasks. However, SAM does not exhibit satisfactory performance in the realm of medical image analysis. In this study, we introduce the first study on adapting SAM on video segmentation, called MediViSTA-SAM, a novel approach designed for medical video segmentation. Given video data, MediViSTA, spatio-temporal adapter captures long and short range temporal attention with cross-frame attention mechanism effectively constraining it to consider the immediately preceding video frame as a reference, while also considering spatial information effectively. Additionally, it incorporates multi-scale fusion by employing a U-shaped encoder and a modified mask decoder to handle objects of varying sizes. To evaluate our approach, extensive experiments were conducted using state-of-the-art (SOTA) methods, assessing its generalization abilities on multi-vendor in-house echocardiography datasets. The results highlight the accuracy and effectiveness of our network in medical video segmentation.