 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Separating Content and Style for Unsupervised Image-to-Image Translation
Oct 27, 2021
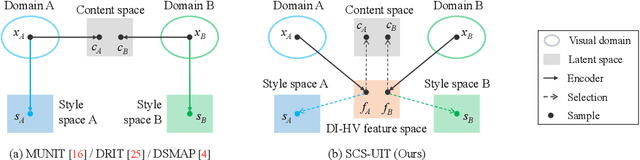
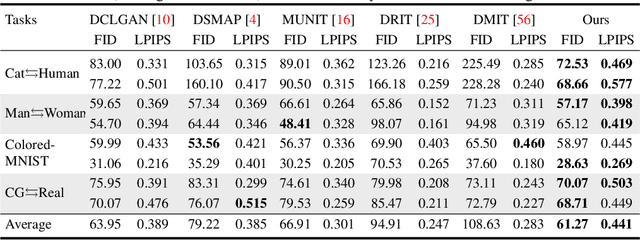
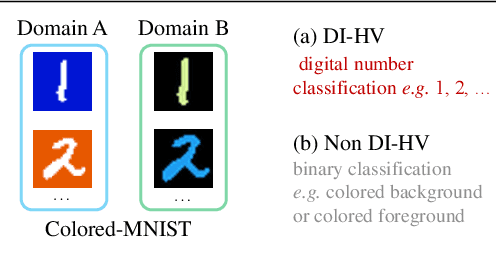
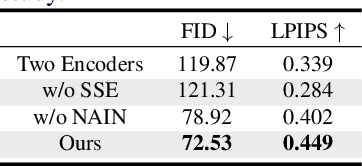
Unsupervised image-to-image translation aims to learn the mapping between two visual domains with unpaired samples. Existing works focus on disentangling domain-invariant content code and domain-specific style code individually for multimodal purposes. However, less attention has been paid to interpreting and manipulating the translated image. In this paper, we propose to separate the content code and style code simultaneously in a unified framework. Based on the correlation between the latent features and the high-level domain-invariant tasks, the proposed framework demonstrates superior performance in multimodal translation, interpretability and manipulation of the translated image. Experimental results show that the proposed approach outperforms the existing unsupervised image translation methods in terms of visual quality and diversity.
Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation
Aug 11, 2021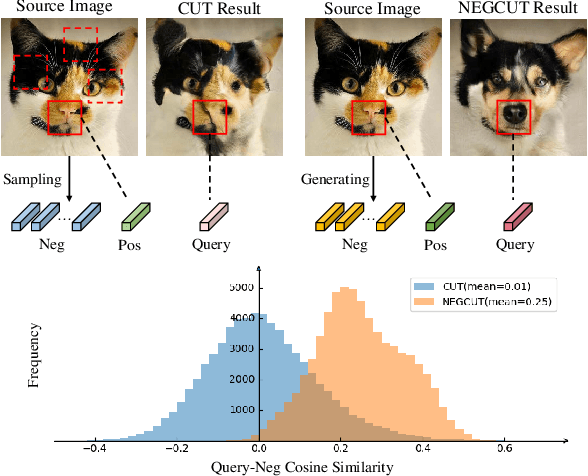
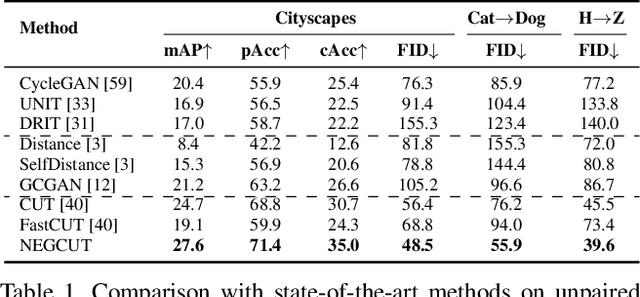
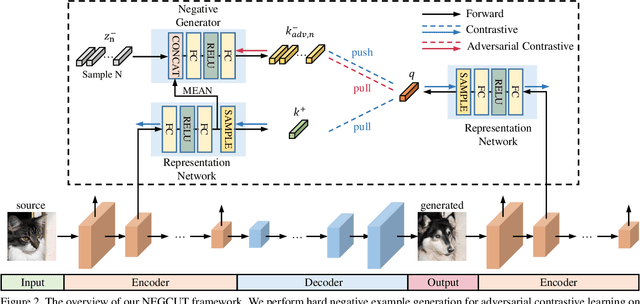
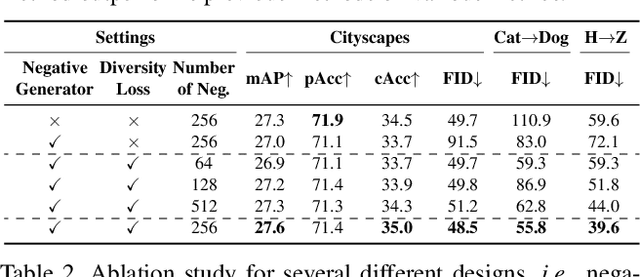
Contrastive learning shows great potential in unpaired image-to-image translation, but sometimes the translated results are in poor quality and the contents are not preserved consistently. In this paper, we uncover that the negative examples play a critical role in the performance of contrastive learning for image translation. The negative examples in previous methods are randomly sampled from the patches of different positions in the source image, which are not effective to push the positive examples close to the query examples. To address this issue, we present instance-wise hard Negative Example Generation for Contrastive learning in Unpaired image-to-image Translation (NEGCUT). Specifically, we train a generator to produce negative examples online. The generator is novel from two perspectives: 1) it is instance-wise which means that the generated examples are based on the input image, and 2) it can generate hard negative examples since it is trained with an adversarial loss. With the generator, the performance of unpaired image-to-image translation is significantly improved. Experiments on three benchmark datasets demonstrate that the proposed NEGCUT framework achieves state-of-the-art performance compared to previous methods.
Leveraging Local Domains for Image-to-Image Translation
Sep 09, 2021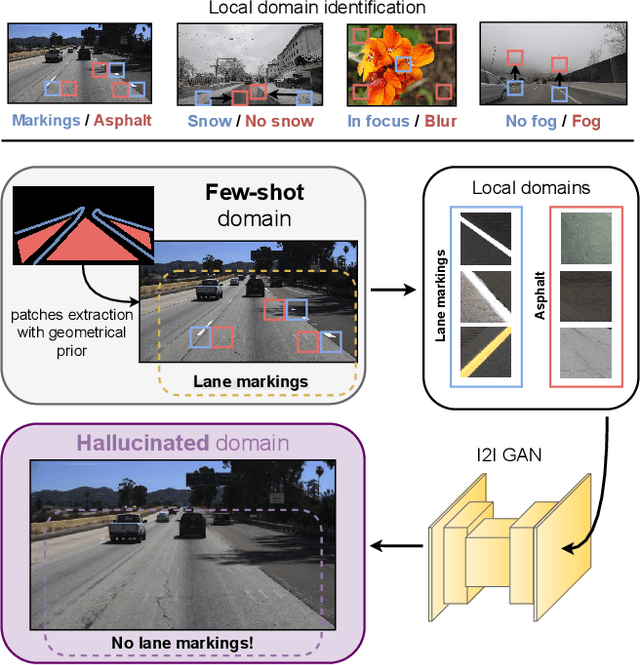

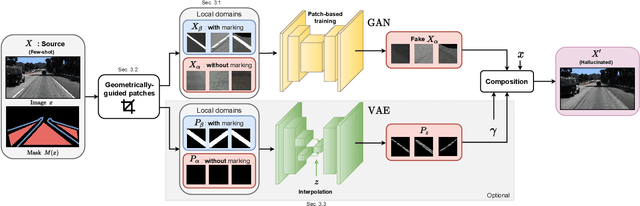
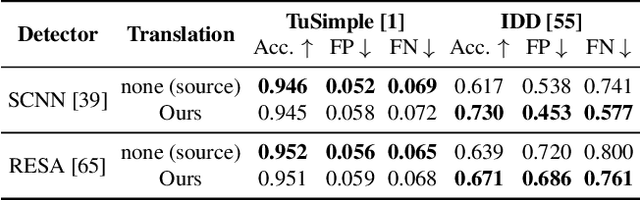
Image-to-image (i2i) networks struggle to capture local changes because they do not affect the global scene structure. For example, translating from highway scenes to offroad, i2i networks easily focus on global color features but ignore obvious traits for humans like the absence of lane markings. In this paper, we leverage human knowledge about spatial domain characteristics which we refer to as 'local domains' and demonstrate its benefit for image-to-image translation. Relying on a simple geometrical guidance, we train a patch-based GAN on few source data and hallucinate a new unseen domain which subsequently eases transfer learning to target. We experiment on three tasks ranging from unstructured environments to adverse weather. Our comprehensive evaluation setting shows we are able to generate realistic translations, with minimal priors, and training only on a few images. Furthermore, when trained on our translations images we show that all tested proxy tasks are significantly improved, without ever seeing target domain at training.
Vit-GAN: Image-to-image Translation with Vision Transformes and Conditional GANS
Oct 11, 2021



In this paper, we have developed a general-purpose architecture, Vit-Gan, capable of performing most of the image-to-image translation tasks from semantic image segmentation to single image depth perception. This paper is a follow-up paper, an extension of generator-based model [1] in which the obtained results were very promising. This opened the possibility of further improvements with adversarial architecture. We used a unique vision transformers-based generator architecture and Conditional GANs(cGANs) with a Markovian Discriminator (PatchGAN) (https://github.com/YigitGunduc/vit-gan). In the present work, we use images as conditioning arguments. It is observed that the obtained results are more realistic than the commonly used architectures.
Maximum Spatial Perturbation Consistency for Unpaired Image-to-Image Translation
Mar 29, 2022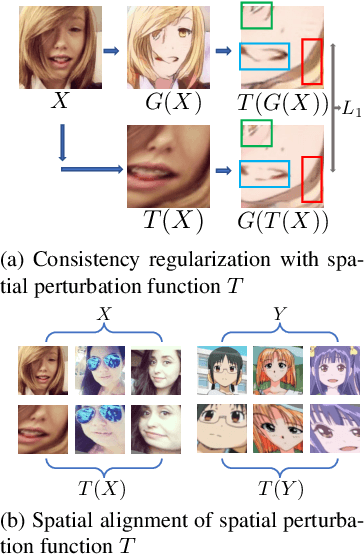
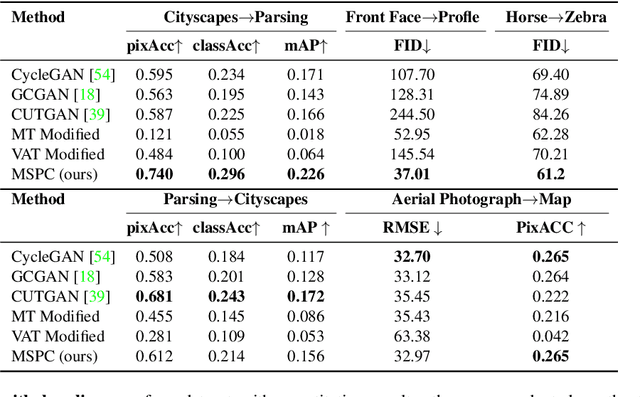
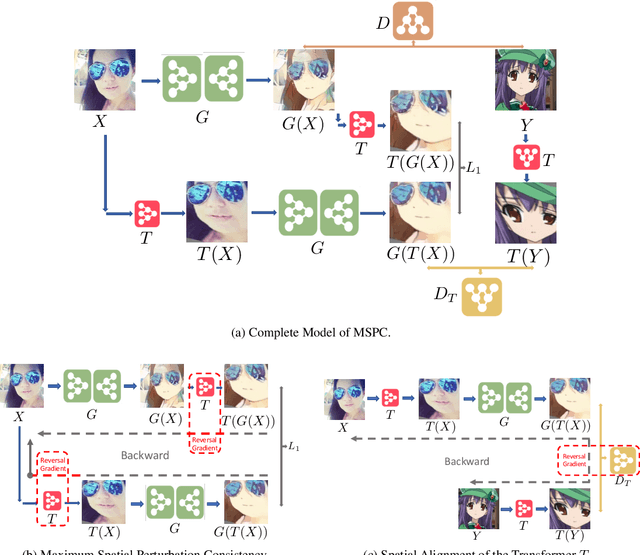

Unpaired image-to-image translation (I2I) is an ill-posed problem, as an infinite number of translation functions can map the source domain distribution to the target distribution. Therefore, much effort has been put into designing suitable constraints, e.g., cycle consistency (CycleGAN), geometry consistency (GCGAN), and contrastive learning-based constraints (CUTGAN), that help better pose the problem. However, these well-known constraints have limitations: (1) they are either too restrictive or too weak for specific I2I tasks; (2) these methods result in content distortion when there is a significant spatial variation between the source and target domains. This paper proposes a universal regularization technique called maximum spatial perturbation consistency (MSPC), which enforces a spatial perturbation function (T ) and the translation operator (G) to be commutative (i.e., TG = GT ). In addition, we introduce two adversarial training components for learning the spatial perturbation function. The first one lets T compete with G to achieve maximum perturbation. The second one lets G and T compete with discriminators to align the spatial variations caused by the change of object size, object distortion, background interruptions, etc. Our method outperforms the state-of-the-art methods on most I2I benchmarks. We also introduce a new benchmark, namely the front face to profile face dataset, to emphasize the underlying challenges of I2I for real-world applications. We finally perform ablation experiments to study the sensitivity of our method to the severity of spatial perturbation and its effectiveness for distribution alignment.
Contrastive Learning for Unpaired Image-to-Image Translation
Aug 20, 2020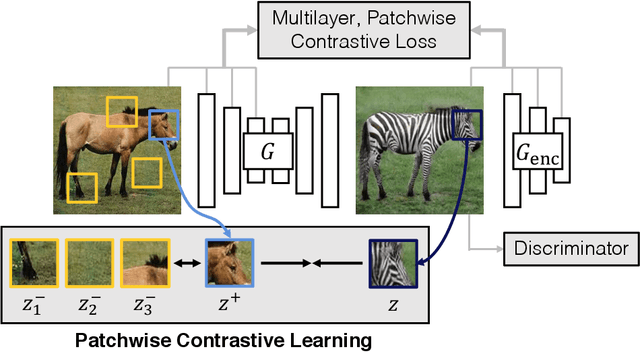
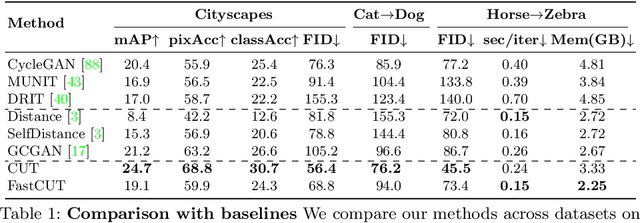
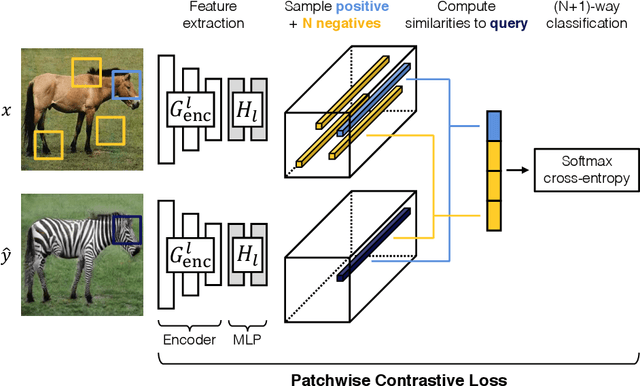
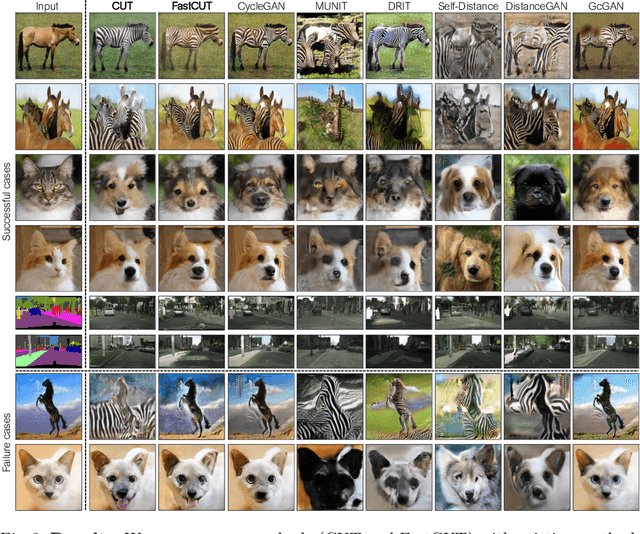
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
HalluciDet: Hallucinating RGB Modality for Person Detection Through Privileged Information
Oct 07, 2023
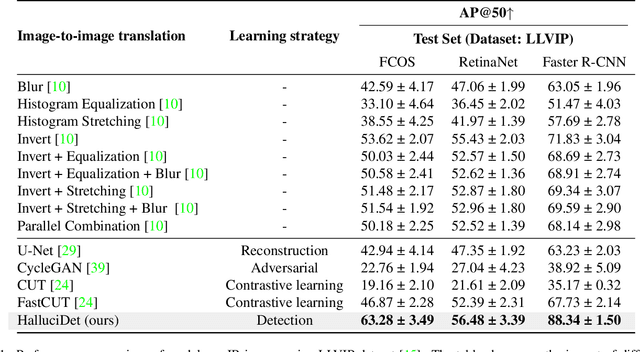
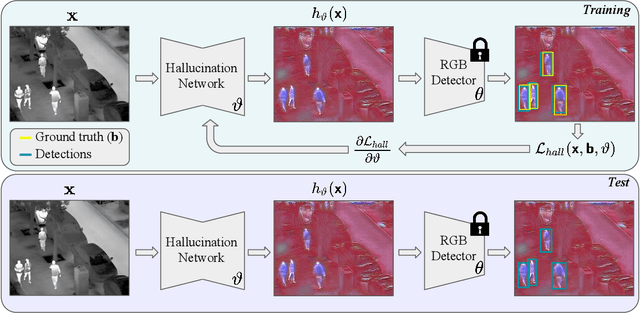
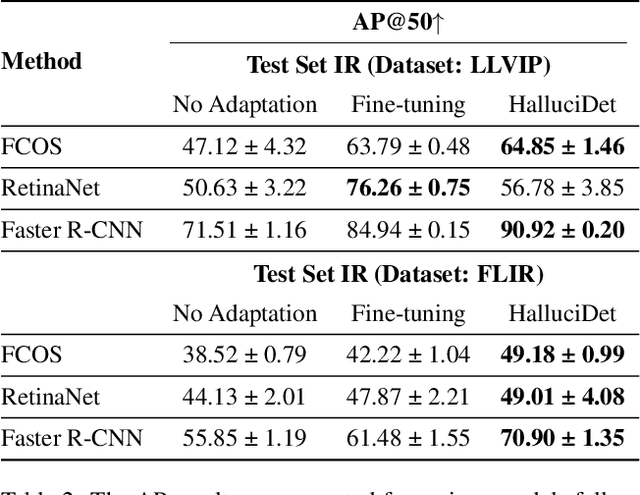
A powerful way to adapt a visual recognition model to a new domain is through image translation. However, common image translation approaches only focus on generating data from the same distribution of the target domain. In visual recognition tasks with complex images, such as pedestrian detection on aerial images with a large cross-modal shift in data distribution from Infrared (IR) to RGB images, a translation focused on generation might lead to poor performance as the loss focuses on irrelevant details for the task. In this paper, we propose HalluciDet, an IR-RGB image translation model for object detection that, instead of focusing on reconstructing the original image on the IR modality, is guided directly on reducing the detection loss of an RGB detector, and therefore avoids the need to access RGB data. This model produces a new image representation that enhances the object of interest in the scene and greatly improves detection performance. We empirically compare our approach against state-of-the-art image translation methods as well as with the commonly used fine-tuning on IR, and show that our method improves detection accuracy in most cases, by exploiting the privileged information encoded in a pre-trained RGB detector.
Image-to-Image Translation: Methods and Applications
Jan 21, 2021

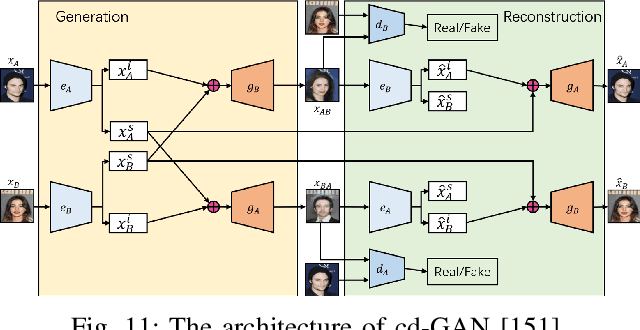
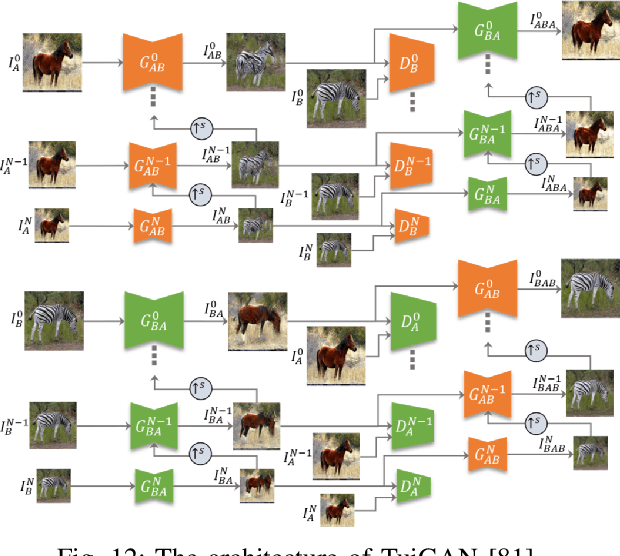
Image-to-image translation (I2I) aims to transfer images from a source domain to a target domain while preserving the content representations. I2I has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems, such as image synthesis, segmentation, style transfer, restoration, and pose estimation. In this paper, we provide an overview of the I2I works developed in recent years. We will analyze the key techniques of the existing I2I works and clarify the main progress the community has made. Additionally, we will elaborate on the effect of I2I on the research and industry community and point out remaining challenges in related fields.
Self-Supervised and Semi-Supervised Polyp Segmentation using Synthetic Data
Jul 22, 2023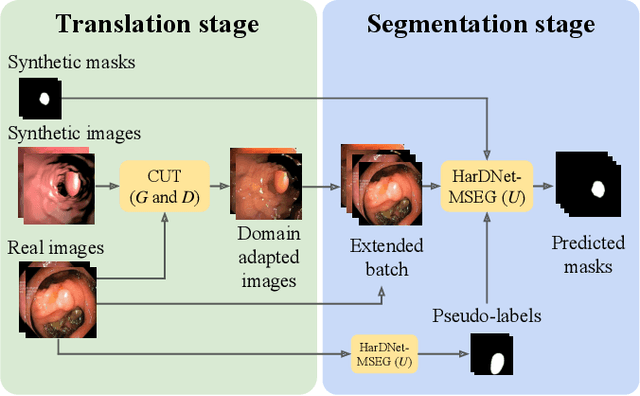
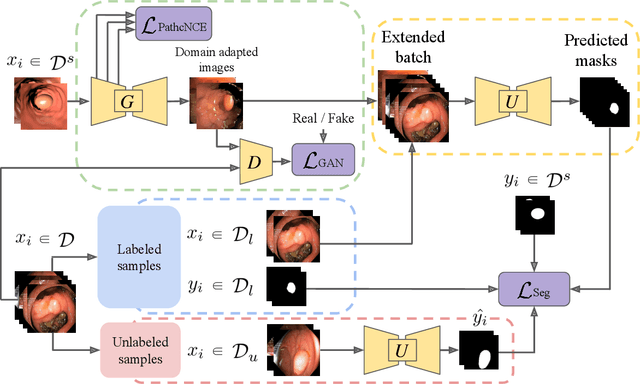
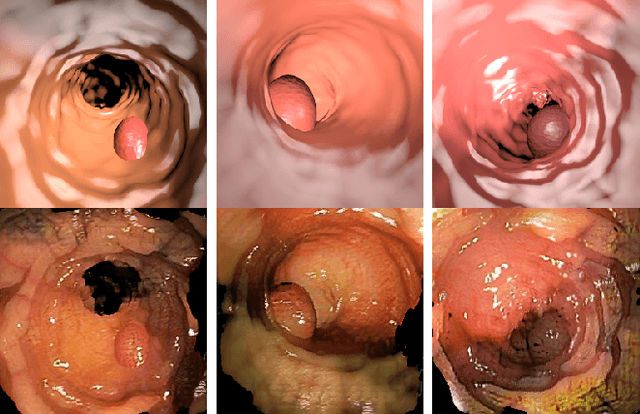
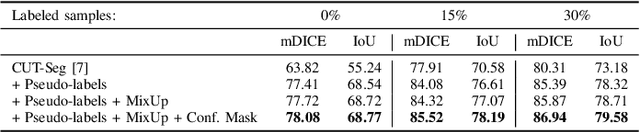
Early detection of colorectal polyps is of utmost importance for their treatment and for colorectal cancer prevention. Computer vision techniques have the potential to aid professionals in the diagnosis stage, where colonoscopies are manually carried out to examine the entirety of the patient's colon. The main challenge in medical imaging is the lack of data, and a further challenge specific to polyp segmentation approaches is the difficulty of manually labeling the available data: the annotation process for segmentation tasks is very time-consuming. While most recent approaches address the data availability challenge with sophisticated techniques to better exploit the available labeled data, few of them explore the self-supervised or semi-supervised paradigm, where the amount of labeling required is greatly reduced. To address both challenges, we leverage synthetic data and propose an end-to-end model for polyp segmentation that integrates real and synthetic data to artificially increase the size of the datasets and aid the training when unlabeled samples are available. Concretely, our model, Pl-CUT-Seg, transforms synthetic images with an image-to-image translation module and combines the resulting images with real images to train a segmentation model, where we use model predictions as pseudo-labels to better leverage unlabeled samples. Additionally, we propose PL-CUT-Seg+, an improved version of the model that incorporates targeted regularization to address the domain gap between real and synthetic images. The models are evaluated on standard benchmarks for polyp segmentation and reach state-of-the-art results in the self- and semi-supervised setups.