 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVit-GAN: Image-to-image Translation with Vision Transformes and Conditional GANS
Oct 11, 2021



In this paper, we have developed a general-purpose architecture, Vit-Gan, capable of performing most of the image-to-image translation tasks from semantic image segmentation to single image depth perception. This paper is a follow-up paper, an extension of generator-based model [1] in which the obtained results were very promising. This opened the possibility of further improvements with adversarial architecture. We used a unique vision transformers-based generator architecture and Conditional GANs(cGANs) with a Markovian Discriminator (PatchGAN) (https://github.com/YigitGunduc/vit-gan). In the present work, we use images as conditioning arguments. It is observed that the obtained results are more realistic than the commonly used architectures.
Tensor-to-Image: Image-to-Image Translation with Vision Transformers
Oct 06, 2021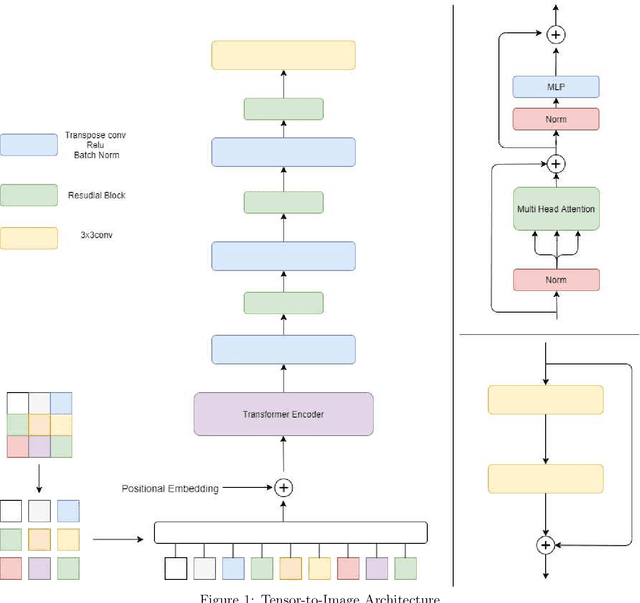


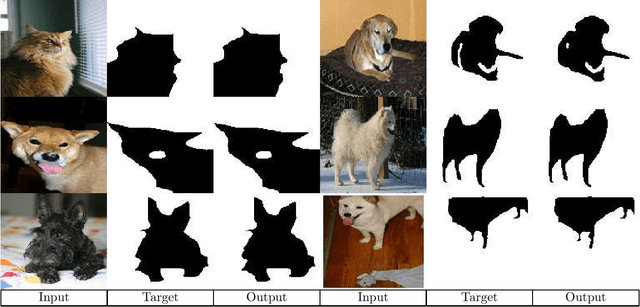
Transformers gain huge attention since they are first introduced and have a wide range of applications. Transformers start to take over all areas of deep learning and the Vision transformers paper also proved that they can be used for computer vision tasks. In this paper, we utilized a vision transformer-based custom-designed model, tensor-to-image, for the image to image translation. With the help of self-attention, our model was able to generalize and apply to different problems without a single modification.