 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine Grained Image Classification
Fine grained image classification is a task in computer vision where the goal is to classify images into subcategories within a larger category. For example, classifying different species of birds or different types of flowers. This task is considered to be fine grained because it requires the model to distinguish between subtle differences in visual appearance and patterns, making it more challenging than regular image classification tasks.
Papers and Code
Multitask GLocal OBIA-Mamba for Sentinel-2 Landcover Mapping
Nov 13, 2025Although Sentinel-2 based land use and land cover (LULC) classification is critical for various environmental monitoring applications, it is a very difficult task due to some key data challenges (e.g., spatial heterogeneity, context information, signature ambiguity). This paper presents a novel Multitask Glocal OBIA-Mamba (MSOM) for enhanced Sentinel-2 classification with the following contributions. First, an object-based image analysis (OBIA) Mamba model (OBIA-Mamba) is designed to reduce redundant computation without compromising fine-grained details by using superpixels as Mamba tokens. Second, a global-local (GLocal) dual-branch convolutional neural network (CNN)-mamba architecture is designed to jointly model local spatial detail and global contextual information. Third, a multitask optimization framework is designed to employ dual loss functions to balance local precision with global consistency. The proposed approach is tested on Sentinel-2 imagery in Alberta, Canada, in comparison with several advanced classification approaches, and the results demonstrate that the proposed approach achieves higher classification accuracy and finer details that the other state-of-the-art methods.
Adaptive Multi-Scale Integration Unlocks Robust Cell Annotation in Histopathology Images
Nov 18, 2025Identifying cell types and subtypes in routine histopathology is fundamental for understanding disease. Existing tile-based models capture nuclear detail but miss the broader tissue context that influences cell identity. Current human annotations are coarse-grained and uneven across studies, making fine-grained, subtype-level classification difficult. In this study, we build a marker-guided dataset from Xenium spatial transcriptomics with single-cell resolution labels for more than two million cells across eight organs and 16 classes to address the lack of high-quality annotations. Leveraging this data resource, we introduce NuClass, a pathologist workflow inspired framework for cell-wise multi-scale integration of nuclear morphology and microenvironmental context. It combines Path local, which focuses on nuclear morphology from 224x224 pixel crops, and Path global, which models the surrounding 1024x1024 pixel neighborhood, through a learnable gating module that balances local and global information. An uncertainty-guided objective directs the global path to prioritize regions where the local path is uncertain, and we provide calibrated confidence estimates and Grad-CAM maps for interpretability. Evaluated on three fully held-out cohorts, NuClass achieves up to 96 percent F1 for its best-performing class, outperforming strong baselines. Our results demonstrate that multi-scale, uncertainty-aware fusion can bridge the gap between slide-level pathological foundation models and reliable, cell-level phenotype prediction.
FarSLIP: Discovering Effective CLIP Adaptation for Fine-Grained Remote Sensing Understanding
Nov 18, 2025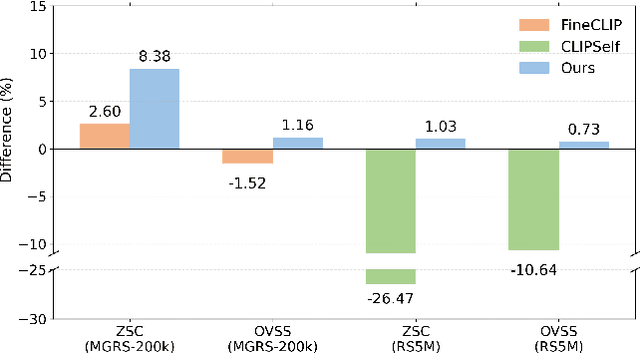
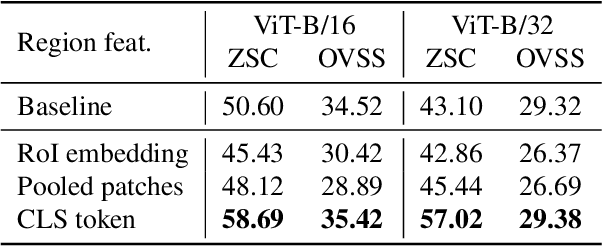
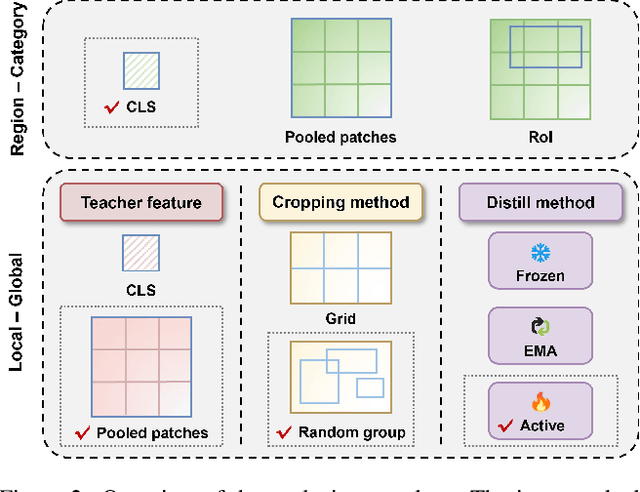
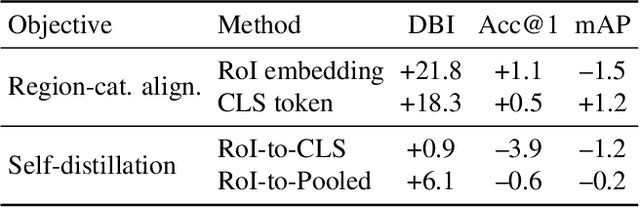
As CLIP's global alignment limits its ability to capture fine-grained details, recent efforts have focused on enhancing its region-text alignment. However, current remote sensing (RS)-specific CLIP variants still inherit this limited spatial awareness. We identify two key limitations behind this: (1) current RS image-text datasets generate global captions from object-level labels, leaving the original object-level supervision underutilized; (2) despite the success of region-text alignment methods in general domain, their direct application to RS data often leads to performance degradation. To address these, we construct the first multi-granularity RS image-text dataset, MGRS-200k, featuring rich object-level textual supervision for RS region-category alignment. We further investigate existing fine-grained CLIP tuning strategies and find that current explicit region-text alignment methods, whether in a direct or indirect way, underperform due to severe degradation of CLIP's semantic coherence. Building on these, we propose FarSLIP, a Fine-grained Aligned RS Language-Image Pretraining framework. Rather than the commonly used patch-to-CLS self-distillation, FarSLIP employs patch-to-patch distillation to align local and global visual cues, which improves feature discriminability while preserving semantic coherence. Additionally, to effectively utilize region-text supervision, it employs simple CLS token-based region-category alignment rather than explicit patch-level alignment, further enhancing spatial awareness. FarSLIP features improved fine-grained vision-language alignment in RS domain and sets a new state of the art not only on RS open-vocabulary semantic segmentation, but also on image-level tasks such as zero-shot classification and image-text retrieval. Our dataset, code, and models are available at https://github.com/NJU-LHRS/FarSLIP.
Modeling Clinical Uncertainty in Radiology Reports: from Explicit Uncertainty Markers to Implicit Reasoning Pathways
Nov 06, 2025



Radiology reports are invaluable for clinical decision-making and hold great potential for automated analysis when structured into machine-readable formats. These reports often contain uncertainty, which we categorize into two distinct types: (i) Explicit uncertainty reflects doubt about the presence or absence of findings, conveyed through hedging phrases. These vary in meaning depending on the context, making rule-based systems insufficient to quantify the level of uncertainty for specific findings; (ii) Implicit uncertainty arises when radiologists omit parts of their reasoning, recording only key findings or diagnoses. Here, it is often unclear whether omitted findings are truly absent or simply unmentioned for brevity. We address these challenges with a two-part framework. We quantify explicit uncertainty by creating an expert-validated, LLM-based reference ranking of common hedging phrases, and mapping each finding to a probability value based on this reference. In addition, we model implicit uncertainty through an expansion framework that systematically adds characteristic sub-findings derived from expert-defined diagnostic pathways for 14 common diagnoses. Using these methods, we release Lunguage++, an expanded, uncertainty-aware version of the Lunguage benchmark of fine-grained structured radiology reports. This enriched resource enables uncertainty-aware image classification, faithful diagnostic reasoning, and new investigations into the clinical impact of diagnostic uncertainty.
FaNe: Towards Fine-Grained Cross-Modal Contrast with False-Negative Reduction and Text-Conditioned Sparse Attention
Nov 15, 2025Medical vision-language pre-training (VLP) offers significant potential for advancing medical image understanding by leveraging paired image-report data. However, existing methods are limited by Fa}lse Negatives (FaNe) induced by semantically similar texts and insufficient fine-grained cross-modal alignment. To address these limitations, we propose FaNe, a semantic-enhanced VLP framework. To mitigate false negatives, we introduce a semantic-aware positive pair mining strategy based on text-text similarity with adaptive normalization. Furthermore, we design a text-conditioned sparse attention pooling module to enable fine-grained image-text alignment through localized visual representations guided by textual cues. To strengthen intra-modal discrimination, we develop a hard-negative aware contrastive loss that adaptively reweights semantically similar negatives. Extensive experiments on five downstream medical imaging benchmarks demonstrate that FaNe achieves state-of-the-art performance across image classification, object detection, and semantic segmentation, validating the effectiveness of our framework.
Hierarchical Prompt Learning for Image- and Text-Based Person Re-Identification
Nov 17, 2025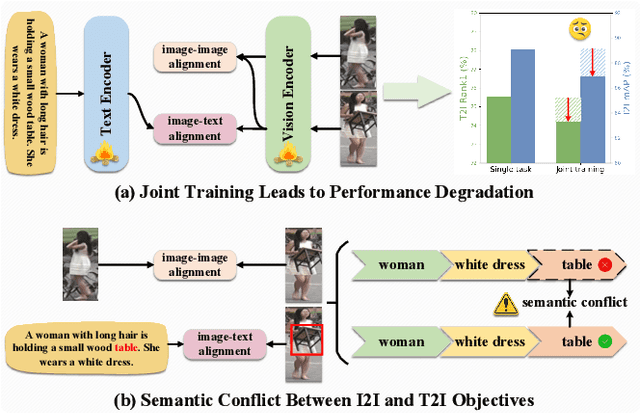
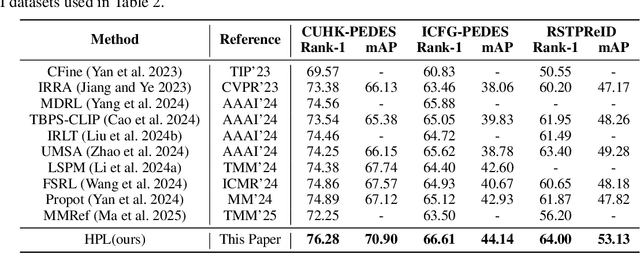
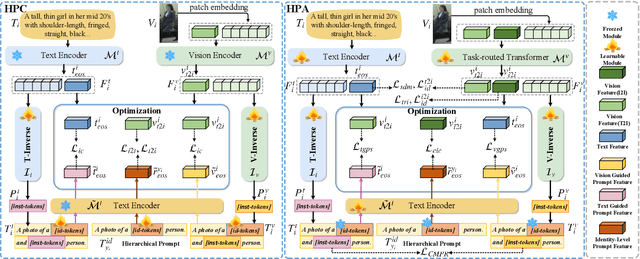
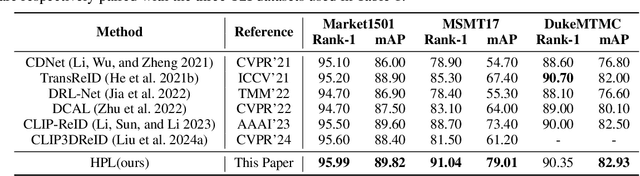
Person re-identification (ReID) aims to retrieve target pedestrian images given either visual queries (image-to-image, I2I) or textual descriptions (text-to-image, T2I). Although both tasks share a common retrieval objective, they pose distinct challenges: I2I emphasizes discriminative identity learning, while T2I requires accurate cross-modal semantic alignment. Existing methods often treat these tasks separately, which may lead to representation entanglement and suboptimal performance. To address this, we propose a unified framework named Hierarchical Prompt Learning (HPL), which leverages task-aware prompt modeling to jointly optimize both tasks. Specifically, we first introduce a Task-Routed Transformer, which incorporates dual classification tokens into a shared visual encoder to route features for I2I and T2I branches respectively. On top of this, we develop a hierarchical prompt generation scheme that integrates identity-level learnable tokens with instance-level pseudo-text tokens. These pseudo-tokens are derived from image or text features via modality-specific inversion networks, injecting fine-grained, instance-specific semantics into the prompts. Furthermore, we propose a Cross-Modal Prompt Regularization strategy to enforce semantic alignment in the prompt token space, ensuring that pseudo-prompts preserve source-modality characteristics while enhancing cross-modal transferability. Extensive experiments on multiple ReID benchmarks validate the effectiveness of our method, achieving state-of-the-art performance on both I2I and T2I tasks.
ProtoAnomalyNCD: Prototype Learning for Multi-class Novel Anomaly Discovery in Industrial Scenarios
Nov 17, 2025Existing industrial anomaly detection methods mainly determine whether an anomaly is present. However, real-world applications also require discovering and classifying multiple anomaly types. Since industrial anomalies are semantically subtle and current methods do not sufficiently exploit image priors, direct clustering approaches often perform poorly. To address these challenges, we propose ProtoAnomalyNCD, a prototype-learning-based framework for discovering unseen anomaly classes of multiple types that can be integrated with various anomaly detection methods. First, to suppress background clutter, we leverage Grounded SAM with text prompts to localize object regions as priors for the anomaly classification network. Next, because anomalies usually appear as subtle and fine-grained patterns on the product, we introduce an Anomaly-Map-Guided Attention block. Within this block, we design a Region Guidance Factor that helps the attention module distinguish among background, object regions, and anomalous regions. By using both localized product regions and anomaly maps as priors, the module enhances anomalous features while suppressing background noise and preserving normal features for contrastive learning. Finally, under a unified prototype-learning framework, ProtoAnomalyNCD discovers and clusters unseen anomaly classes while simultaneously enabling multi-type anomaly classification. We further extend our method to detect unseen outliers, achieving task-level unification. Our method outperforms state-of-the-art approaches on the MVTec AD, MTD, and Real-IAD datasets.
LampQ: Towards Accurate Layer-wise Mixed Precision Quantization for Vision Transformers
Nov 14, 2025



How can we accurately quantize a pre-trained Vision Transformer model? Quantization algorithms compress Vision Transformers (ViTs) into low-bit formats, reducing memory and computation demands with minimal accuracy degradation. However, existing methods rely on uniform precision, ignoring the diverse sensitivity of ViT components to quantization. Metric-based Mixed Precision Quantization (MPQ) is a promising alternative, but previous MPQ methods for ViTs suffer from three major limitations: 1) coarse granularity, 2) mismatch in metric scale across component types, and 3) quantization-unaware bit allocation. In this paper, we propose LampQ (Layer-wise Mixed Precision Quantization for Vision Transformers), an accurate metric-based MPQ method for ViTs to overcome these limitations. LampQ performs layer-wise quantization to achieve both fine-grained control and efficient acceleration, incorporating a type-aware Fisher-based metric to measure sensitivity. Then, LampQ assigns bit-widths optimally through integer linear programming and further updates them iteratively. Extensive experiments show that LampQ provides the state-of-the-art performance in quantizing ViTs pre-trained on various tasks such as image classification, object detection, and zero-shot quantization.
FedeCouple: Fine-Grained Balancing of Global-Generalization and Local-Adaptability in Federated Learning
Nov 12, 2025



In privacy-preserving mobile network transmission scenarios with heterogeneous client data, personalized federated learning methods that decouple feature extractors and classifiers have demonstrated notable advantages in enhancing learning capability. However, many existing approaches primarily focus on feature space consistency and classification personalization during local training, often neglecting the local adaptability of the extractor and the global generalization of the classifier. This oversight results in insufficient coordination and weak coupling between the components, ultimately degrading the overall model performance. To address this challenge, we propose FedeCouple, a federated learning method that balances global generalization and local adaptability at a fine-grained level. Our approach jointly learns global and local feature representations while employing dynamic knowledge distillation to enhance the generalization of personalized classifiers. We further introduce anchors to refine the feature space; their strict locality and non-transmission inherently preserve privacy and reduce communication overhead. Furthermore, we provide a theoretical analysis proving that FedeCouple converges for nonconvex objectives, with iterates approaching a stationary point as the number of communication rounds increases. Extensive experiments conducted on five image-classification datasets demonstrate that FedeCouple consistently outperforms nine baseline methods in effectiveness, stability, scalability, and security. Notably, in experiments evaluating effectiveness, FedeCouple surpasses the best baseline by a significant margin of 4.3%.
Talk, Snap, Complain: Validation-Aware Multimodal Expert Framework for Fine-Grained Customer Grievances
Nov 18, 2025Existing approaches to complaint analysis largely rely on unimodal, short-form content such as tweets or product reviews. This work advances the field by leveraging multimodal, multi-turn customer support dialogues, where users often share both textual complaints and visual evidence (e.g., screenshots, product photos) to enable fine-grained classification of complaint aspects and severity. We introduce VALOR, a Validation-Aware Learner with Expert Routing, tailored for this multimodal setting. It employs a multi-expert reasoning setup using large-scale generative models with Chain-of-Thought (CoT) prompting for nuanced decision-making. To ensure coherence between modalities, a semantic alignment score is computed and integrated into the final classification through a meta-fusion strategy. In alignment with the United Nations Sustainable Development Goals (UN SDGs), the proposed framework supports SDG 9 (Industry, Innovation and Infrastructure) by advancing AI-driven tools for robust, scalable, and context-aware service infrastructure. Further, by enabling structured analysis of complaint narratives and visual context, it contributes to SDG 12 (Responsible Consumption and Production) by promoting more responsive product design and improved accountability in consumer services. We evaluate VALOR on a curated multimodal complaint dataset annotated with fine-grained aspect and severity labels, showing that it consistently outperforms baseline models, especially in complex complaint scenarios where information is distributed across text and images. This study underscores the value of multimodal interaction and expert validation in practical complaint understanding systems. Resources related to data and codes are available here: https://github.com/sarmistha-D/VALOR