 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning from Structural Invariance
Feb 02, 2026Joint-embedding self-supervised learning (SSL), the key paradigm for unsupervised representation learning from visual data, learns from invariances between semantically-related data pairs. We study the one-to-many mapping problem in SSL, where each datum may be mapped to multiple valid targets. This arises when data pairs come from naturally occurring generative processes, e.g., successive video frames. We show that existing methods struggle to flexibly capture this conditional uncertainty. As a remedy, we introduce a latent variable to account for this uncertainty and derive a variational lower bound on the mutual information between paired embeddings. Our derivation yields a simple regularization term for standard SSL objectives. The resulting method, which we call AdaSSL, applies to both contrastive and distillation-based SSL objectives, and we empirically show its versatility in causal representation learning, fine-grained image understanding, and world modeling on videos.
seq-JEPA: Autoregressive Predictive Learning of Invariant-Equivariant World Models
May 06, 2025Current self-supervised algorithms mostly rely on transformations such as data augmentation and masking to learn visual representations. This is achieved by inducing invariance or equivariance with respect to these transformations after encoding two views of an image. This dominant two-view paradigm can limit the flexibility of learned representations for downstream adaptation by creating performance trade-offs between invariance-related tasks such as image classification and more fine-grained equivariance-related tasks. In this work, we introduce \emph{seq-JEPA}, a world modeling paradigm based on joint-embedding predictive architecture that leverages architectural inductive biases to resolve this trade-off. Without requiring an additional equivariance predictor or loss term, seq-JEPA simultaneously learns two architecturally segregated representations: one equivariant to the specified transformations and another invariant to them and suited for tasks such as classification. To do so, our model processes a short sequence of different views (observations) of an input image. Each encoded view is concatenated with embeddings corresponding to the relative transformation (action) producing the next observation in the sequence. A transformer encoder outputs an aggregate representation of this sequence, which is subsequently conditioned on the action leading to the next observation to predict its representation. Empirically, seq-JEPA achieves strong performance on equivariant benchmarks and image classification without sacrificing one for the other. Additionally, our framework excels at tasks that inherently require aggregating a sequence of observations, such as path integration across actions and predictive learning across eye movements.
Risk Sensitivity in Markov Games and Multi-Agent Reinforcement Learning: A Systematic Review
Jun 10, 2024

Markov games (MGs) and multi-agent reinforcement learning (MARL) are studied to model decision making in multi-agent systems. Traditionally, the objective in MG and MARL has been risk-neutral, i.e., agents are assumed to optimize a performance metric such as expected return, without taking into account subjective or cognitive preferences of themselves or of other agents. However, ignoring such preferences leads to inaccurate models of decision making in many real-world scenarios in finance, operations research, and behavioral economics. Therefore, when these preferences are present, it is necessary to incorporate a suitable measure of risk into the optimization objective of agents, which opens the door to risk-sensitive MG and MARL. In this paper, we systemically review the literature on risk sensitivity in MG and MARL that has been growing in recent years alongside other areas of reinforcement learning and game theory. We define and mathematically describe different risk measures used in MG and MARL and individually for each measure, discuss articles that incorporate it. Finally, we identify recent trends in theoretical and applied works in the field and discuss possible directions of future research.
Risk-Sensitive Multi-Agent Reinforcement Learning in Network Aggregative Markov Games
Feb 08, 2024Classical multi-agent reinforcement learning (MARL) assumes risk neutrality and complete objectivity for agents. However, in settings where agents need to consider or model human economic or social preferences, a notion of risk must be incorporated into the RL optimization problem. This will be of greater importance in MARL where other human or non-human agents are involved, possibly with their own risk-sensitive policies. In this work, we consider risk-sensitive and non-cooperative MARL with cumulative prospect theory (CPT), a non-convex risk measure and a generalization of coherent measures of risk. CPT is capable of explaining loss aversion in humans and their tendency to overestimate/underestimate small/large probabilities. We propose a distributed sampling-based actor-critic (AC) algorithm with CPT risk for network aggregative Markov games (NAMGs), which we call Distributed Nested CPT-AC. Under a set of assumptions, we prove the convergence of the algorithm to a subjective notion of Markov perfect Nash equilibrium in NAMGs. The experimental results show that subjective CPT policies obtained by our algorithm can be different from the risk-neutral ones, and agents with a higher loss aversion are more inclined to socially isolate themselves in an NAMG.
BioLCNet: Reward-modulated Locally Connected Spiking Neural Networks
Sep 12, 2021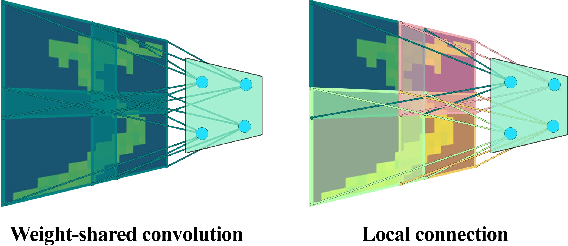
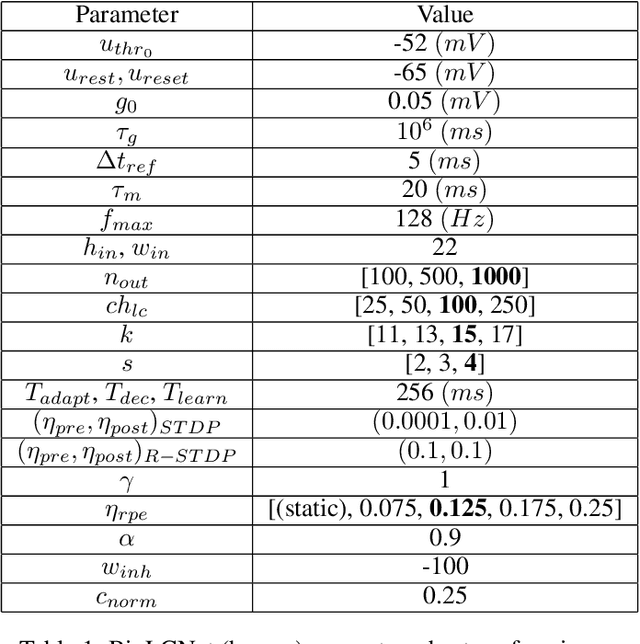
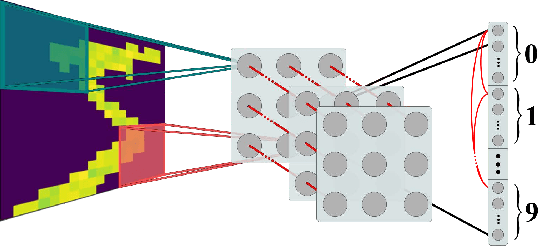

Recent studies have shown that convolutional neural networks (CNNs) are not the only feasible solution for image classification. Furthermore, weight sharing and backpropagation used in CNNs do not correspond to the mechanisms present in the primate visual system. To propose a more biologically plausible solution, we designed a locally connected spiking neural network (SNN) trained using spike-timing-dependent plasticity (STDP) and its reward-modulated variant (R-STDP) learning rules. The use of spiking neurons and local connections along with reinforcement learning (RL) led us to the nomenclature BioLCNet for our proposed architecture. Our network consists of a rate-coded input layer followed by a locally connected hidden layer and a decoding output layer. A spike population-based voting scheme is adopted for decoding in the output layer. We used the MNIST dataset to obtain image classification accuracy and to assess the robustness of our rewarding system to varying target responses.
Toward Real-World BCI: CCSPNet, A Compact Subject-Independent Motor Imagery Framework
Jan 02, 2021
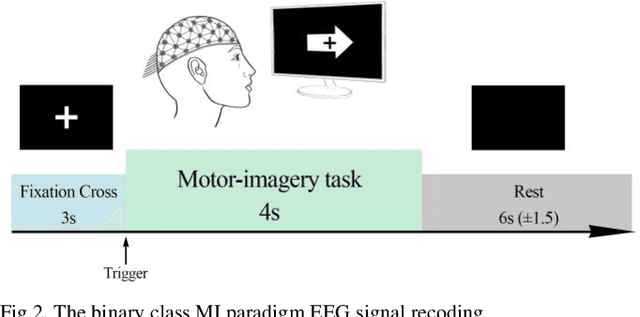
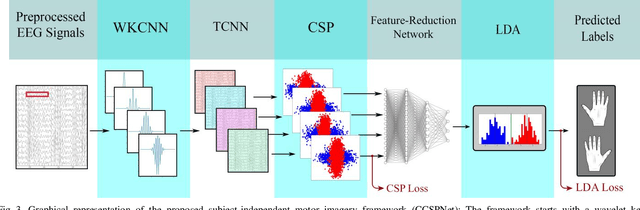
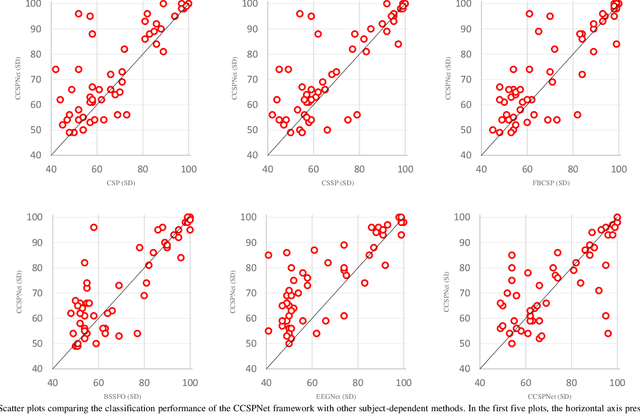
A conventional brain-computer interface (BCI) requires a complete data gathering, training, and calibration phase for each user before it can be used. This preliminary phase is time-consuming and should be done under the supervision of technical experts commonly in laboratories for the BCI to function properly. In recent years, a number of subject-independent (SI) BCIs have been developed. However, there are many problems preventing them from being used in real-world BCI applications. A lower accuracy than the subject-dependent (SD) approach and a relatively high run-time of models with a large number of model parameters are the most important ones. Therefore, a real-world BCI application would greatly benefit from a compact subject-independent BCI framework, ready to use immediately after the user puts it on, and suitable for low-power edge-computing and applications in the emerging area of internet of things (IoT). We propose a novel subject-independent BCI framework named CCSPNet (Convolutional Common Spatial Pattern Network) that is trained on the motor imagery (MI) paradigm of a large-scale EEG signals database consisting of 400 trials for every 54 subjects performing two-class hand-movement MI tasks. The proposed framework applies a wavelet kernel convolutional neural network (WKCNN) and a temporal convolutional neural network (TCNN) in order to represent and extract the diverse frequency behavior and spectral patterns of EEG signals. The convolutional layers outputs go through a CSP algorithm for class discrimination and spatial feature extraction. The number of CSP features is reduced by a dense neural network, and the final class label is determined by an LDA. The final SD and SI classification accuracies of the proposed framework match the best results obtained on the largest motor-imagery dataset present in the BCI literature, with 99.993 percent fewer model parameters.