 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Reference Image Quality Assessment
No-reference image quality assessment is the process of evaluating the quality of an image without a reference image for comparison.
Papers and Code
Metrics that matter: Evaluating image quality metrics for medical image generation
May 12, 2025Evaluating generative models for synthetic medical imaging is crucial yet challenging, especially given the high standards of fidelity, anatomical accuracy, and safety required for clinical applications. Standard evaluation of generated images often relies on no-reference image quality metrics when ground truth images are unavailable, but their reliability in this complex domain is not well established. This study comprehensively assesses commonly used no-reference image quality metrics using brain MRI data, including tumour and vascular images, providing a representative exemplar for the field. We systematically evaluate metric sensitivity to a range of challenges, including noise, distribution shifts, and, critically, localised morphological alterations designed to mimic clinically relevant inaccuracies. We then compare these metric scores against model performance on a relevant downstream segmentation task, analysing results across both controlled image perturbations and outputs from different generative model architectures. Our findings reveal significant limitations: many widely-used no-reference image quality metrics correlate poorly with downstream task suitability and exhibit a profound insensitivity to localised anatomical details crucial for clinical validity. Furthermore, these metrics can yield misleading scores regarding distribution shifts, e.g. data memorisation. This reveals the risk of misjudging model readiness, potentially leading to the deployment of flawed tools that could compromise patient safety. We conclude that ensuring generative models are truly fit for clinical purpose requires a multifaceted validation framework, integrating performance on relevant downstream tasks with the cautious interpretation of carefully selected no-reference image quality metrics.
CAS-IQA: Teaching Vision-Language Models for Synthetic Angiography Quality Assessment
May 23, 2025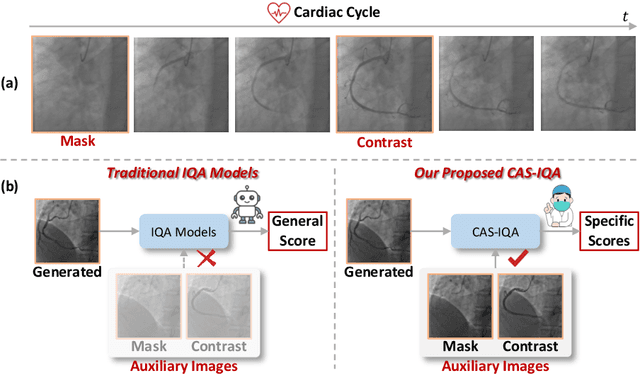
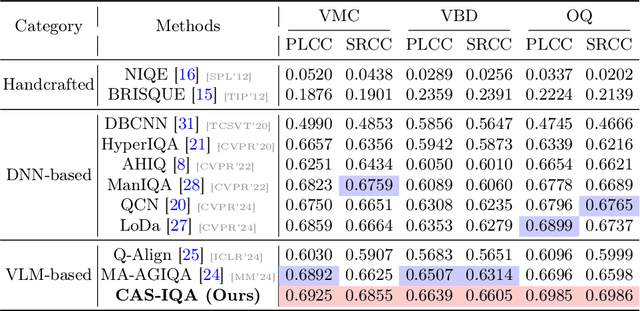
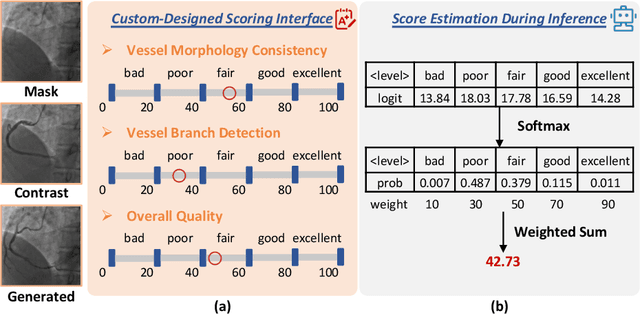

Synthetic X-ray angiographies generated by modern generative models hold great potential to reduce the use of contrast agents in vascular interventional procedures. However, low-quality synthetic angiographies can significantly increase procedural risk, underscoring the need for reliable image quality assessment (IQA) methods. Existing IQA models, however, fail to leverage auxiliary images as references during evaluation and lack fine-grained, task-specific metrics necessary for clinical relevance. To address these limitations, this paper proposes CAS-IQA, a vision-language model (VLM)-based framework that predicts fine-grained quality scores by effectively incorporating auxiliary information from related images. In the absence of angiography datasets, CAS-3K is constructed, comprising 3,565 synthetic angiographies along with score annotations. To ensure clinically meaningful assessment, three task-specific evaluation metrics are defined. Furthermore, a Multi-path featUre fuSion and rouTing (MUST) module is designed to enhance image representations by adaptively fusing and routing visual tokens to metric-specific branches. Extensive experiments on the CAS-3K dataset demonstrate that CAS-IQA significantly outperforms state-of-the-art IQA methods by a considerable margin.
Generative Image Compression by Estimating Gradients of the Rate-variable Feature Distribution
May 27, 2025While learned image compression (LIC) focuses on efficient data transmission, generative image compression (GIC) extends this framework by integrating generative modeling to produce photo-realistic reconstructed images. In this paper, we propose a novel diffusion-based generative modeling framework tailored for generative image compression. Unlike prior diffusion-based approaches that indirectly exploit diffusion modeling, we reinterpret the compression process itself as a forward diffusion path governed by stochastic differential equations (SDEs). A reverse neural network is trained to reconstruct images by reversing the compression process directly, without requiring Gaussian noise initialization. This approach achieves smooth rate adjustment and photo-realistic reconstructions with only a minimal number of sampling steps. Extensive experiments on benchmark datasets demonstrate that our method outperforms existing generative image compression approaches across a range of metrics, including perceptual distortion, statistical fidelity, and no-reference quality assessments.
Content-Distortion High-Order Interaction for Blind Image Quality Assessment
Apr 07, 2025



The content and distortion are widely recognized as the two primary factors affecting the visual quality of an image. While existing No-Reference Image Quality Assessment (NR-IQA) methods have modeled these factors, they fail to capture the complex interactions between content and distortions. This shortfall impairs their ability to accurately perceive quality. To confront this, we analyze the key properties required for interaction modeling and propose a robust NR-IQA approach termed CoDI-IQA (Content-Distortion high-order Interaction for NR-IQA), which aggregates local distortion and global content features within a hierarchical interaction framework. Specifically, a Progressive Perception Interaction Module (PPIM) is proposed to explicitly simulate how content and distortions independently and jointly influence image quality. By integrating internal interaction, coarse interaction, and fine interaction, it achieves high-order interaction modeling that allows the model to properly represent the underlying interaction patterns. To ensure sufficient interaction, multiple PPIMs are employed to hierarchically fuse multi-level content and distortion features at different granularities. We also tailor a training strategy suited for CoDI-IQA to maintain interaction stability. Extensive experiments demonstrate that the proposed method notably outperforms the state-of-the-art methods in terms of prediction accuracy, data efficiency, and generalization ability.
Toward Generalized Image Quality Assessment: Relaxing the Perfect Reference Quality Assumption
Mar 14, 2025



Full-reference image quality assessment (FR-IQA) generally assumes that reference images are of perfect quality. However, this assumption is flawed due to the sensor and optical limitations of modern imaging systems. Moreover, recent generative enhancement methods are capable of producing images of higher quality than their original. All of these challenge the effectiveness and applicability of current FR-IQA models. To relax the assumption of perfect reference image quality, we build a large-scale IQA database, namely DiffIQA, containing approximately 180,000 images generated by a diffusion-based image enhancer with adjustable hyper-parameters. Each image is annotated by human subjects as either worse, similar, or better quality compared to its reference. Building on this, we present a generalized FR-IQA model, namely Adaptive Fidelity-Naturalness Evaluator (A-FINE), to accurately assess and adaptively combine the fidelity and naturalness of a test image. A-FINE aligns well with standard FR-IQA when the reference image is much more natural than the test image. We demonstrate by extensive experiments that A-FINE surpasses standard FR-IQA models on well-established IQA datasets and our newly created DiffIQA. To further validate A-FINE, we additionally construct a super-resolution IQA benchmark (SRIQA-Bench), encompassing test images derived from ten state-of-the-art SR methods with reliable human quality annotations. Tests on SRIQA-Bench re-affirm the advantages of A-FINE. The code and dataset are available at https://tianhewu.github.io/A-FINE-page.github.io/.
VisualQuality-R1: Reasoning-Induced Image Quality Assessment via Reinforcement Learning to Rank
May 20, 2025



DeepSeek-R1 has demonstrated remarkable effectiveness in incentivizing reasoning and generalization capabilities of large language models (LLMs) through reinforcement learning. Nevertheless, the potential of reasoning-induced computational modeling has not been thoroughly explored in the context of image quality assessment (IQA), a task critically dependent on visual reasoning. In this paper, we introduce VisualQuality-R1, a reasoning-induced no-reference IQA (NR-IQA) model, and we train it with reinforcement learning to rank, a learning algorithm tailored to the intrinsically relative nature of visual quality. Specifically, for a pair of images, we employ group relative policy optimization to generate multiple quality scores for each image. These estimates are then used to compute comparative probabilities of one image having higher quality than the other under the Thurstone model. Rewards for each quality estimate are defined using continuous fidelity measures rather than discretized binary labels. Extensive experiments show that the proposed VisualQuality-R1 consistently outperforms discriminative deep learning-based NR-IQA models as well as a recent reasoning-induced quality regression method. Moreover, VisualQuality-R1 is capable of generating contextually rich, human-aligned quality descriptions, and supports multi-dataset training without requiring perceptual scale realignment. These features make VisualQuality-R1 especially well-suited for reliably measuring progress in a wide range of image processing tasks like super-resolution and image generation.
Interpretation of Deep Learning Model in Embryo Selection for In Vitro Fertilization (IVF) Treatment
Jun 07, 2025Infertility has a considerable impact on individuals' quality of life, affecting them socially and psychologically, with projections indicating a rise in the upcoming years. In vitro fertilization (IVF) emerges as one of the primary techniques within economically developed nations, employed to address the rising problem of low fertility. Expert embryologists conventionally grade embryos by reviewing blastocyst images to select the most optimal for transfer, yet this process is time-consuming and lacks efficiency. Blastocyst images provide a valuable resource for assessing embryo viability. In this study, we introduce an explainable artificial intelligence (XAI) framework for classifying embryos, employing a fusion of convolutional neural network (CNN) and long short-term memory (LSTM) architecture, referred to as CNN-LSTM. Utilizing deep learning, our model achieves high accuracy in embryo classification while maintaining interpretability through XAI.
Don't Judge Before You CLIP: A Unified Approach for Perceptual Tasks
Mar 17, 2025



Visual perceptual tasks aim to predict human judgment of images (e.g., emotions invoked by images, image quality assessment). Unlike objective tasks such as object/scene recognition, perceptual tasks rely on subjective human assessments, making its data-labeling difficult. The scarcity of such human-annotated data results in small datasets leading to poor generalization. Typically, specialized models were designed for each perceptual task, tailored to its unique characteristics and its own training dataset. We propose a unified architectural framework for solving multiple different perceptual tasks leveraging CLIP as a prior. Our approach is based on recent cognitive findings which indicate that CLIP correlates well with human judgment. While CLIP was explicitly trained to align images and text, it implicitly also learned human inclinations. We attribute this to the inclusion of human-written image captions in CLIP's training data, which contain not only factual image descriptions, but inevitably also human sentiments and emotions. This makes CLIP a particularly strong prior for perceptual tasks. Accordingly, we suggest that minimal adaptation of CLIP suffices for solving a variety of perceptual tasks. Our simple unified framework employs a lightweight adaptation to fine-tune CLIP to each task, without requiring any task-specific architectural changes. We evaluate our approach on three tasks: (i) Image Memorability Prediction, (ii) No-reference Image Quality Assessment, and (iii) Visual Emotion Analysis. Our model achieves state-of-the-art results on all three tasks, while demonstrating improved generalization across different datasets.
ViSTA: Visual Storytelling using Multi-modal Adapters for Text-to-Image Diffusion Models
Jun 13, 2025Text-to-image diffusion models have achieved remarkable success, yet generating coherent image sequences for visual storytelling remains challenging. A key challenge is effectively leveraging all previous text-image pairs, referred to as history text-image pairs, which provide contextual information for maintaining consistency across frames. Existing auto-regressive methods condition on all past image-text pairs but require extensive training, while training-free subject-specific approaches ensure consistency but lack adaptability to narrative prompts. To address these limitations, we propose a multi-modal history adapter for text-to-image diffusion models, \textbf{ViSTA}. It consists of (1) a multi-modal history fusion module to extract relevant history features and (2) a history adapter to condition the generation on the extracted relevant features. We also introduce a salient history selection strategy during inference, where the most salient history text-image pair is selected, improving the quality of the conditioning. Furthermore, we propose to employ a Visual Question Answering-based metric TIFA to assess text-image alignment in visual storytelling, providing a more targeted and interpretable assessment of generated images. Evaluated on the StorySalon and FlintStonesSV dataset, our proposed ViSTA model is not only consistent across different frames, but also well-aligned with the narrative text descriptions.
IQPFR: An Image Quality Prior for Blind Face Restoration and Beyond
Mar 12, 2025Blind Face Restoration (BFR) addresses the challenge of reconstructing degraded low-quality (LQ) facial images into high-quality (HQ) outputs. Conventional approaches predominantly rely on learning feature representations from ground-truth (GT) data; however, inherent imperfections in GT datasets constrain restoration performance to the mean quality level of the training data, rather than attaining maximally attainable visual quality. To overcome this limitation, we propose a novel framework that incorporates an Image Quality Prior (IQP) derived from No-Reference Image Quality Assessment (NR-IQA) models to guide the restoration process toward optimal HQ reconstructions. Our methodology synergizes this IQP with a learned codebook prior through two critical innovations: (1) During codebook learning, we devise a dual-branch codebook architecture that disentangles feature extraction into universal structural components and HQ-specific attributes, ensuring comprehensive representation of both common and high-quality facial characteristics. (2) In the codebook lookup stage, we implement a quality-conditioned Transformer-based framework. NR-IQA-derived quality scores act as dynamic conditioning signals to steer restoration toward the highest feasible quality standard. This score-conditioned paradigm enables plug-and-play enhancement of existing BFR architectures without modifying the original structure. We also formulate a discrete representation-based quality optimization strategy that circumvents over-optimization artifacts prevalent in continuous latent space approaches. Extensive experiments demonstrate that our method outperforms state-of-the-art techniques across multiple benchmarks. Besides, our quality-conditioned framework demonstrates consistent performance improvements when integrated with prior BFR models. The code will be released.