 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage To Image Translation
Image-to-image translation is the process of converting an image from one domain to another using deep learning techniques.
Papers and Code
Noise Injection: Improving Out-of-Distribution Generalization for Limited Size Datasets
Nov 05, 2025



Deep learned (DL) models for image recognition have been shown to fail to generalize to data from different devices, populations, etc. COVID-19 detection from Chest X-rays (CXRs), in particular, has been shown to fail to generalize to out-of-distribution (OOD) data from new clinical sources not covered in the training set. This occurs because models learn to exploit shortcuts - source-specific artifacts that do not translate to new distributions - rather than reasonable biomarkers to maximize performance on in-distribution (ID) data. Rendering the models more robust to distribution shifts, our study investigates the use of fundamental noise injection techniques (Gaussian, Speckle, Poisson, and Salt and Pepper) during training. Our empirical results demonstrate that this technique can significantly reduce the performance gap between ID and OOD evaluation from 0.10-0.20 to 0.01-0.06, based on results averaged over ten random seeds across key metrics such as AUC, F1, accuracy, recall and specificity. Our source code is publicly available at https://github.com/Duongmai127/Noisy-ood
Clarification as Supervision: Reinforcement Learning for Vision-Language Interfaces
Sep 30, 2025



Recent text-only models demonstrate remarkable mathematical reasoning capabilities. Extending these to visual domains requires vision-language models to translate images into text descriptions. However, current models, trained to produce captions for human readers, often omit the precise details that reasoning systems require. This creates an interface mismatch: reasoners often fail not due to reasoning limitations but because they lack access to critical visual information. We propose Adaptive-Clarification Reinforcement Learning (AC-RL), which teaches vision models what information reasoners need through interaction. Our key insight is that clarification requests during training reveal information gaps; by penalizing success that requires clarification, we create pressure for comprehensive initial captions that enable the reasoner to solve the problem in a single pass. AC-RL improves average accuracy by 4.4 points over pretrained baselines across seven visual mathematical reasoning benchmarks, and analysis shows it would cut clarification requests by up to 39% if those were allowed. By treating clarification as a form of implicit supervision, AC-RL demonstrates that vision-language interfaces can be effectively learned through interaction alone, without requiring explicit annotations.
Quantifying the Climate Risk of Generative AI: Region-Aware Carbon Accounting with G-TRACE and the AI Sustainability Pyramid
Nov 06, 2025



Generative Artificial Intelligence (GenAI) represents a rapidly expanding digital infrastructure whose energy demand and associated CO2 emissions are emerging as a new category of climate risk. This study introduces G-TRACE (GenAI Transformative Carbon Estimator), a cross-modal, region-aware framework that quantifies training- and inference-related emissions across modalities and deployment geographies. Using real-world analytics and microscopic simulation, G-TRACE measures energy use and carbon intensity per output type (text, image, video) and reveals how decentralized inference amplifies small per-query energy costs into system-level impacts. Through the Ghibli-style image generation trend (2024-2025), we estimate 4,309 MWh of energy consumption and 2,068 tCO2 emissions, illustrating how viral participation inflates individual digital actions into tonne-scale consequences. Building on these findings, we propose the AI Sustainability Pyramid, a seven-level governance model linking carbon accounting metrics (L1-L7) with operational readiness, optimization, and stewardship. This framework translates quantitative emission metrics into actionable policy guidance for sustainable AI deployment. The study contributes to the quantitative assessment of emerging digital infrastructures as a novel category of climate risk, supporting adaptive governance for sustainable technology deployment. By situating GenAI within climate-risk frameworks, the work advances data-driven methods for aligning technological innovation with global decarbonization and resilience objectives.
Training-Free Synthetic Data Generation with Dual IP-Adapter Guidance
Sep 26, 2025

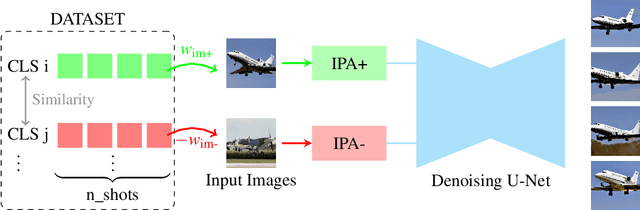

Few-shot image classification remains challenging due to the limited availability of labeled examples. Recent approaches have explored generating synthetic training data using text-to-image diffusion models, but often require extensive model fine-tuning or external information sources. We present a novel training-free approach, called DIPSY, that leverages IP-Adapter for image-to-image translation to generate highly discriminative synthetic images using only the available few-shot examples. DIPSY introduces three key innovations: (1) an extended classifier-free guidance scheme that enables independent control over positive and negative image conditioning; (2) a class similarity-based sampling strategy that identifies effective contrastive examples; and (3) a simple yet effective pipeline that requires no model fine-tuning or external captioning and filtering. Experiments across ten benchmark datasets demonstrate that our approach achieves state-of-the-art or comparable performance, while eliminating the need for generative model adaptation or reliance on external tools for caption generation and image filtering. Our results highlight the effectiveness of leveraging dual image prompting with positive-negative guidance for generating class-discriminative features, particularly for fine-grained classification tasks.
Transport Based Mean Flows for Generative Modeling
Sep 26, 2025



Flow-matching generative models have emerged as a powerful paradigm for continuous data generation, achieving state-of-the-art results across domains such as images, 3D shapes, and point clouds. Despite their success, these models suffer from slow inference due to the requirement of numerous sequential sampling steps. Recent work has sought to accelerate inference by reducing the number of sampling steps. In particular, Mean Flows offer a one-step generation approach that delivers substantial speedups while retaining strong generative performance. Yet, in many continuous domains, Mean Flows fail to faithfully approximate the behavior of the original multi-step flow-matching process. In this work, we address this limitation by incorporating optimal transport-based sampling strategies into the Mean Flow framework, enabling one-step generators that better preserve the fidelity and diversity of the original multi-step flow process. Experiments on controlled low-dimensional settings and on high-dimensional tasks such as image generation, image-to-image translation, and point cloud generation demonstrate that our approach achieves superior inference accuracy in one-step generative modeling.
Bidirectional Mammogram View Translation with Column-Aware and Implicit 3D Conditional Diffusion
Oct 06, 2025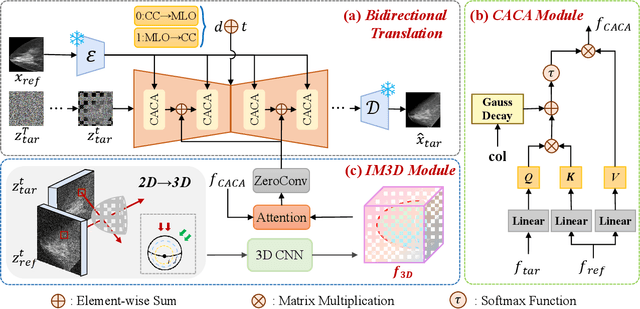
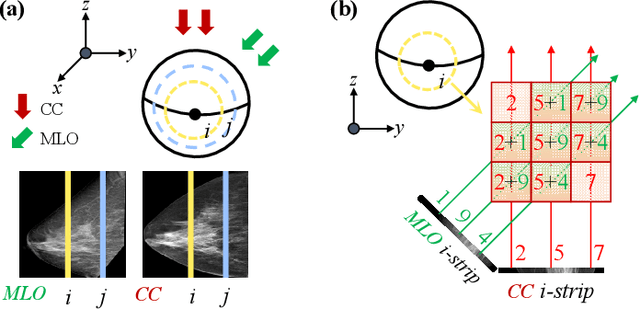
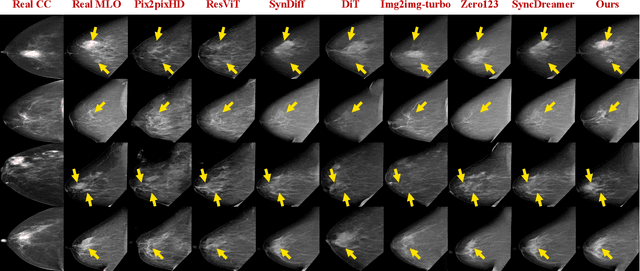
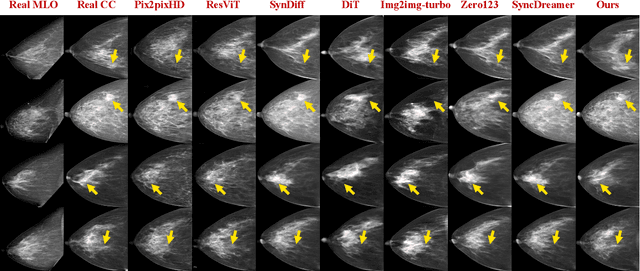
Dual-view mammography, including craniocaudal (CC) and mediolateral oblique (MLO) projections, offers complementary anatomical views crucial for breast cancer diagnosis. However, in real-world clinical workflows, one view may be missing, corrupted, or degraded due to acquisition errors or compression artifacts, limiting the effectiveness of downstream analysis. View-to-view translation can help recover missing views and improve lesion alignment. Unlike natural images, this task in mammography is highly challenging due to large non-rigid deformations and severe tissue overlap in X-ray projections, which obscure pixel-level correspondences. In this paper, we propose Column-Aware and Implicit 3D Diffusion (CA3D-Diff), a novel bidirectional mammogram view translation framework based on conditional diffusion model. To address cross-view structural misalignment, we first design a column-aware cross-attention mechanism that leverages the geometric property that anatomically corresponding regions tend to lie in similar column positions across views. A Gaussian-decayed bias is applied to emphasize local column-wise correlations while suppressing distant mismatches. Furthermore, we introduce an implicit 3D structure reconstruction module that back-projects noisy 2D latents into a coarse 3D feature volume based on breast-view projection geometry. The reconstructed 3D structure is refined and injected into the denoising UNet to guide cross-view generation with enhanced anatomical awareness. Extensive experiments demonstrate that CA3D-Diff achieves superior performance in bidirectional tasks, outperforming state-of-the-art methods in visual fidelity and structural consistency. Furthermore, the synthesized views effectively improve single-view malignancy classification in screening settings, demonstrating the practical value of our method in real-world diagnostics.
Comparative Analysis of GAN and Diffusion for MRI-to-CT translation
Sep 26, 2025



Computed tomography (CT) is essential for treatment and diagnostics; In case CT are missing or otherwise difficult to obtain, methods for generating synthetic CT (sCT) images from magnetic resonance imaging (MRI) images are sought after. Therefore, it is valuable to establish a reference for what strategies are most effective for MRI-to-CT translation. In this paper, we compare the performance of two frequently used architectures for MRI-to-CT translation: a conditional generative adversarial network (cGAN) and a conditional denoising diffusion probabilistic model (cDDPM). We chose well-established implementations to represent each architecture: Pix2Pix for cGAN, and Palette for cDDPM. We separate the classical 3D translation problem into a sequence of 2D translations on the transverse plane, to investigate the viability of a strategy that reduces the computational cost. We also investigate the impact of conditioning the generative process on a single MRI image/slice and on multiple MRI slices. The performance is assessed using a thorough evaluation protocol, including a novel slice-wise metric Similarity Of Slices (SIMOS), which measures the continuity between transverse slices when compiling the sCTs into 3D format. Our comparative analysis revealed that MRI-to-CT generative models benefit from multi-channel conditional input and using cDDPM as an architecture.
Time-Correlated Video Bridge Matching
Oct 14, 2025Diffusion models excel in noise-to-data generation tasks, providing a mapping from a Gaussian distribution to a more complex data distribution. However they struggle to model translations between complex distributions, limiting their effectiveness in data-to-data tasks. While Bridge Matching (BM) models address this by finding the translation between data distributions, their application to time-correlated data sequences remains unexplored. This is a critical limitation for video generation and manipulation tasks, where maintaining temporal coherence is particularly important. To address this gap, we propose Time-Correlated Video Bridge Matching (TCVBM), a framework that extends BM to time-correlated data sequences in the video domain. TCVBM explicitly models inter-sequence dependencies within the diffusion bridge, directly incorporating temporal correlations into the sampling process. We compare our approach to classical methods based on bridge matching and diffusion models for three video-related tasks: frame interpolation, image-to-video generation, and video super-resolution. TCVBM achieves superior performance across multiple quantitative metrics, demonstrating enhanced generation quality and reconstruction fidelity.
Continual Action Quality Assessment via Adaptive Manifold-Aligned Graph Regularization
Oct 08, 2025



Action Quality Assessment (AQA) quantifies human actions in videos, supporting applications in sports scoring, rehabilitation, and skill evaluation. A major challenge lies in the non-stationary nature of quality distributions in real-world scenarios, which limits the generalization ability of conventional methods. We introduce Continual AQA (CAQA), which equips AQA with Continual Learning (CL) capabilities to handle evolving distributions while mitigating catastrophic forgetting. Although parameter-efficient fine-tuning of pretrained models has shown promise in CL for image classification, we find it insufficient for CAQA. Our empirical and theoretical analyses reveal two insights: (i) Full-Parameter Fine-Tuning (FPFT) is necessary for effective representation learning; yet (ii) uncontrolled FPFT induces overfitting and feature manifold shift, thereby aggravating forgetting. To address this, we propose Adaptive Manifold-Aligned Graph Regularization (MAGR++), which couples backbone fine-tuning that stabilizes shallow layers while adapting deeper ones with a two-step feature rectification pipeline: a manifold projector to translate deviated historical features into the current representation space, and a graph regularizer to align local and global distributions. We construct four CAQA benchmarks from three datasets with tailored evaluation protocols and strong baselines, enabling systematic cross-dataset comparison. Extensive experiments show that MAGR++ achieves state-of-the-art performance, with average correlation gains of 3.6% offline and 12.2% online over the strongest baseline, confirming its robustness and effectiveness. Our code is available at https://github.com/ZhouKanglei/MAGRPP.
Graph2Eval: Automatic Multimodal Task Generation for Agents via Knowledge Graphs
Oct 01, 2025



As multimodal LLM-driven agents continue to advance in autonomy and generalization, evaluation based on static datasets can no longer adequately assess their true capabilities in dynamic environments and diverse tasks. Existing LLM-based synthetic data methods are largely designed for LLM training and evaluation, and thus cannot be directly applied to agent tasks that require tool use and interactive capabilities. While recent studies have explored automatic agent task generation with LLMs, most efforts remain limited to text or image analysis, without systematically modeling multi-step interactions in web environments. To address these challenges, we propose Graph2Eval, a knowledge graph-based framework that automatically generates both multimodal document comprehension tasks and web interaction tasks, enabling comprehensive evaluation of agents' reasoning, collaboration, and interactive capabilities. In our approach, knowledge graphs constructed from multi-source external data serve as the task space, where we translate semantic relations into structured multimodal tasks using subgraph sampling, task templates, and meta-paths. A multi-stage filtering pipeline based on node reachability, LLM scoring, and similarity analysis is applied to guarantee the quality and executability of the generated tasks. Furthermore, Graph2Eval supports end-to-end evaluation of multiple agent types (Single-Agent, Multi-Agent, Web Agent) and measures reasoning, collaboration, and interaction capabilities. We instantiate the framework with Graph2Eval-Bench, a curated dataset of 1,319 tasks spanning document comprehension and web interaction scenarios. Experiments show that Graph2Eval efficiently generates tasks that differentiate agent and model performance, revealing gaps in reasoning, collaboration, and web interaction across different settings and offering a new perspective for agent evaluation.