 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBriMA: Bridged Modality Adaptation for Multi-Modal Continual Action Quality Assessment
Feb 22, 2026Action Quality Assessment (AQA) aims to score how well an action is performed and is widely used in sports analysis, rehabilitation assessment, and human skill evaluation. Multi-modal AQA has recently achieved strong progress by leveraging complementary visual and kinematic cues, yet real-world deployments often suffer from non-stationary modality imbalance, where certain modalities become missing or intermittently available due to sensor failures or annotation gaps. Existing continual AQA methods overlook this issue and assume that all modalities remain complete and stable throughout training, which restricts their practicality. To address this challenge, we introduce Bridged Modality Adaptation (BriMA), an innovative approach to multi-modal continual AQA under modality-missing conditions. BriMA consists of a memory-guided bridging imputation module that reconstructs missing modalities using both task-agnostic and task-specific representations, and a modality-aware replay mechanism that prioritizes informative samples based on modality distortion and distribution drift. Experiments on three representative multi-modal AQA datasets (RG, Fis-V, and FS1000) show that BriMA consistently improves performance under different modality-missing conditions, achieving 6--8\% higher correlation and 12--15\% lower error on average. These results demonstrate a step toward robust multi-modal AQA systems under real-world deployment constraints.
Continual Action Quality Assessment via Adaptive Manifold-Aligned Graph Regularization
Oct 08, 2025



Action Quality Assessment (AQA) quantifies human actions in videos, supporting applications in sports scoring, rehabilitation, and skill evaluation. A major challenge lies in the non-stationary nature of quality distributions in real-world scenarios, which limits the generalization ability of conventional methods. We introduce Continual AQA (CAQA), which equips AQA with Continual Learning (CL) capabilities to handle evolving distributions while mitigating catastrophic forgetting. Although parameter-efficient fine-tuning of pretrained models has shown promise in CL for image classification, we find it insufficient for CAQA. Our empirical and theoretical analyses reveal two insights: (i) Full-Parameter Fine-Tuning (FPFT) is necessary for effective representation learning; yet (ii) uncontrolled FPFT induces overfitting and feature manifold shift, thereby aggravating forgetting. To address this, we propose Adaptive Manifold-Aligned Graph Regularization (MAGR++), which couples backbone fine-tuning that stabilizes shallow layers while adapting deeper ones with a two-step feature rectification pipeline: a manifold projector to translate deviated historical features into the current representation space, and a graph regularizer to align local and global distributions. We construct four CAQA benchmarks from three datasets with tailored evaluation protocols and strong baselines, enabling systematic cross-dataset comparison. Extensive experiments show that MAGR++ achieves state-of-the-art performance, with average correlation gains of 3.6% offline and 12.2% online over the strongest baseline, confirming its robustness and effectiveness. Our code is available at https://github.com/ZhouKanglei/MAGRPP.
PMT-IQA: Progressive Multi-task Learning for Blind Image Quality Assessment
Jan 03, 2023



Blind image quality assessment (BIQA) remains challenging due to the diversity of distortion and image content variation, which complicate the distortion patterns crossing different scales and aggravate the difficulty of the regression problem for BIQA. However, existing BIQA methods often fail to consider multi-scale distortion patterns and image content, and little research has been done on learning strategies to make the regression model produce better performance. In this paper, we propose a simple yet effective Progressive Multi-Task Image Quality Assessment (PMT-IQA) model, which contains a multi-scale feature extraction module (MS) and a progressive multi-task learning module (PMT), to help the model learn complex distortion patterns and better optimize the regression issue to align with the law of human learning process from easy to hard. To verify the effectiveness of the proposed PMT-IQA model, we conduct experiments on four widely used public datasets, and the experimental results indicate that the performance of PMT-IQA is superior to the comparison approaches, and both MS and PMT modules improve the model's performance.
Series Saliency: Temporal Interpretation for Multivariate Time Series Forecasting
Dec 16, 2020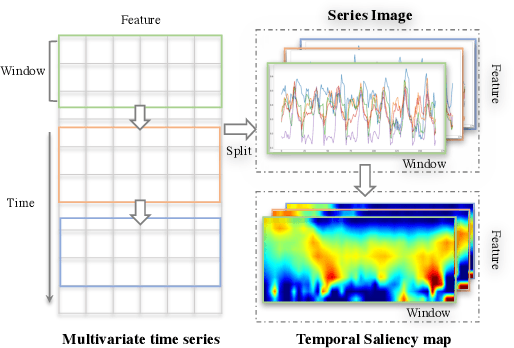
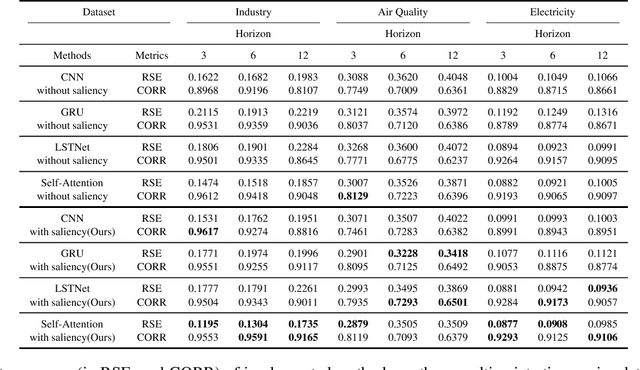
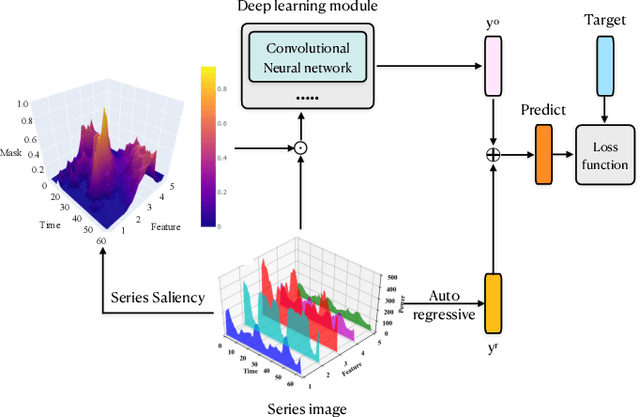

Time series forecasting is an important yet challenging task. Though deep learning methods have recently been developed to give superior forecasting results, it is crucial to improve the interpretability of time series models. Previous interpretation methods, including the methods for general neural networks and attention-based methods, mainly consider the interpretation in the feature dimension while ignoring the crucial temporal dimension. In this paper, we present the series saliency framework for temporal interpretation for multivariate time series forecasting, which considers the forecasting interpretation in both feature and temporal dimensions. By extracting the "series images" from the sliding windows of the time series, we apply the saliency map segmentation following the smallest destroying region principle. The series saliency framework can be employed to any well-defined deep learning models and works as a data augmentation to get more accurate forecasts. Experimental results on several real datasets demonstrate that our framework generates temporal interpretations for the time series forecasting task while produces accurate time series forecast.