 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Synthetic Data Generation with Dual IP-Adapter Guidance
Sep 26, 2025

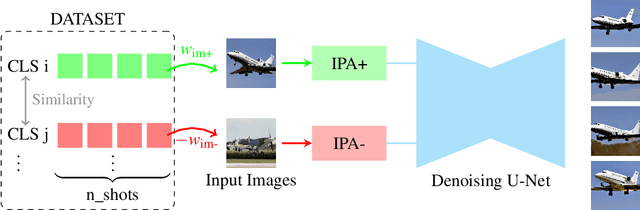

Few-shot image classification remains challenging due to the limited availability of labeled examples. Recent approaches have explored generating synthetic training data using text-to-image diffusion models, but often require extensive model fine-tuning or external information sources. We present a novel training-free approach, called DIPSY, that leverages IP-Adapter for image-to-image translation to generate highly discriminative synthetic images using only the available few-shot examples. DIPSY introduces three key innovations: (1) an extended classifier-free guidance scheme that enables independent control over positive and negative image conditioning; (2) a class similarity-based sampling strategy that identifies effective contrastive examples; and (3) a simple yet effective pipeline that requires no model fine-tuning or external captioning and filtering. Experiments across ten benchmark datasets demonstrate that our approach achieves state-of-the-art or comparable performance, while eliminating the need for generative model adaptation or reliance on external tools for caption generation and image filtering. Our results highlight the effectiveness of leveraging dual image prompting with positive-negative guidance for generating class-discriminative features, particularly for fine-grained classification tasks.
U-Sketch: An Efficient Approach for Sketch to Image Diffusion Models
Mar 27, 2024



Diffusion models have demonstrated remarkable performance in text-to-image synthesis, producing realistic and high resolution images that faithfully adhere to the corresponding text-prompts. Despite their great success, they still fall behind in sketch-to-image synthesis tasks, where in addition to text-prompts, the spatial layout of the generated images has to closely follow the outlines of certain reference sketches. Employing an MLP latent edge predictor to guide the spatial layout of the synthesized image by predicting edge maps at each denoising step has been recently proposed. Despite yielding promising results, the pixel-wise operation of the MLP does not take into account the spatial layout as a whole, and demands numerous denoising iterations to produce satisfactory images, leading to time inefficiency. To this end, we introduce U-Sketch, a framework featuring a U-Net type latent edge predictor, which is capable of efficiently capturing both local and global features, as well as spatial correlations between pixels. Moreover, we propose the addition of a sketch simplification network that offers the user the choice of preprocessing and simplifying input sketches for enhanced outputs. The experimental results, corroborated by user feedback, demonstrate that our proposed U-Net latent edge predictor leads to more realistic results, that are better aligned with the spatial outlines of the reference sketches, while drastically reducing the number of required denoising steps and, consequently, the overall execution time.
Mitigating Exposure Bias in Discriminator Guided Diffusion Models
Nov 18, 2023Diffusion Models have demonstrated remarkable performance in image generation. However, their demanding computational requirements for training have prompted ongoing efforts to enhance the quality of generated images through modifications in the sampling process. A recent approach, known as Discriminator Guidance, seeks to bridge the gap between the model score and the data score by incorporating an auxiliary term, derived from a discriminator network. We show that despite significantly improving sample quality, this technique has not resolved the persistent issue of Exposure Bias and we propose SEDM-G++, which incorporates a modified sampling approach, combining Discriminator Guidance and Epsilon Scaling. Our proposed approach outperforms the current state-of-the-art, by achieving an FID score of 1.73 on the unconditional CIFAR-10 dataset.