 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky 5.0: A Family of Foundation Models for Image and Video Generation
Nov 19, 2025



This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.
Time-Correlated Video Bridge Matching
Oct 14, 2025Diffusion models excel in noise-to-data generation tasks, providing a mapping from a Gaussian distribution to a more complex data distribution. However they struggle to model translations between complex distributions, limiting their effectiveness in data-to-data tasks. While Bridge Matching (BM) models address this by finding the translation between data distributions, their application to time-correlated data sequences remains unexplored. This is a critical limitation for video generation and manipulation tasks, where maintaining temporal coherence is particularly important. To address this gap, we propose Time-Correlated Video Bridge Matching (TCVBM), a framework that extends BM to time-correlated data sequences in the video domain. TCVBM explicitly models inter-sequence dependencies within the diffusion bridge, directly incorporating temporal correlations into the sampling process. We compare our approach to classical methods based on bridge matching and diffusion models for three video-related tasks: frame interpolation, image-to-video generation, and video super-resolution. TCVBM achieves superior performance across multiple quantitative metrics, demonstrating enhanced generation quality and reconstruction fidelity.
$ abla$NABLA: Neighborhood Adaptive Block-Level Attention
Jul 17, 2025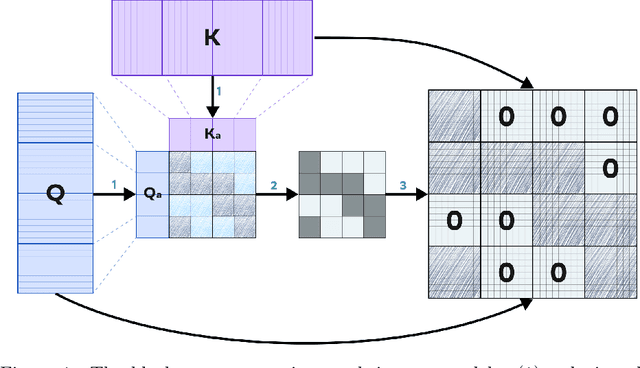
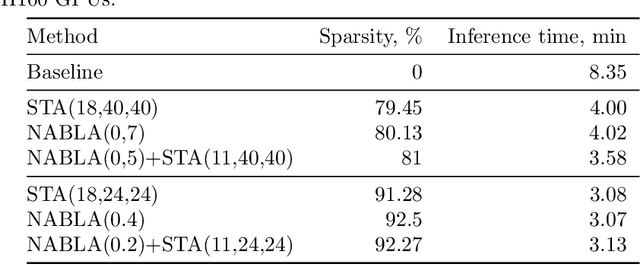
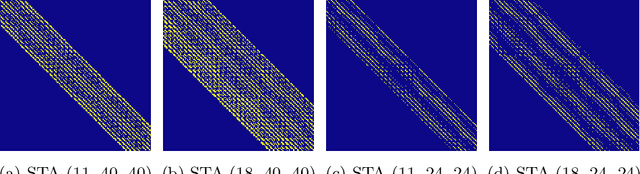
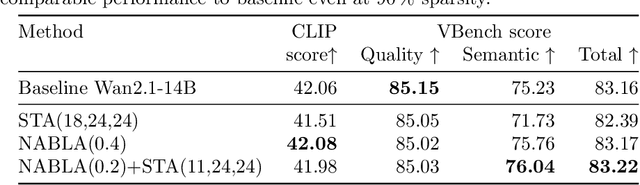
Recent progress in transformer-based architectures has demonstrated remarkable success in video generation tasks. However, the quadratic complexity of full attention mechanisms remains a critical bottleneck, particularly for high-resolution and long-duration video sequences. In this paper, we propose NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality. Our method does not require custom low-level operator design and can be seamlessly integrated with PyTorch's Flex Attention operator. Experiments demonstrate that NABLA achieves up to 2.7x faster training and inference compared to baseline almost without compromising quantitative metrics (CLIP score, VBench score, human evaluation score) and visual quality drop. The code and model weights are available here: https://github.com/gen-ai-team/Wan2.1-NABLA
VIVAT: Virtuous Improving VAE Training through Artifact Mitigation
Jun 09, 2025



Variational Autoencoders (VAEs) remain a cornerstone of generative computer vision, yet their training is often plagued by artifacts that degrade reconstruction and generation quality. This paper introduces VIVAT, a systematic approach to mitigating common artifacts in KL-VAE training without requiring radical architectural changes. We present a detailed taxonomy of five prevalent artifacts - color shift, grid patterns, blur, corner and droplet artifacts - and analyze their root causes. Through straightforward modifications, including adjustments to loss weights, padding strategies, and the integration of Spatially Conditional Normalization, we demonstrate significant improvements in VAE performance. Our method achieves state-of-the-art results in image reconstruction metrics (PSNR and SSIM) across multiple benchmarks and enhances text-to-image generation quality, as evidenced by superior CLIP scores. By preserving the simplicity of the KL-VAE framework while addressing its practical challenges, VIVAT offers actionable insights for researchers and practitioners aiming to optimize VAE training.
Universal representations for financial transactional data: embracing local, global, and external contexts
Apr 02, 2024



Effective processing of financial transactions is essential for banking data analysis. However, in this domain, most methods focus on specialized solutions to stand-alone problems instead of constructing universal representations suitable for many problems. We present a representation learning framework that addresses diverse business challenges. We also suggest novel generative models that account for data specifics, and a way to integrate external information into a client's representation, leveraging insights from other customers' actions. Finally, we offer a benchmark, describing representation quality globally, concerning the entire transaction history; locally, reflecting the client's current state; and dynamically, capturing representation evolution over time. Our generative approach demonstrates superior performance in local tasks, with an increase in ROC-AUC of up to 14\% for the next MCC prediction task and up to 46\% for downstream tasks from existing contrastive baselines. Incorporating external information improves the scores by an additional 20\%.