 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
Apr 07, 2026This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. The code is available at https://github.com/davidpicard/pom.
One View Is Enough! Monocular Training for In-the-Wild Novel View Generation
Mar 24, 2026Monocular novel-view synthesis has long required multi-view image pairs for supervision, limiting training data scale and diversity. We argue it is not necessary: one view is enough. We present OVIE, trained entirely on unpaired internet images. We leverage a monocular depth estimator as a geometric scaffold at training time: we lift a source image into 3D, apply a sampled camera transformation, and project to obtain a pseudo-target view. To handle disocclusions, we introduce a masked training formulation that restricts geometric, perceptual, and textural losses to valid regions, enabling training on 30 million uncurated images. At inference, OVIE is geometry-free, requiring no depth estimator or 3D representation. Trained exclusively on in-the-wild images, OVIE outperforms prior methods in a zero-shot setting, while being 600x faster than the second-best baseline. Code and models are publicly available at https://github.com/AdrienRR/ovie.
MIRO: MultI-Reward cOnditioned pretraining improves T2I quality and efficiency
Oct 29, 2025Current text-to-image generative models are trained on large uncurated datasets to enable diverse generation capabilities. However, this does not align well with user preferences. Recently, reward models have been specifically designed to perform post-hoc selection of generated images and align them to a reward, typically user preference. This discarding of informative data together with the optimizing for a single reward tend to harm diversity, semantic fidelity and efficiency. Instead of this post-processing, we propose to condition the model on multiple reward models during training to let the model learn user preferences directly. We show that this not only dramatically improves the visual quality of the generated images but it also significantly speeds up the training. Our proposed method, called MIRO, achieves state-of-the-art performances on the GenEval compositional benchmark and user-preference scores (PickAScore, ImageReward, HPSv2).
Training-Free Synthetic Data Generation with Dual IP-Adapter Guidance
Sep 26, 2025

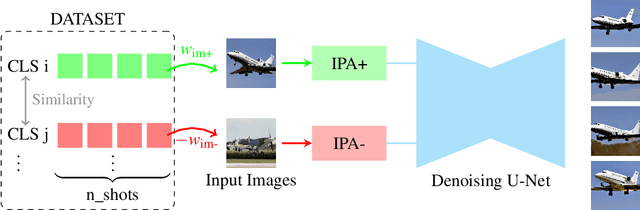

Few-shot image classification remains challenging due to the limited availability of labeled examples. Recent approaches have explored generating synthetic training data using text-to-image diffusion models, but often require extensive model fine-tuning or external information sources. We present a novel training-free approach, called DIPSY, that leverages IP-Adapter for image-to-image translation to generate highly discriminative synthetic images using only the available few-shot examples. DIPSY introduces three key innovations: (1) an extended classifier-free guidance scheme that enables independent control over positive and negative image conditioning; (2) a class similarity-based sampling strategy that identifies effective contrastive examples; and (3) a simple yet effective pipeline that requires no model fine-tuning or external captioning and filtering. Experiments across ten benchmark datasets demonstrate that our approach achieves state-of-the-art or comparable performance, while eliminating the need for generative model adaptation or reliance on external tools for caption generation and image filtering. Our results highlight the effectiveness of leveraging dual image prompting with positive-negative guidance for generating class-discriminative features, particularly for fine-grained classification tasks.
Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation
Dec 09, 2024



Global visual geolocation predicts where an image was captured on Earth. Since images vary in how precisely they can be localized, this task inherently involves a significant degree of ambiguity. However, existing approaches are deterministic and overlook this aspect. In this paper, we aim to close the gap between traditional geolocalization and modern generative methods. We propose the first generative geolocation approach based on diffusion and Riemannian flow matching, where the denoising process operates directly on the Earth's surface. Our model achieves state-of-the-art performance on three visual geolocation benchmarks: OpenStreetView-5M, YFCC-100M, and iNat21. In addition, we introduce the task of probabilistic visual geolocation, where the model predicts a probability distribution over all possible locations instead of a single point. We introduce new metrics and baselines for this task, demonstrating the advantages of our diffusion-based approach. Codes and models will be made available.
PoM: Efficient Image and Video Generation with the Polynomial Mixer
Nov 19, 2024



Diffusion models based on Multi-Head Attention (MHA) have become ubiquitous to generate high quality images and videos. However, encoding an image or a video as a sequence of patches results in costly attention patterns, as the requirements both in terms of memory and compute grow quadratically. To alleviate this problem, we propose a drop-in replacement for MHA called the Polynomial Mixer (PoM) that has the benefit of encoding the entire sequence into an explicit state. PoM has a linear complexity with respect to the number of tokens. This explicit state also allows us to generate frames in a sequential fashion, minimizing memory and compute requirement, while still being able to train in parallel. We show the Polynomial Mixer is a universal sequence-to-sequence approximator, just like regular MHA. We adapt several Diffusion Transformers (DiT) for generating images and videos with PoM replacing MHA, and we obtain high quality samples while using less computational resources. The code is available at https://github.com/davidpicard/HoMM.
E.T. the Exceptional Trajectories: Text-to-camera-trajectory generation with character awareness
Jul 01, 2024



Stories and emotions in movies emerge through the effect of well-thought-out directing decisions, in particular camera placement and movement over time. Crafting compelling camera trajectories remains a complex iterative process, even for skilful artists. To tackle this, in this paper, we propose a dataset called the Exceptional Trajectories (E.T.) with camera trajectories along with character information and textual captions encompassing descriptions of both camera and character. To our knowledge, this is the first dataset of its kind. To show the potential applications of the E.T. dataset, we propose a diffusion-based approach, named DIRECTOR, which generates complex camera trajectories from textual captions that describe the relation and synchronisation between the camera and characters. To ensure robust and accurate evaluations, we train on the E.T. dataset CLaTr, a Contrastive Language-Trajectory embedding for evaluation metrics. We posit that our proposed dataset and method significantly advance the democratization of cinematography, making it more accessible to common users.
Don't drop your samples! Coherence-aware training benefits Conditional diffusion
May 30, 2024



Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. We show that CAD is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging coherence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low coherence have been discarded.
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Apr 29, 2024



Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
Analysis of Classifier-Free Guidance Weight Schedulers
Apr 19, 2024Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances, requiring merely a single line of code. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks.