 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Compression
Video compression is a process of reducing the size of an image or video file by exploiting spatial and temporal redundancies within an image or video frame and across multiple video frames. The ultimate goal of a successful Video Compression system is to reduce data volume while retaining the perceptual quality of the decompressed data.
Papers and Code
TerraCodec: Compressing Earth Observations
Oct 14, 2025



Earth observation (EO) satellites produce massive streams of multispectral image time series, posing pressing challenges for storage and transmission. Yet, learned EO compression remains fragmented, lacking publicly available pretrained models and misaligned with advances in compression for natural imagery. Image codecs overlook temporal redundancy, while video codecs rely on motion priors that fail to capture the radiometric evolution of largely static scenes. We introduce TerraCodec (TEC), a family of learned codecs tailored to EO. TEC includes efficient image-based variants adapted to multispectral inputs, as well as a Temporal Transformer model (TEC-TT) that leverages dependencies across time. To overcome the fixed-rate setting of today's neural codecs, we present Latent Repacking, a novel method for training flexible-rate transformer models that operate on varying rate-distortion settings. Trained on Sentinel-2 data, TerraCodec outperforms classical codecs, achieving 3-10x stronger compression at equivalent image quality. Beyond compression, TEC-TT enables zero-shot cloud inpainting, surpassing state-of-the-art methods on the AllClear benchmark. Our results establish bespoke, learned compression algorithms as a promising direction for Earth observation. Code and model weights will be released under a permissive license.
VideoNSA: Native Sparse Attention Scales Video Understanding
Oct 02, 2025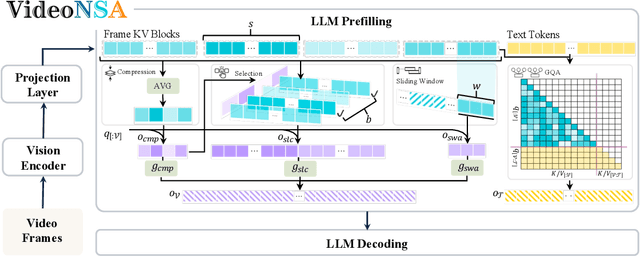
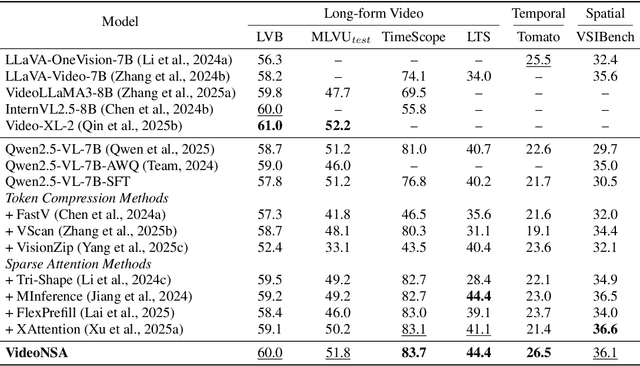
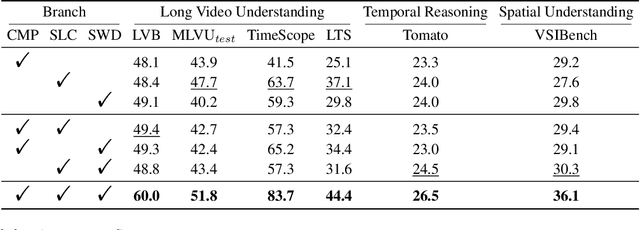
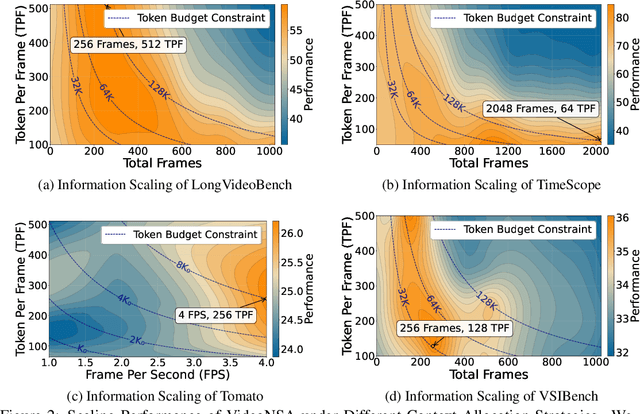
Video understanding in multimodal language models remains limited by context length: models often miss key transition frames and struggle to maintain coherence across long time scales. To address this, we adapt Native Sparse Attention (NSA) to video-language models. Our method, VideoNSA, adapts Qwen2.5-VL through end-to-end training on a 216K video instruction dataset. We employ a hardware-aware hybrid approach to attention, preserving dense attention for text, while employing NSA for video. Compared to token-compression and training-free sparse baselines, VideoNSA achieves improved performance on long-video understanding, temporal reasoning, and spatial benchmarks. Further ablation analysis reveals four key findings: (1) reliable scaling to 128K tokens; (2) an optimal global-local attention allocation at a fixed budget; (3) task-dependent branch usage patterns; and (4) the learnable combined sparse attention help induce dynamic attention sinks.
Neural Video Compression with In-Loop Contextual Filtering and Out-of-Loop Reconstruction Enhancement
Sep 04, 2025This paper explores the application of enhancement filtering techniques in neural video compression. Specifically, we categorize these techniques into in-loop contextual filtering and out-of-loop reconstruction enhancement based on whether the enhanced representation affects the subsequent coding loop. In-loop contextual filtering refines the temporal context by mitigating error propagation during frame-by-frame encoding. However, its influence on both the current and subsequent frames poses challenges in adaptively applying filtering throughout the sequence. To address this, we introduce an adaptive coding decision strategy that dynamically determines filtering application during encoding. Additionally, out-of-loop reconstruction enhancement is employed to refine the quality of reconstructed frames, providing a simple yet effective improvement in coding efficiency. To the best of our knowledge, this work presents the first systematic study of enhancement filtering in the context of conditional-based neural video compression. Extensive experiments demonstrate a 7.71% reduction in bit rate compared to state-of-the-art neural video codecs, validating the effectiveness of the proposed approach.
Generative World Modelling for Humanoids: 1X World Model Challenge Technical Report
Oct 08, 2025



World models are a powerful paradigm in AI and robotics, enabling agents to reason about the future by predicting visual observations or compact latent states. The 1X World Model Challenge introduces an open-source benchmark of real-world humanoid interaction, with two complementary tracks: sampling, focused on forecasting future image frames, and compression, focused on predicting future discrete latent codes. For the sampling track, we adapt the video generation foundation model Wan-2.2 TI2V-5B to video-state-conditioned future frame prediction. We condition the video generation on robot states using AdaLN-Zero, and further post-train the model using LoRA. For the compression track, we train a Spatio-Temporal Transformer model from scratch. Our models achieve 23.0 dB PSNR in the sampling task and a Top-500 CE of 6.6386 in the compression task, securing 1st place in both challenges.
Sparse Transformer for Ultra-sparse Sampled Video Compressive Sensing
Sep 10, 2025Digital cameras consume ~0.1 microjoule per pixel to capture and encode video, resulting in a power usage of ~20W for a 4K sensor operating at 30 fps. Imagining gigapixel cameras operating at 100-1000 fps, the current processing model is unsustainable. To address this, physical layer compressive measurement has been proposed to reduce power consumption per pixel by 10-100X. Video Snapshot Compressive Imaging (SCI) introduces high frequency modulation in the optical sensor layer to increase effective frame rate. A commonly used sampling strategy of video SCI is Random Sampling (RS) where each mask element value is randomly set to be 0 or 1. Similarly, image inpainting (I2P) has demonstrated that images can be recovered from a fraction of the image pixels. Inspired by I2P, we propose Ultra-Sparse Sampling (USS) regime, where at each spatial location, only one sub-frame is set to 1 and all others are set to 0. We then build a Digital Micro-mirror Device (DMD) encoding system to verify the effectiveness of our USS strategy. Ideally, we can decompose the USS measurement into sub-measurements for which we can utilize I2P algorithms to recover high-speed frames. However, due to the mismatch between the DMD and CCD, the USS measurement cannot be perfectly decomposed. To this end, we propose BSTFormer, a sparse TransFormer that utilizes local Block attention, global Sparse attention, and global Temporal attention to exploit the sparsity of the USS measurement. Extensive results on both simulated and real-world data show that our method significantly outperforms all previous state-of-the-art algorithms. Additionally, an essential advantage of the USS strategy is its higher dynamic range than that of the RS strategy. Finally, from the application perspective, the USS strategy is a good choice to implement a complete video SCI system on chip due to its fixed exposure time.
Learned Rate Control for Frame-Level Adaptive Neural Video Compression via Dynamic Neural Network
Aug 28, 2025Neural Video Compression (NVC) has achieved remarkable performance in recent years. However, precise rate control remains a challenge due to the inherent limitations of learning-based codecs. To solve this issue, we propose a dynamic video compression framework designed for variable bitrate scenarios. First, to achieve variable bitrate implementation, we propose the Dynamic-Route Autoencoder with variable coding routes, each occupying partial computational complexity of the whole network and navigating to a distinct RD trade-off. Second, to approach the target bitrate, the Rate Control Agent estimates the bitrate of each route and adjusts the coding route of DRA at run time. To encompass a broad spectrum of variable bitrates while preserving overall RD performance, we employ the Joint-Routes Optimization strategy, achieving collaborative training of various routes. Extensive experiments on the HEVC and UVG datasets show that the proposed method achieves an average BD-Rate reduction of 14.8% and BD-PSNR gain of 0.47dB over state-of-the-art methods while maintaining an average bitrate error of 1.66%, achieving Rate-Distortion-Complexity Optimization (RDCO) for various bitrate and bitrate-constrained applications. Our code is available at https://git.openi.org.cn/OpenAICoding/DynamicDVC.
An Empirical Study of Reducing AV1 Decoder Complexity and Energy Consumption via Encoder Parameter Tuning
Oct 14, 2025The widespread adoption of advanced video codecs such as AV1 is often hindered by their high decoding complexity, posing a challenge for battery-constrained devices. While encoders can be configured to produce bitstreams that are decoder-friendly, estimating the decoding complexity and energy overhead for a given video is non-trivial. In this study, we systematically analyse the impact of disabling various coding tools and adjusting coding parameters in two AV1 encoders, libaom-av1 and SVT-AV1. Using system-level energy measurement tools like RAPL (Running Average Power Limit), Intel SoC Watch (integrated with VTune profiler), we quantify the resulting trade-offs between decoding complexity, energy consumption, and compression efficiency for decoding a bitstream. Our results demonstrate that specific encoder configurations can substantially reduce decoding complexity with minimal perceptual quality degradation. For libaom-av1, disabling CDEF, an in-loop filter gives us a mean reduction in decoding cycles by 10%. For SVT-AV1, using the in-built, fast-decode=2 preset achieves a more substantial 24% reduction in decoding cycles. These findings provide strategies for content providers to lower the energy footprint of AV1 video streaming.
ContextVLA: Vision-Language-Action Model with Amortized Multi-Frame Context
Oct 05, 2025Leveraging temporal context is crucial for success in partially observable robotic tasks. However, prior work in behavior cloning has demonstrated inconsistent performance gains when using multi-frame observations. In this paper, we introduce ContextVLA, a policy model that robustly improves robotic task performance by effectively leveraging multi-frame observations. Our approach is motivated by the key observation that Vision-Language-Action models (VLA), i.e., policy models built upon a Vision-Language Model (VLM), more effectively utilize multi-frame observations for action generation. This suggests that VLMs' inherent temporal understanding capability enables them to extract more meaningful context from multi-frame observations. However, the high dimensionality of video inputs introduces significant computational overhead, making VLA training and inference inefficient. To address this, ContextVLA compresses past observations into a single context token, allowing the policy to efficiently leverage temporal context for action generation. Our experiments show that ContextVLA consistently improves over single-frame VLAs and achieves the benefits of full multi-frame training but with reduced training and inference times.
DiffVC-OSD: One-Step Diffusion-based Perceptual Neural Video Compression Framework
Aug 11, 2025In this work, we first propose DiffVC-OSD, a One-Step Diffusion-based Perceptual Neural Video Compression framework. Unlike conventional multi-step diffusion-based methods, DiffVC-OSD feeds the reconstructed latent representation directly into a One-Step Diffusion Model, enhancing perceptual quality through a single diffusion step guided by both temporal context and the latent itself. To better leverage temporal dependencies, we design a Temporal Context Adapter that encodes conditional inputs into multi-level features, offering more fine-grained guidance for the Denoising Unet. Additionally, we employ an End-to-End Finetuning strategy to improve overall compression performance. Extensive experiments demonstrate that DiffVC-OSD achieves state-of-the-art perceptual compression performance, offers about 20$\times$ faster decoding and a 86.92\% bitrate reduction compared to the corresponding multi-step diffusion-based variant.
Lossless 4:2:0 Screen Content Coding Using Luma-Guided Soft Context Formation
Aug 26, 2025The soft context formation coder is a pixel-wise state-of-the-art lossless screen content coder using pattern matching and color palette coding in combination with arithmetic coding. It achieves excellent compression performance on screen content images in RGB 4:4:4 format with few distinct colors. In contrast to many other lossless compression methods, it codes entire color pixels at once, i.e., all color components of one pixel are coded together. Consequently, it does not natively support image formats with downsampled chroma, such as YCbCr 4:2:0, which is an often used chroma format in video compression. In this paper, we extend the soft context formation coding capabilities to 4:2:0 image compression, by successively coding Y and CbCr planes based on an analysis of normalized mutual information between image planes. Additionally, we propose an enhancement to the chroma prediction based on the luminance plane. Furthermore, we propose to transmit side-information about occurring luma-chroma combinations to improve chroma probability distribution modelling. Averaged over a large screen content image dataset, our proposed method outperforms HEVC-SCC, with HEVC-SCC needing 5.66% more bitrate compared to our method.