 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3d Human Pose Estimation
3D Human Pose Estimation is a computer vision task that involves estimating the 3D positions and orientations of body joints and bones from 2D images or videos. The goal is to reconstruct the 3D pose of a person in real time, which can be used in a variety of applications, such as virtual reality, human-computer interaction, and motion analysis.
Papers and Code
STARC: See-Through-Wall Augmented Reality Framework for Human-Robot Collaboration in Emergency Response
Sep 19, 2025In emergency response missions, first responders must navigate cluttered indoor environments where occlusions block direct line-of-sight, concealing both life-threatening hazards and victims in need of rescue. We present STARC, a see-through AR framework for human-robot collaboration that fuses mobile-robot mapping with responder-mounted LiDAR sensing. A ground robot running LiDAR-inertial odometry performs large-area exploration and 3D human detection, while helmet- or handheld-mounted LiDAR on the responder is registered to the robot's global map via relative pose estimation. This cross-LiDAR alignment enables consistent first-person projection of detected humans and their point clouds - rendered in AR with low latency - into the responder's view. By providing real-time visualization of hidden occupants and hazards, STARC enhances situational awareness and reduces operator risk. Experiments in simulation, lab setups, and tactical field trials confirm robust pose alignment, reliable detections, and stable overlays, underscoring the potential of our system for fire-fighting, disaster relief, and other safety-critical operations. Code and design will be open-sourced upon acceptance.
Systematic Comparison of Projection Methods for Monocular 3D Human Pose Estimation on Fisheye Images
Jun 24, 2025Fisheye cameras offer robots the ability to capture human movements across a wider field of view (FOV) than standard pinhole cameras, making them particularly useful for applications in human-robot interaction and automotive contexts. However, accurately detecting human poses in fisheye images is challenging due to the curved distortions inherent to fisheye optics. While various methods for undistorting fisheye images have been proposed, their effectiveness and limitations for poses that cover a wide FOV has not been systematically evaluated in the context of absolute human pose estimation from monocular fisheye images. To address this gap, we evaluate the impact of pinhole, equidistant and double sphere camera models, as well as cylindrical projection methods, on 3D human pose estimation accuracy. We find that in close-up scenarios, pinhole projection is inadequate, and the optimal projection method varies with the FOV covered by the human pose. The usage of advanced fisheye models like the double sphere model significantly enhances 3D human pose estimation accuracy. We propose a heuristic for selecting the appropriate projection model based on the detection bounding box to enhance prediction quality. Additionally, we introduce and evaluate on our novel dataset FISHnCHIPS, which features 3D human skeleton annotations in fisheye images, including images from unconventional angles, such as extreme close-ups, ground-mounted cameras, and wide-FOV poses, available at: https://www.vision.rwth-aachen.de/fishnchips
Affordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025

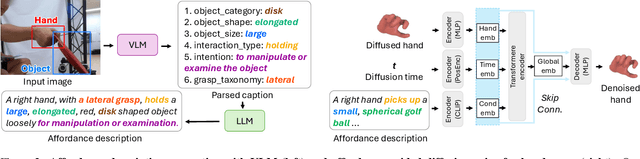

How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.
PoseGRAF: Geometric-Reinforced Adaptive Fusion for Monocular 3D Human Pose Estimation
Jun 17, 2025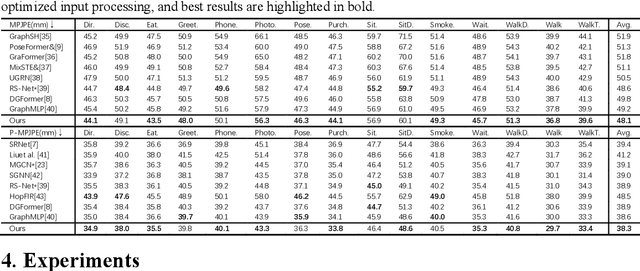
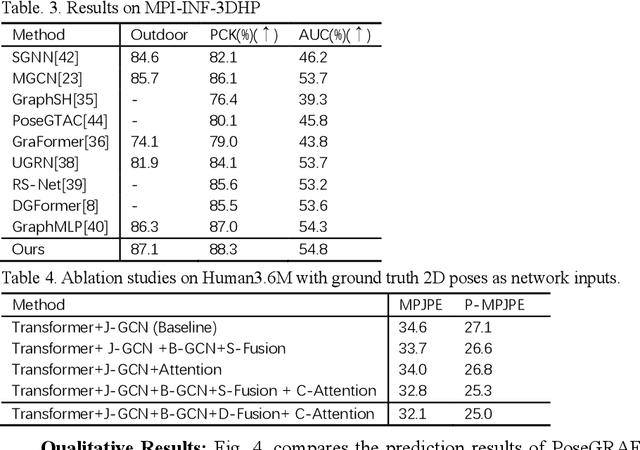
Existing monocular 3D pose estimation methods primarily rely on joint positional features, while overlooking intrinsic directional and angular correlations within the skeleton. As a result, they often produce implausible poses under joint occlusions or rapid motion changes. To address these challenges, we propose the PoseGRAF framework. We first construct a dual graph convolutional structure that separately processes joint and bone graphs, effectively capturing their local dependencies. A Cross-Attention module is then introduced to model interdependencies between bone directions and joint features. Building upon this, a dynamic fusion module is designed to adaptively integrate both feature types by leveraging the relational dependencies between joints and bones. An improved Transformer encoder is further incorporated in a residual manner to generate the final output. Experimental results on the Human3.6M and MPI-INF-3DHP datasets show that our method exceeds state-of-the-art approaches. Additional evaluations on in-the-wild videos further validate its generalizability. The code is publicly available at https://github.com/iCityLab/PoseGRAF.
Spectral Compression Transformer with Line Pose Graph for Monocular 3D Human Pose Estimation
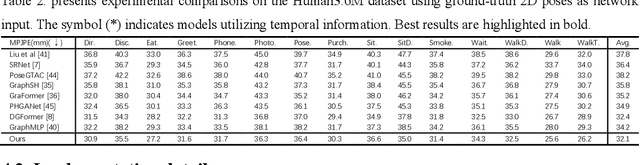
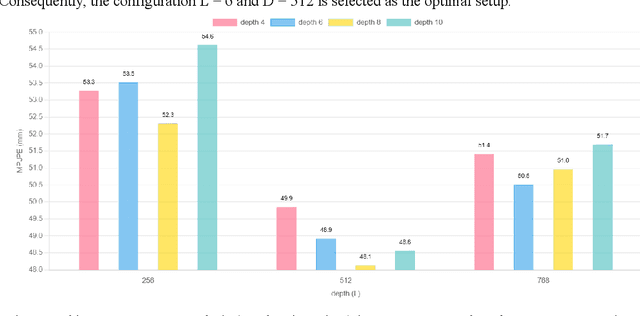
May 27, 2025Transformer-based 3D human pose estimation methods suffer from high computational costs due to the quadratic complexity of self-attention with respect to sequence length. Additionally, pose sequences often contain significant redundancy between frames. However, recent methods typically fail to improve model capacity while effectively eliminating sequence redundancy. In this work, we introduce the Spectral Compression Transformer (SCT) to reduce sequence length and accelerate computation. The SCT encoder treats hidden features between blocks as Temporal Feature Signals (TFS) and applies the Discrete Cosine Transform, a Fourier transform-based technique, to determine the spectral components to be retained. By filtering out certain high-frequency noise components, SCT compresses the sequence length and reduces redundancy. To further enrich the input sequence with prior structural information, we propose the Line Pose Graph (LPG) based on line graph theory. The LPG generates skeletal position information that complements the input 2D joint positions, thereby improving the model's performance. Finally, we design a dual-stream network architecture to effectively model spatial joint relationships and the compressed motion trajectory within the pose sequence. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that our model achieves state-of-the-art performance with improved computational efficiency. For example, on the Human3.6M dataset, our method achieves an MPJPE of 37.7mm while maintaining a low computational cost. Furthermore, we perform ablation studies on each module to assess its effectiveness. The code and models will be released.
IDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.
HDiffTG: A Lightweight Hybrid Diffusion-Transformer-GCN Architecture for 3D Human Pose Estimation
May 07, 2025We propose HDiffTG, a novel 3D Human Pose Estimation (3DHPE) method that integrates Transformer, Graph Convolutional Network (GCN), and diffusion model into a unified framework. HDiffTG leverages the strengths of these techniques to significantly improve pose estimation accuracy and robustness while maintaining a lightweight design. The Transformer captures global spatiotemporal dependencies, the GCN models local skeletal structures, and the diffusion model provides step-by-step optimization for fine-tuning, achieving a complementary balance between global and local features. This integration enhances the model's ability to handle pose estimation under occlusions and in complex scenarios. Furthermore, we introduce lightweight optimizations to the integrated model and refine the objective function design to reduce computational overhead without compromising performance. Evaluation results on the Human3.6M and MPI-INF-3DHP datasets demonstrate that HDiffTG achieves state-of-the-art (SOTA) performance on the MPI-INF-3DHP dataset while excelling in both accuracy and computational efficiency. Additionally, the model exhibits exceptional robustness in noisy and occluded environments. Source codes and models are available at https://github.com/CirceJie/HDiffTG
PoseBench3D: A Cross-Dataset Analysis Framework for 3D Human Pose Estimation
May 16, 2025Reliable three-dimensional human pose estimation is becoming increasingly important for real-world applications, yet much of prior work has focused solely on the performance within a single dataset. In practice, however, systems must adapt to diverse viewpoints, environments, and camera setups -- conditions that differ significantly from those encountered during training, which is often the case in real-world scenarios. To address these challenges, we present a standardized testing environment in which each method is evaluated on a variety of datasets, ensuring consistent and fair cross-dataset comparisons -- allowing for the analysis of methods on previously unseen data. Therefore, we propose PoseBench3D, a unified framework designed to systematically re-evaluate prior and future models across four of the most widely used datasets for human pose estimation -- with the framework able to support novel and future datasets as the field progresses. Through a unified interface, our framework provides datasets in a pre-configured yet easily modifiable format, ensuring compatibility with diverse model architectures. We re-evaluated the work of 18 methods, either trained or gathered from existing literature, and reported results using both Mean Per Joint Position Error (MPJPE) and Procrustes Aligned Mean Per Joint Position Error (PA-MPJPE) metrics, yielding more than 100 novel cross-dataset evaluation results. Additionally, we analyze performance differences resulting from various pre-processing techniques and dataset preparation parameters -- offering further insight into model generalization capabilities.
3D Human Pose Estimation via Spatial Graph Order Attention and Temporal Body Aware Transformer
May 02, 2025Nowadays, Transformers and Graph Convolutional Networks (GCNs) are the prevailing techniques for 3D human pose estimation. However, Transformer-based methods either ignore the spatial neighborhood relationships between the joints when used for skeleton representations or disregard the local temporal patterns of the local joint movements in skeleton sequence modeling, while GCN-based methods often neglect the need for pose-specific representations. To address these problems, we propose a new method that exploits the graph modeling capability of GCN to represent each skeleton with multiple graphs of different orders, incorporated with a newly introduced Graph Order Attention module that dynamically emphasizes the most representative orders for each joint. The resulting spatial features of the sequence are further processed using a proposed temporal Body Aware Transformer that models the global body feature dependencies in the sequence with awareness of the local inter-skeleton feature dependencies of joints. Given that our 3D pose output aligns with the central 2D pose in the sequence, we improve the self-attention mechanism to be aware of the central pose while diminishing its focus gradually towards the first and the last poses. Extensive experiments on Human3.6m, MPIINF-3DHP, and HumanEva-I datasets demonstrate the effectiveness of the proposed method. Code and models are made available on Github.
When Dance Video Archives Challenge Computer Vision
May 12, 2025



The accuracy and efficiency of human body pose estimation depend on the quality of the data to be processed and of the particularities of these data. To demonstrate how dance videos can challenge pose estimation techniques, we proposed a new 3D human body pose estimation pipeline which combined up-to-date techniques and methods that had not been yet used in dance analysis. Second, we performed tests and extensive experimentations from dance video archives, and used visual analytic tools to evaluate the impact of several data parameters on human body pose. Our results are publicly available for research at https://www.couleur.org/articles/arXiv-1-2025/