 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemmwave radar
Papers and Code
Omnidirectional Solid-State mmWave Radar Perception for UAV Power Line Collision Avoidance
Feb 03, 2026Detecting and estimating distances to power lines is a challenge for both human UAV pilots and autonomous systems, which increases the risk of unintended collisions. We present a mmWave radar-based perception system that provides spherical sensing coverage around a small UAV for robust power line detection and avoidance. The system integrates multiple compact solid-state mmWave radar modules to synthesize an omnidirectional field of view while remaining lightweight. We characterize the sensing behavior of this omnidirectional radar arrangement in power line environments and develop a robust detection-and-avoidance algorithm tailored to that behavior. Field experiments on real power lines demonstrate reliable detection at ranges up to 10 m, successful avoidance maneuvers at flight speeds upwards of 10 m/s, and detection of wires as thin as 1.2 mm in diameter. These results indicate the approach's suitability as an additional safety layer for both autonomous and manual UAV flight.
Generative Latent Alignment for Interpretable Radar Based Occupancy Detection in Ambient Assisted Living
Jan 27, 2026In this work, we study how to make mmWave radar presence detection more interpretable for Ambient Assisted Living (AAL) settings, where camera-based sensing raises privacy concerns. We propose a Generative Latent Alignment (GLA) framework that combines a lightweight convolutional variational autoencoder with a frozen CLIP text encoder to learn a low-dimensional latent representation of radar Range-Angle (RA) heatmaps. The latent space is softly aligned with two semantic anchors corresponding to "empty room" and "person present", and Grad-CAM is applied in this aligned latent space to visualize which spatial regions support each presence decision. On our mmWave radar dataset, we qualitatively observe that the "person present" class produces compact Grad-CAM blobs that coincide with strong RA returns, whereas "empty room" samples yield diffuse or no evidence. We also conduct an ablation study using unrelated text prompts, which degrades both reconstruction and localization, suggesting that radar-specific anchors are important for meaningful explanations in this setting.
Real-Time 4D Radar Perception for Robust Human Detection in Harsh Enclosed Environments
Jan 19, 2026This paper introduces a novel methodology for generating controlled, multi-level dust concentrations in a highly cluttered environment representative of harsh, enclosed environments, such as underground mines, road tunnels, or collapsed buildings, enabling repeatable mm-wave propagation studies under severe electromagnetic constraints. We also present a new 4D mmWave radar dataset, augmented by camera and LiDAR, illustrating how dust particles and reflective surfaces jointly impact the sensing functionality. To address these challenges, we develop a threshold-based noise filtering framework leveraging key radar parameters (RCS, velocity, azimuth, elevation) to suppress ghost targets and mitigate strong multipath reflections at the raw data level. Building on the filtered point clouds, a cluster-level, rule-based classification pipeline exploits radar semantics-velocity, RCS, and volumetric spread-to achieve reliable, real-time pedestrian detection without extensive domainspecific training. Experimental results confirm that this integrated approach significantly enhances clutter mitigation, detection robustness, and overall system resilience in dust-laden mining environments.
A Lightweight Model-Driven 4D Radar Framework for Pervasive Human Detection in Harsh Conditions
Jan 19, 2026Pervasive sensing in industrial and underground environments is severely constrained by airborne dust, smoke, confined geometry, and metallic structures, which rapidly degrade optical and LiDAR based perception. Elevation resolved 4D mmWave radar offers strong resilience to such conditions, yet there remains a limited understanding of how to process its sparse and anisotropic point clouds for reliable human detection in enclosed, visibility degraded spaces. This paper presents a fully model-driven 4D radar perception framework designed for real-time execution on embedded edge hardware. The system uses radar as its sole perception modality and integrates domain aware multi threshold filtering, ego motion compensated temporal accumulation, KD tree Euclidean clustering with Doppler aware refinement, and a rule based 3D classifier. The framework is evaluated in a dust filled enclosed trailer and in real underground mining tunnels, and in the tested scenarios the radar based detector maintains stable pedestrian identification as camera and LiDAR modalities fail under severe visibility degradation. These results suggest that the proposed model-driven approach provides robust, interpretable, and computationally efficient perception for safety-critical applications in harsh industrial and subterranean environments.
Automated Angular Received-Power Characterization of Embedded mmWave Transmitters Using Geometry-Calibrated Spatial Sampling
Jan 18, 2026This paper presents an automated measurement methodology for angular received-power characterization of embedded millimeter-wave transmitters using geometry-calibrated spatial sampling. Characterization of integrated mmWave transmitters remains challenging due to limited angular coverage and alignment variability in conventional probe-station techniques, as well as the impracticality of anechoic-chamber testing for platform-mounted active modules. To address these challenges, we introduce RAPTAR, an autonomous measurement system for angular received-power acquisition under realistic installation constraints. A collaborative robot executes geometry-calibrated, collision-aware hemispherical trajectories while carrying a calibrated receive probe, enabling controlled and repeatable spatial positioning around a fixed device under test. A spectrum-analyzer-based receiver chain acquires amplitude-only received power as a function of angle and distance following quasi-static pose stabilization. The proposed framework enables repeatable angular received-power mapping and power-domain comparison against idealized free-space references derived from full-wave simulation. Experimental results for a 60-GHz radar module demonstrate a mean absolute received-power error below 2 dB relative to simulation-derived references and a 36.5 % reduction in error compared to manual probe-station measurements, attributed primarily to reduced alignment variability and consistent spatial sampling. The proposed method eliminates the need for coherent field measurements and near-field transformations, enabling practical power-domain characterization of embedded mmWave modules. It is well suited for angular validation in real-world platforms where conventional anechoic measurements are impractical.
System-Level Comparison of Multimodal and In-Band mmWave Sensing for Beam Prediction in 6G ISAC
Jan 03, 2026Integrated sensing and communication (ISAC) can reduce beam-training overhead in mmWave vehicle-to-infrastructure (V2I) links by enabling in-band sensing-based beam prediction, while exteroceptive sensors can further enhance the prediction accuracy. This work develop a system-level framework that evaluates camera, LiDAR, radar, GPS, and in-band mmWave power, both individually and in multimodal fusion using the DeepSense-6G Scenario-33 dataset. A latency-aware neural network composed of lightweight convolutional (CNN) and multilayer-perceptron (MLP) encoders predict a 64-beam index. We assess performance using Top-k accuracy alongside spectral-efficiency (SE) gap, signal-to-noise-ratio (SNR) gap, rate loss, and end-to-end latency. Results show that the mmWave power vector is a strong standalone predictor, and fusing exteroceptive sensors with it preserves high performance: mmWave alone and mmWave+LiDAR/GPS/Radar achieve 98% Top-5 accuracy, while mmWave+camera achieves 94% Top-5 accuracy. The proposed framework establishes calibrated baselines for 6G ISAC-assisted beam prediction in V2I systems.
Wavelet-based Multi-View Fusion of 4D Radar Tensor and Camera for Robust 3D Object Detection
Dec 28, 20254D millimeter-wave (mmWave) radar has been widely adopted in autonomous driving and robot perception due to its low cost and all-weather robustness. However, its inherent sparsity and limited semantic richness significantly constrain perception capability. Recently, fusing camera data with 4D radar has emerged as a promising cost effective solution, by exploiting the complementary strengths of the two modalities. Nevertheless, point-cloud-based radar often suffer from information loss introduced by multi-stage signal processing, while directly utilizing raw 4D radar data incurs prohibitive computational costs. To address these challenges, we propose WRCFormer, a novel 3D object detection framework that fuses raw radar cubes with camera inputs via multi-view representations of the decoupled radar cube. Specifically, we design a Wavelet Attention Module as the basic module of wavelet-based Feature Pyramid Network (FPN) to enhance the representation of sparse radar signals and image data. We further introduce a two-stage query-based, modality-agnostic fusion mechanism termed Geometry-guided Progressive Fusion to efficiently integrate multi-view features from both modalities. Extensive experiments demonstrate that WRCFormer achieves state-of-the-art performance on the K-Radar benchmarks, surpassing the best model by approximately 2.4% in all scenarios and 1.6% in the sleet scenario, highlighting its robustness under adverse weather conditions.
milliMamba: Specular-Aware Human Pose Estimation via Dual mmWave Radar with Multi-Frame Mamba Fusion
Dec 23, 2025



Millimeter-wave radar offers a privacy-preserving and lighting-invariant alternative to RGB sensors for Human Pose Estimation (HPE) task. However, the radar signals are often sparse due to specular reflection, making the extraction of robust features from radar signals highly challenging. To address this, we present milliMamba, a radar-based 2D human pose estimation framework that jointly models spatio-temporal dependencies across both the feature extraction and decoding stages. Specifically, given the high dimensionality of radar inputs, we adopt a Cross-View Fusion Mamba encoder to efficiently extract spatio-temporal features from longer sequences with linear complexity. A Spatio-Temporal-Cross Attention decoder then predicts joint coordinates across multiple frames. Together, this spatio-temporal modeling pipeline enables the model to leverage contextual cues from neighboring frames and joints to infer missing joints caused by specular reflections. To reinforce motion smoothness, we incorporate a velocity loss alongside the standard keypoint loss during training. Experiments on the TransHuPR and HuPR datasets demonstrate that our method achieves significant performance improvements, exceeding the baselines by 11.0 AP and 14.6 AP, respectively, while maintaining reasonable complexity. Code: https://github.com/NYCU-MAPL/milliMamba
M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
Dec 17, 2025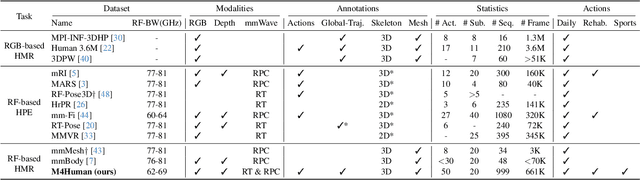
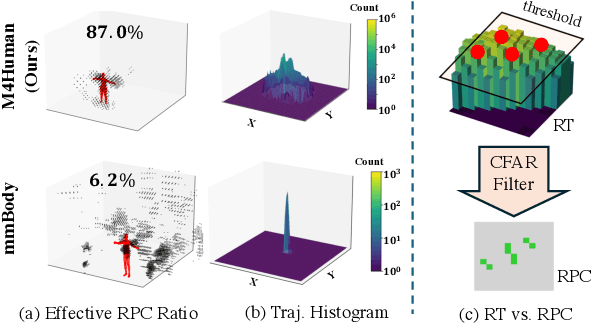

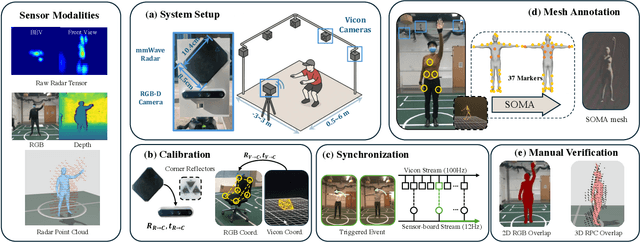
Human mesh reconstruction (HMR) provides direct insights into body-environment interaction, which enables various immersive applications. While existing large-scale HMR datasets rely heavily on line-of-sight RGB input, vision-based sensing is limited by occlusion, lighting variation, and privacy concerns. To overcome these limitations, recent efforts have explored radio-frequency (RF) mmWave radar for privacy-preserving indoor human sensing. However, current radar datasets are constrained by sparse skeleton labels, limited scale, and simple in-place actions. To advance the HMR research community, we introduce M4Human, the current largest-scale (661K-frame) ($9\times$ prior largest) multimodal benchmark, featuring high-resolution mmWave radar, RGB, and depth data. M4Human provides both raw radar tensors (RT) and processed radar point clouds (RPC) to enable research across different levels of RF signal granularity. M4Human includes high-quality motion capture (MoCap) annotations with 3D meshes and global trajectories, and spans 20 subjects and 50 diverse actions, including in-place, sit-in-place, and free-space sports or rehabilitation movements. We establish benchmarks on both RT and RPC modalities, as well as multimodal fusion with RGB-D modalities. Extensive results highlight the significance of M4Human for radar-based human modeling while revealing persistent challenges under fast, unconstrained motion. The dataset and code will be released after the paper publication.
Comprehensive Deployment-Oriented Assessment for Cross-Environment Generalization in Deep Learning-Based mmWave Radar Sensing
Dec 15, 2025



This study presents the first comprehensive evaluation of spatial generalization techniques, which are essential for the practical deployment of deep learning-based radio-frequency (RF) sensing. Focusing on people counting in indoor environments using frequency-modulated continuous-wave (FMCW) multiple-input multiple-output (MIMO) radar, we systematically investigate a broad set of approaches, including amplitude-based statistical preprocessing (sigmoid weighting and threshold zeroing), frequency-domain filtering, autoencoder-based background suppression, data augmentation strategies, and transfer learning. Experimental results collected across two environments with different layouts demonstrate that sigmoid-based amplitude weighting consistently achieves superior cross-environment performance, yielding 50.1% and 55.2% reductions in root-mean-square error (RMSE) and mean absolute error (MAE), respectively, compared with baseline methods. Data augmentation provides additional though modest benefits, with improvements up to 8.8% in MAE. By contrast, transfer learning proves indispensable for large spatial shifts, achieving 82.1% and 91.3% reductions in RMSE and MAE, respectively, with 540 target-domain samples. Taken together, these findings establish a highly practical direction for developing radar sensing systems capable of maintaining robust accuracy under spatial variations by integrating deep learning models with amplitude-based preprocessing and efficient transfer learning.