 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time 4D Radar Perception for Robust Human Detection in Harsh Enclosed Environments
Jan 19, 2026This paper introduces a novel methodology for generating controlled, multi-level dust concentrations in a highly cluttered environment representative of harsh, enclosed environments, such as underground mines, road tunnels, or collapsed buildings, enabling repeatable mm-wave propagation studies under severe electromagnetic constraints. We also present a new 4D mmWave radar dataset, augmented by camera and LiDAR, illustrating how dust particles and reflective surfaces jointly impact the sensing functionality. To address these challenges, we develop a threshold-based noise filtering framework leveraging key radar parameters (RCS, velocity, azimuth, elevation) to suppress ghost targets and mitigate strong multipath reflections at the raw data level. Building on the filtered point clouds, a cluster-level, rule-based classification pipeline exploits radar semantics-velocity, RCS, and volumetric spread-to achieve reliable, real-time pedestrian detection without extensive domainspecific training. Experimental results confirm that this integrated approach significantly enhances clutter mitigation, detection robustness, and overall system resilience in dust-laden mining environments.
Enhancing Indoor Mobility with Connected Sensor Nodes: A Real-Time, Delay-Aware Cooperative Perception Approach
Nov 04, 2024



This paper presents a novel real-time, delay-aware cooperative perception system designed for intelligent mobility platforms operating in dynamic indoor environments. The system contains a network of multi-modal sensor nodes and a central node that collectively provide perception services to mobility platforms. The proposed Hierarchical Clustering Considering the Scanning Pattern and Ground Contacting Feature based Lidar Camera Fusion improve intra-node perception for crowded environment. The system also features delay-aware global perception to synchronize and aggregate data across nodes. To validate our approach, we introduced the Indoor Pedestrian Tracking dataset, compiled from data captured by two indoor sensor nodes. Our experiments, compared to baselines, demonstrate significant improvements in detection accuracy and robustness against delays. The dataset is available in the repository: https://github.com/NingMingHao/MVSLab-IndoorCooperativePerception
A Spontaneous Driver Emotion Facial Expression (DEFE) Dataset for Intelligent Vehicles
Apr 26, 2020
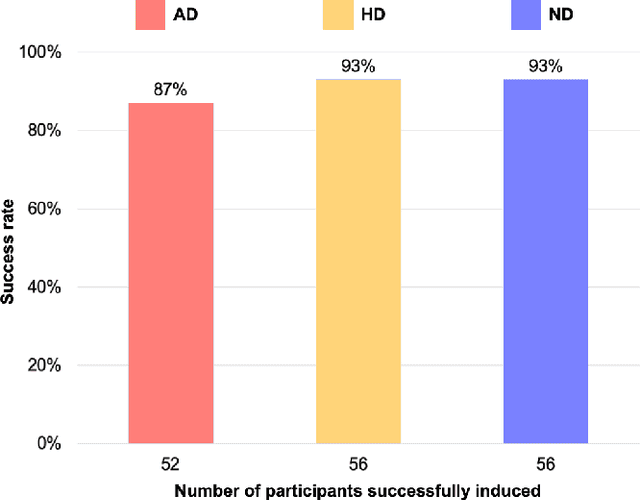
In this paper, we introduce a new dataset, the driver emotion facial expression (DEFE) dataset, for driver spontaneous emotions analysis. The dataset includes facial expression recordings from 60 participants during driving. After watching a selected video-audio clip to elicit a specific emotion, each participant completed the driving tasks in the same driving scenario and rated their emotional responses during the driving processes from the aspects of dimensional emotion and discrete emotion. We also conducted classification experiments to recognize the scales of arousal, valence, dominance, as well as the emotion category and intensity to establish baseline results for the proposed dataset. Besides, this paper compared and discussed the differences in facial expressions between driving and non-driving scenarios. The results show that there were significant differences in AUs (Action Units) presence of facial expressions between driving and non-driving scenarios, indicating that human emotional expressions in driving scenarios were different from other life scenarios. Therefore, publishing a human emotion dataset specifically for the driver is necessary for traffic safety improvement. The proposed dataset will be publicly available so that researchers worldwide can use it to develop and examine their driver emotion analysis methods. To the best of our knowledge, this is currently the only public driver facial expression dataset.
Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review
Apr 10, 2020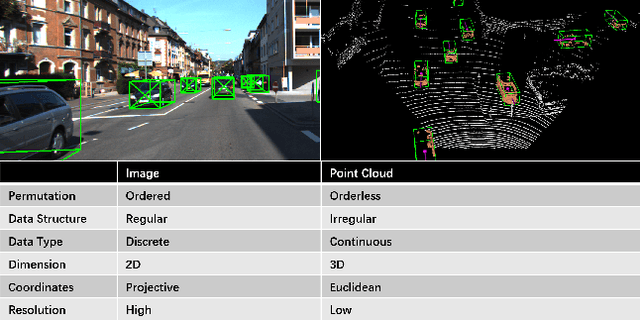
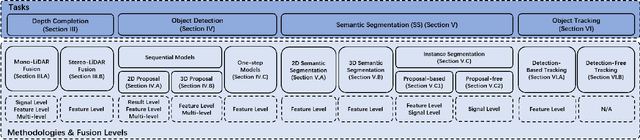
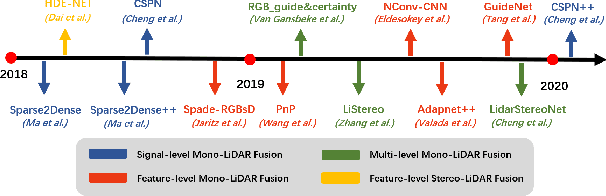
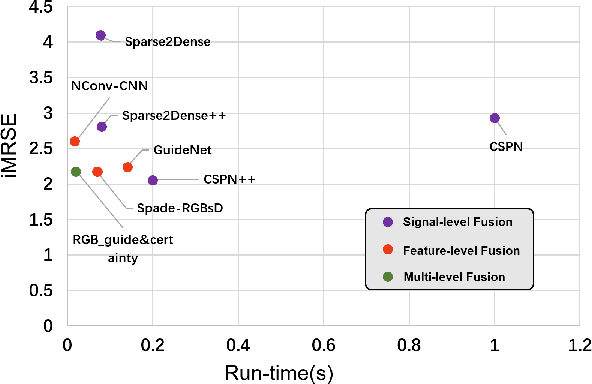
Autonomous vehicles are experiencing rapid development in the past few years. However, achieving full autonomy is not a trivial task, due to the nature of the complex and dynamic driving environment. Therefore, autonomous vehicles are equipped with a suite of different sensors to ensure robust, accurate environmental perception. In particular, camera-LiDAR fusion is becoming an emerging research theme. However, so far there is no critical review that focuses on deep-learning-based camera-LiDAR fusion methods. To bridge this gap and motivate future research, this paper devotes to review recent deep-learning-based data fusion approaches that leverage both image and point cloud. This review gives a brief overview of deep learning on image and point cloud data processing. Followed by in-depth reviews of camera-LiDAR fusion methods in depth completion, object detection, semantic segmentation and tracking, which are organized based on their respective fusion levels. Furthermore, we compare these methods on publicly available datasets. Finally, we identified gaps and over-looked challenges between current academic researches and real-world applications. Based on these observations, we provide our insights and point out promising research directions.