 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Video Object Segmentation
Papers and Code
Refer-Agent: A Collaborative Multi-Agent System with Reasoning and Reflection for Referring Video Object Segmentation
Feb 03, 2026Referring Video Object Segmentation (RVOS) aims to segment objects in videos based on textual queries. Current methods mainly rely on large-scale supervised fine-tuning (SFT) of Multi-modal Large Language Models (MLLMs). However, this paradigm suffers from heavy data dependence and limited scalability against the rapid evolution of MLLMs. Although recent zero-shot approaches offer a flexible alternative, their performance remains significantly behind SFT-based methods, due to the straightforward workflow designs. To address these limitations, we propose \textbf{Refer-Agent}, a collaborative multi-agent system with alternating reasoning-reflection mechanisms. This system decomposes RVOS into step-by-step reasoning process. During reasoning, we introduce a Coarse-to-Fine frame selection strategy to ensure the frame diversity and textual relevance, along with a Dynamic Focus Layout that adaptively adjusts the agent's visual focus. Furthermore, we propose a Chain-of-Reflection mechanism, which employs a Questioner-Responder pair to generate a self-reflection chain, enabling the system to verify intermediate results and generates feedback for next-round reasoning refinement. Extensive experiments on five challenging benchmarks demonstrate that Refer-Agent significantly outperforms state-of-the-art methods, including both SFT-based models and zero-shot approaches. Moreover, Refer-Agent is flexible and enables fast integration of new MLLMs without any additional fine-tuning costs. Code will be released.
TC-IDM: Grounding Video Generation for Executable Zero-shot Robot Motion
Jan 26, 2026The vision-language-action (VLA) paradigm has enabled powerful robotic control by leveraging vision-language models, but its reliance on large-scale, high-quality robot data limits its generalization. Generative world models offer a promising alternative for general-purpose embodied AI, yet a critical gap remains between their pixel-level plans and physically executable actions. To this end, we propose the Tool-Centric Inverse Dynamics Model (TC-IDM). By focusing on the tool's imagined trajectory as synthesized by the world model, TC-IDM establishes a robust intermediate representation that bridges the gap between visual planning and physical control. TC-IDM extracts the tool's point cloud trajectories via segmentation and 3D motion estimation from generated videos. Considering diverse tool attributes, our architecture employs decoupled action heads to project these planned trajectories into 6-DoF end-effector motions and corresponding control signals. This plan-and-translate paradigm not only supports a wide range of end-effectors but also significantly improves viewpoint invariance. Furthermore, it exhibits strong generalization capabilities across long-horizon and out-of-distribution tasks, including interacting with deformable objects. In real-world evaluations, the world model with TC-IDM achieves an average success rate of 61.11 percent, with 77.7 percent on simple tasks and 38.46 percent on zero-shot deformable object tasks. It substantially outperforms end-to-end VLA-style baselines and other inverse dynamics models.
PyraTok: Language-Aligned Pyramidal Tokenizer for Video Understanding and Generation
Jan 22, 2026Discrete video VAEs underpin modern text-to-video generation and video understanding systems, yet existing tokenizers typically learn visual codebooks at a single scale with limited vocabularies and shallow language supervision, leading to poor cross-modal alignment and zero-shot transfer. We introduce PyraTok, a language-aligned pyramidal tokenizer that learns semantically structured discrete latents across multiple spatiotemporal resolutions. PyraTok builds on a pretrained video VAE and a novel Language aligned Pyramidal Quantization (LaPQ) module that discretizes encoder features at several depths using a shared large binary codebook, yielding compact yet expressive video token sequences. To tightly couple visual tokens with language, PyraTok jointly optimizes multi-scale text-guided quantization and a global autoregressive objective over the token hierarchy. Across ten benchmarks, PyraTok delivers state-of-the-art (SOTA) video reconstruction, consistently improves text-to-video quality, and sets new SOTA zero-shot performance on video segmentation, temporal action localization, and video understanding, scaling robustly to up to 4K/8K resolutions.
Memory-Enhanced SAM3 for Occlusion-Robust Surgical Instrument Segmentation
Dec 18, 2025Accurate surgical instrument segmentation in endoscopic videos is crucial for computer-assisted interventions, yet remains challenging due to frequent occlusions, rapid motion, specular artefacts, and long-term instrument re-entry. While SAM3 provides a powerful spatio-temporal framework for video object segmentation, its performance in surgical scenes is limited by indiscriminate memory updates, fixed memory capacity, and weak identity recovery after occlusions. We propose ReMeDI-SAM3, a training-free memory-enhanced extension of SAM3, that addresses these limitations through three components: (i) relevance-aware memory filtering with a dedicated occlusion-aware memory for storing pre-occlusion frames, (ii) a piecewise interpolation scheme that expands the effective memory capacity, and (iii) a feature-based re-identification module with temporal voting for reliable post-occlusion identity disambiguation. Together, these components mitigate error accumulation and enable reliable recovery after occlusions. Evaluations on EndoVis17 and EndoVis18 under a zero-shot setting show absolute mcIoU improvements of around 7% and 16%, respectively, over vanilla SAM3, outperforming even prior training-based approaches. Project page: https://valaybundele.github.io/remedi-sam3/.
When Tracking Fails: Analyzing Failure Modes of SAM2 for Point-Based Tracking in Surgical Videos
Oct 02, 2025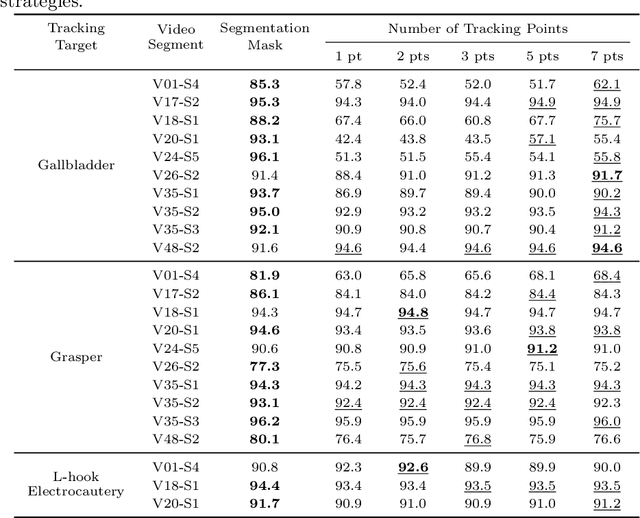
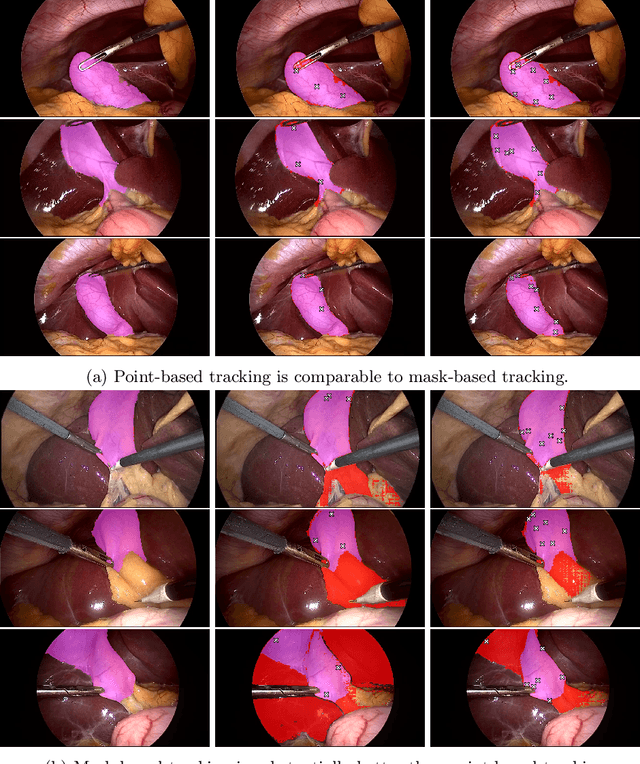

Video object segmentation (VOS) models such as SAM2 offer promising zero-shot tracking capabilities for surgical videos using minimal user input. Among the available input types, point-based tracking offers an efficient and low-cost alternative, yet its reliability and failure cases in complex surgical environments are not well understood. In this work, we systematically analyze the failure modes of point-based tracking in laparoscopic cholecystectomy videos. Focusing on three surgical targets, the gallbladder, grasper, and L-hook electrocautery, we compare the performance of point-based tracking with segmentation mask initialization. Our results show that point-based tracking is competitive for surgical tools but consistently underperforms for anatomical targets, where tissue similarity and ambiguous boundaries lead to failure. Through qualitative analysis, we reveal key factors influencing tracking outcomes and provide several actionable recommendations for selecting and placing tracking points to improve performance in surgical video analysis.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
SAGOnline: Segment Any Gaussians Online
Aug 11, 20253D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for explicit 3D scene representation, yet achieving efficient and consistent 3D segmentation remains challenging. Current methods suffer from prohibitive computational costs, limited 3D spatial reasoning, and an inability to track multiple objects simultaneously. We present Segment Any Gaussians Online (SAGOnline), a lightweight and zero-shot framework for real-time 3D segmentation in Gaussian scenes that addresses these limitations through two key innovations: (1) a decoupled strategy that integrates video foundation models (e.g., SAM2) for view-consistent 2D mask propagation across synthesized views; and (2) a GPU-accelerated 3D mask generation and Gaussian-level instance labeling algorithm that assigns unique identifiers to 3D primitives, enabling lossless multi-object tracking and segmentation across views. SAGOnline achieves state-of-the-art performance on NVOS (92.7% mIoU) and Spin-NeRF (95.2% mIoU) benchmarks, outperforming Feature3DGS, OmniSeg3D-gs, and SA3D by 15--1500 times in inference speed (27 ms/frame). Qualitative results demonstrate robust multi-object segmentation and tracking in complex scenes. Our contributions include: (i) a lightweight and zero-shot framework for 3D segmentation in Gaussian scenes, (ii) explicit labeling of Gaussian primitives enabling simultaneous segmentation and tracking, and (iii) the effective adaptation of 2D video foundation models to the 3D domain. This work allows real-time rendering and 3D scene understanding, paving the way for practical AR/VR and robotic applications.
EgoLoc: A Generalizable Solution for Temporal Interaction Localization in Egocentric Videos
Aug 17, 2025Analyzing hand-object interaction in egocentric vision facilitates VR/AR applications and human-robot policy transfer. Existing research has mostly focused on modeling the behavior paradigm of interactive actions (i.e., ``how to interact''). However, the more challenging and fine-grained problem of capturing the critical moments of contact and separation between the hand and the target object (i.e., ``when to interact'') is still underexplored, which is crucial for immersive interactive experiences in mixed reality and robotic motion planning. Therefore, we formulate this problem as temporal interaction localization (TIL). Some recent works extract semantic masks as TIL references, but suffer from inaccurate object grounding and cluttered scenarios. Although current temporal action localization (TAL) methods perform well in detecting verb-noun action segments, they rely on category annotations during training and exhibit limited precision in localizing hand-object contact/separation moments. To address these issues, we propose a novel zero-shot approach dubbed EgoLoc to localize hand-object contact and separation timestamps in egocentric videos. EgoLoc introduces hand-dynamics-guided sampling to generate high-quality visual prompts. It exploits the vision-language model to identify contact/separation attributes, localize specific timestamps, and provide closed-loop feedback for further refinement. EgoLoc eliminates the need for object masks and verb-noun taxonomies, leading to generalizable zero-shot implementation. Comprehensive experiments on the public dataset and our novel benchmarks demonstrate that EgoLoc achieves plausible TIL for egocentric videos. It is also validated to effectively facilitate multiple downstream applications in egocentric vision and robotic manipulation tasks. Code and relevant data will be released at https://github.com/IRMVLab/EgoLoc.
Studying Image Diffusion Features for Zero-Shot Video Object Segmentation
Apr 07, 2025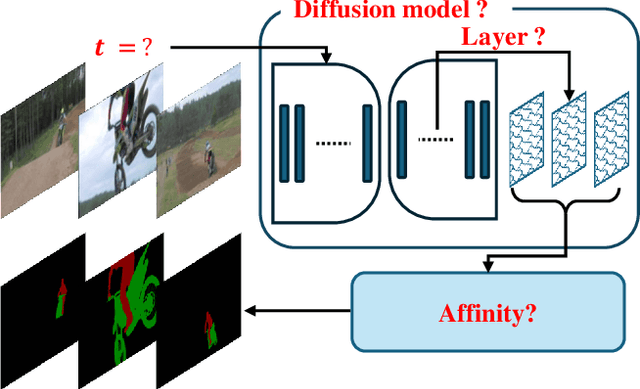
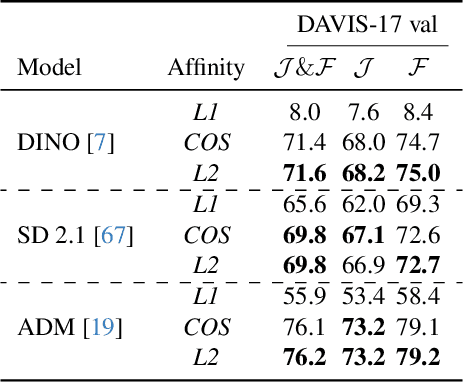
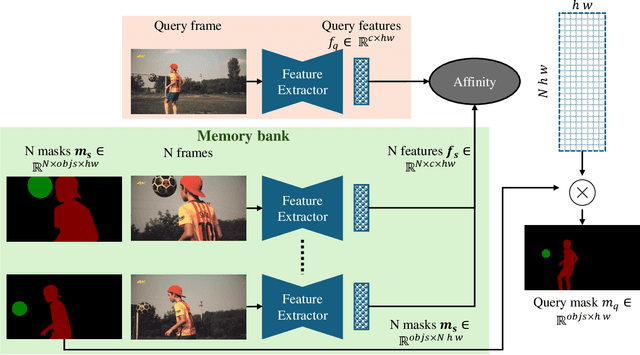
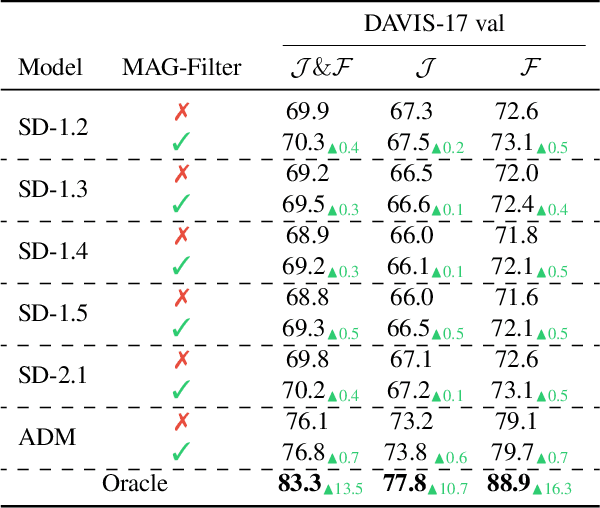
This paper investigates the use of large-scale diffusion models for Zero-Shot Video Object Segmentation (ZS-VOS) without fine-tuning on video data or training on any image segmentation data. While diffusion models have demonstrated strong visual representations across various tasks, their direct application to ZS-VOS remains underexplored. Our goal is to find the optimal feature extraction process for ZS-VOS by identifying the most suitable time step and layer from which to extract features. We further analyze the affinity of these features and observe a strong correlation with point correspondences. Through extensive experiments on DAVIS-17 and MOSE, we find that diffusion models trained on ImageNet outperform those trained on larger, more diverse datasets for ZS-VOS. Additionally, we highlight the importance of point correspondences in achieving high segmentation accuracy, and we yield state-of-the-art results in ZS-VOS. Finally, our approach performs on par with models trained on expensive image segmentation datasets.
ThinkVideo: High-Quality Reasoning Video Segmentation with Chain of Thoughts
May 24, 2025Reasoning Video Object Segmentation is a challenging task, which generates a mask sequence from an input video and an implicit, complex text query. Existing works probe into the problem by finetuning Multimodal Large Language Models (MLLM) for segmentation-based output, while still falling short in difficult cases on videos given temporally-sensitive queries, primarily due to the failure to integrate temporal and spatial information. In this paper, we propose ThinkVideo, a novel framework which leverages the zero-shot Chain-of-Thought (CoT) capability of MLLM to address these challenges. Specifically, ThinkVideo utilizes the CoT prompts to extract object selectivities associated with particular keyframes, then bridging the reasoning image segmentation model and SAM2 video processor to output mask sequences. The ThinkVideo framework is training-free and compatible with closed-source MLLMs, which can be applied to Reasoning Video Instance Segmentation. We further extend the framework for online video streams, where the CoT is used to update the object of interest when a better target starts to emerge and becomes visible. We conduct extensive experiments on video object segmentation with explicit and implicit queries. The results show that ThinkVideo significantly outperforms previous works in both cases, qualitatively and quantitatively.