 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGOnline: Segment Any Gaussians Online
Aug 11, 20253D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for explicit 3D scene representation, yet achieving efficient and consistent 3D segmentation remains challenging. Current methods suffer from prohibitive computational costs, limited 3D spatial reasoning, and an inability to track multiple objects simultaneously. We present Segment Any Gaussians Online (SAGOnline), a lightweight and zero-shot framework for real-time 3D segmentation in Gaussian scenes that addresses these limitations through two key innovations: (1) a decoupled strategy that integrates video foundation models (e.g., SAM2) for view-consistent 2D mask propagation across synthesized views; and (2) a GPU-accelerated 3D mask generation and Gaussian-level instance labeling algorithm that assigns unique identifiers to 3D primitives, enabling lossless multi-object tracking and segmentation across views. SAGOnline achieves state-of-the-art performance on NVOS (92.7% mIoU) and Spin-NeRF (95.2% mIoU) benchmarks, outperforming Feature3DGS, OmniSeg3D-gs, and SA3D by 15--1500 times in inference speed (27 ms/frame). Qualitative results demonstrate robust multi-object segmentation and tracking in complex scenes. Our contributions include: (i) a lightweight and zero-shot framework for 3D segmentation in Gaussian scenes, (ii) explicit labeling of Gaussian primitives enabling simultaneous segmentation and tracking, and (iii) the effective adaptation of 2D video foundation models to the 3D domain. This work allows real-time rendering and 3D scene understanding, paving the way for practical AR/VR and robotic applications.
PointGauss: Point Cloud-Guided Multi-Object Segmentation for Gaussian Splatting
Aug 01, 2025



We introduce PointGauss, a novel point cloud-guided framework for real-time multi-object segmentation in Gaussian Splatting representations. Unlike existing methods that suffer from prolonged initialization and limited multi-view consistency, our approach achieves efficient 3D segmentation by directly parsing Gaussian primitives through a point cloud segmentation-driven pipeline. The key innovation lies in two aspects: (1) a point cloud-based Gaussian primitive decoder that generates 3D instance masks within 1 minute, and (2) a GPU-accelerated 2D mask rendering system that ensures multi-view consistency. Extensive experiments demonstrate significant improvements over previous state-of-the-art methods, achieving performance gains of 1.89 to 31.78% in multi-view mIoU, while maintaining superior computational efficiency. To address the limitations of current benchmarks (single-object focus, inconsistent 3D evaluation, small scale, and partial coverage), we present DesktopObjects-360, a novel comprehensive dataset for 3D segmentation in radiance fields, featuring: (1) complex multi-object scenes, (2) globally consistent 2D annotations, (3) large-scale training data (over 27 thousand 2D masks), (4) full 360{\deg} coverage, and (5) 3D evaluation masks.
OpenGF: An Ultra-Large-Scale Ground Filtering Dataset Built Upon Open ALS Point Clouds Around the World
Jan 24, 2021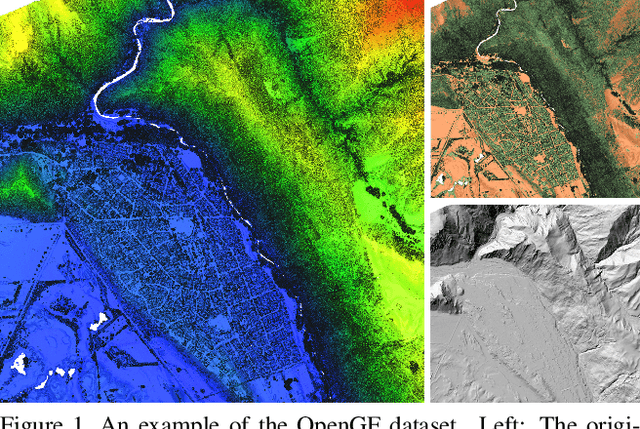
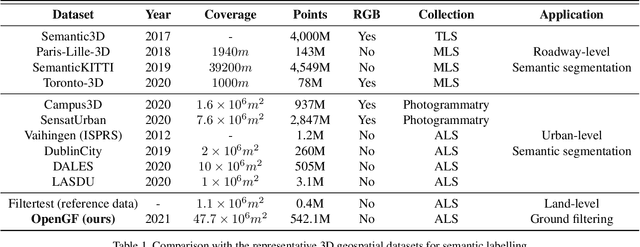


Ground filtering has remained a widely studied but incompletely resolved bottleneck for decades in the automatic generation of high-precision digital elevation model, due to the dramatic changes of topography and the complex structures of objects. The recent breakthrough of supervised deep learning algorithms in 3D scene understanding brings new solutions for better solving such problems. However, there are few large-scale and scene-rich public datasets dedicated to ground extraction, which considerably limits the development of effective deep-learning-based ground filtering methods. To this end, we present OpenGF, first Ultra-Large-Scale Ground Filtering dataset covering over 47 $km^2$ of 9 different typical terrain scenes built upon open ALS point clouds of 4 different countries around the world. OpenGF contains more than half a billion finely labeled ground and non-ground points, thousands of times the number of labeled points than the de facto standard ISPRS filtertest dataset. We extensively evaluate the performance of state-of-the-art rule-based algorithms and 3D semantic segmentation networks on our dataset and provide a comprehensive analysis. The results have confirmed the capability of OpenGF to train deep learning models effectively. This dataset will be released at https://github.com/Nathan-UW/OpenGF to promote more advancing research for ground filtering and large-scale 3D geographic environment understanding.
UAV LiDAR Point Cloud Segmentation of A Stack Interchange with Deep Neural Networks
Oct 21, 2020Stack interchanges are essential components of transportation systems. Mobile laser scanning (MLS) systems have been widely used in road infrastructure mapping, but accurate mapping of complicated multi-layer stack interchanges are still challenging. This study examined the point clouds collected by a new Unmanned Aerial Vehicle (UAV) Light Detection and Ranging (LiDAR) system to perform the semantic segmentation task of a stack interchange. An end-to-end supervised 3D deep learning framework was proposed to classify the point clouds. The proposed method has proven to capture 3D features in complicated interchange scenarios with stacked convolution and the result achieved over 93% classification accuracy. In addition, the new low-cost semi-solid-state LiDAR sensor Livox Mid-40 featuring a incommensurable rosette scanning pattern has demonstrated its potential in high-definition urban mapping.