 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-IDM: Grounding Video Generation for Executable Zero-shot Robot Motion
Jan 26, 2026The vision-language-action (VLA) paradigm has enabled powerful robotic control by leveraging vision-language models, but its reliance on large-scale, high-quality robot data limits its generalization. Generative world models offer a promising alternative for general-purpose embodied AI, yet a critical gap remains between their pixel-level plans and physically executable actions. To this end, we propose the Tool-Centric Inverse Dynamics Model (TC-IDM). By focusing on the tool's imagined trajectory as synthesized by the world model, TC-IDM establishes a robust intermediate representation that bridges the gap between visual planning and physical control. TC-IDM extracts the tool's point cloud trajectories via segmentation and 3D motion estimation from generated videos. Considering diverse tool attributes, our architecture employs decoupled action heads to project these planned trajectories into 6-DoF end-effector motions and corresponding control signals. This plan-and-translate paradigm not only supports a wide range of end-effectors but also significantly improves viewpoint invariance. Furthermore, it exhibits strong generalization capabilities across long-horizon and out-of-distribution tasks, including interacting with deformable objects. In real-world evaluations, the world model with TC-IDM achieves an average success rate of 61.11 percent, with 77.7 percent on simple tasks and 38.46 percent on zero-shot deformable object tasks. It substantially outperforms end-to-end VLA-style baselines and other inverse dynamics models.
Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
Target-Dependent Chemical Species Tomography with Hybrid Meshing of Sensing Regions
Feb 10, 2021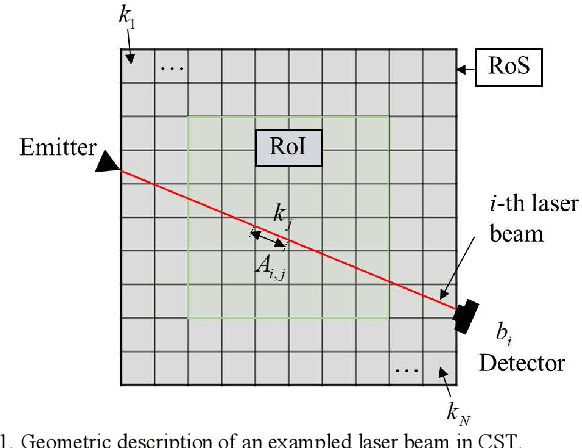
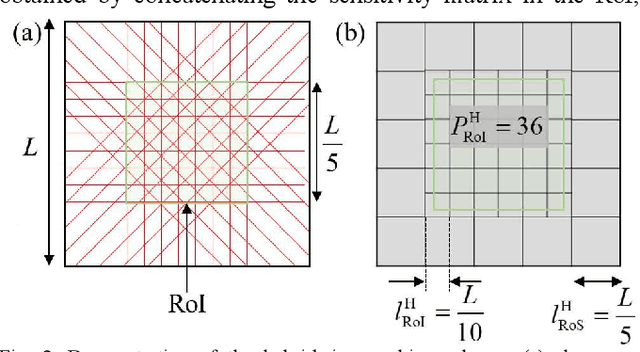
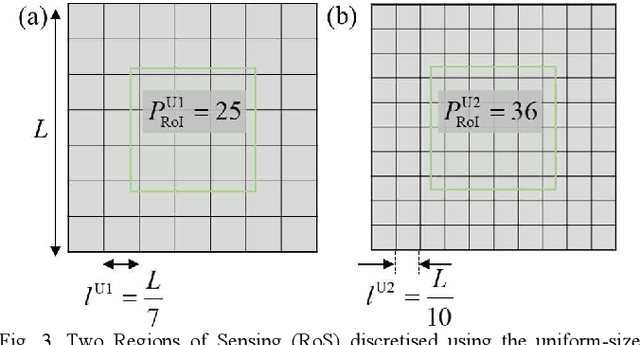
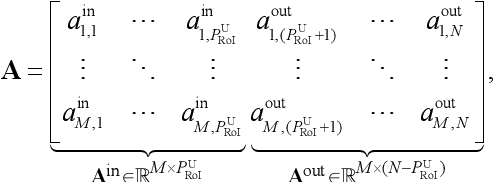
This paper develops a hybrid-size meshing scheme for target-dependent imaging in Chemical Species Tomography (CST). The traditional implementation of CST generally places the target field in the central region of laser sensing, the so-called Region of Interest (RoI), with uniform-size meshes. The centre of the RoI locates at the midpoint between the laser emitters and receivers, while the size of the RoI is empirically determined by the optical layout. A too small RoI cannot make the most use of laser beams, while a too large one leads to much severer rank deficiency in CST. To solve the above-mentioned issues, we introduce hybrid-size meshes in the entire region of laser sensing, with dense ones in the RoI to detail the target flow field and sparse ones out of the RoI to fully consider the physically existing laser absorption. The proposed scheme was both numerically and experimentally validated using a CST sensor with 32 laser beams. The images reconstructed using the hybrid-size meshing scheme show better accuracy and finer profile of the target flow, compared with those reconstructed using the traditionally uniform-size meshing. The proposed hybrid-size meshing scheme significantly facilitates the industrial application of CST towards practical combustors, in which the combustion zone is bypassed by cooling air. In these scenarios, the proposed scheme can better characterise the combustion zone with dense meshes, while maintaining the integrity of the physical model by considering the absorption in the bypass air with sparse meshes.