 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-Weighted CLIP for Street-View Geo-localization
Apr 06, 2026This paper proposes Spatially-Weighted CLIP (SW-CLIP), a novel framework for street-view geo-localization that explicitly incorporates spatial autocorrelation into vision-language contrastive learning. Unlike conventional CLIP-based methods that treat all non-matching samples as equally negative, SW-CLIP leverages Tobler's First Law of Geography to model geographic relationships through distance-aware soft supervision. Specifically, we introduce a location-as-text representation to encode geographic positions and replace one-hot InfoNCE targets with spatially weighted soft labels derived from geodesic distance. Additionally, a neighborhood-consistency regularization is employed to preserve local spatial structure in the embedding space. Experiments on a multi-city dataset demonstrate that SW-CLIP significantly improves geo-localization accuracy, reduces long-tail errors, and enhances spatial coherence compared to standard CLIP. The results highlight the importance of shifting from semantic alignment to geographic alignment for robust geo-localization and provide a general paradigm for integrating spatial principles into multimodal representation learning.
3DCity-LLM: Empowering Multi-modality Large Language Models for 3D City-scale Perception and Understanding
Mar 24, 2026While multi-modality large language models excel in object-centric or indoor scenarios, scaling them to 3D city-scale environments remains a formidable challenge. To bridge this gap, we propose 3DCity-LLM, a unified framework designed for 3D city-scale vision-language perception and understanding. 3DCity-LLM employs a coarse-to-fine feature encoding strategy comprising three parallel branches for target object, inter-object relationship, and global scene. To facilitate large-scale training, we introduce 3DCity-LLM-1.2M dataset that comprises approximately 1.2 million high-quality samples across seven representative task categories, ranging from fine-grained object analysis to multi-faceted scene planning. This strictly quality-controlled dataset integrates explicit 3D numerical information and diverse user-oriented simulations, enriching the question-answering diversity and realism of urban scenarios. Furthermore, we apply a multi-dimensional protocol based on text-similarity metrics and LLM-based semantic assessment to ensure faithful and comprehensive evaluations for all methods. Extensive experiments on two benchmarks demonstrate that 3DCity-LLM significantly outperforms existing state-of-the-art methods, offering a promising and meaningful direction for advancing spatial reasoning and urban intelligence. The source code and dataset are available at https://github.com/SYSU-3DSTAILab/3D-City-LLM.
A Large-Scale Remote Sensing Dataset and VLM-based Algorithm for Fine-Grained Road Hierarchy Classification
Mar 22, 2026In this work, we present SYSU-HiRoads, a large-scale hierarchical road dataset, and RoadReasoner, a vision-language-geometry framework for automatic multi-grade road mapping from remote sensing imagery. SYSU-HiRoads is built from GF-2 imagery covering 3631 km2 in Henan Province, China, and contains 1079 image tiles at 0.8 m spatial resolution. Each tile is annotated with dense road masks, vectorized centerlines, and three-level hierarchy labels, enabling the joint training and evaluation of segmentation, topology reconstruction, and hierarchy classification. Building on this dataset, RoadReasoner is designed to generate robust road surface masks, topology-preserving road networks, and semantically coherent hierarchy assignments. We strengthen road feature representation and network connectivity by explicitly enhancing frequency-sensitive cues and multi-scale context. Moreover, we perform hierarchy inference at the skeleton-segment level with geometric descriptors and geometry-aware textual prompts, queried by vision-language models to obtain linguistically interpretable grade decisions. Experiments on SYSU-HiRoads and the CHN6-CUG dataset show that RoadReasoner surpasses state-of-the-art road extraction baselines and produces accurate and semantically consistent road hierarchy maps with 72.6% OA, 64.2% F1 score, and 60.6% SegAcc. The dataset and code will be publicly released to support automated transport infrastructure mapping, road inventory updating, and broader infrastructure management applications.
SGS-3D: High-Fidelity 3D Instance Segmentation via Reliable Semantic Mask Splitting and Growing
Sep 05, 2025Accurate 3D instance segmentation is crucial for high-quality scene understanding in the 3D vision domain. However, 3D instance segmentation based on 2D-to-3D lifting approaches struggle to produce precise instance-level segmentation, due to accumulated errors introduced during the lifting process from ambiguous semantic guidance and insufficient depth constraints. To tackle these challenges, we propose splitting and growing reliable semantic mask for high-fidelity 3D instance segmentation (SGS-3D), a novel "split-then-grow" framework that first purifies and splits ambiguous lifted masks using geometric primitives, and then grows them into complete instances within the scene. Unlike existing approaches that directly rely on raw lifted masks and sacrifice segmentation accuracy, SGS-3D serves as a training-free refinement method that jointly fuses semantic and geometric information, enabling effective cooperation between the two levels of representation. Specifically, for semantic guidance, we introduce a mask filtering strategy that leverages the co-occurrence of 3D geometry primitives to identify and remove ambiguous masks, thereby ensuring more reliable semantic consistency with the 3D object instances. For the geometric refinement, we construct fine-grained object instances by exploiting both spatial continuity and high-level features, particularly in the case of semantic ambiguity between distinct objects. Experimental results on ScanNet200, ScanNet++, and KITTI-360 demonstrate that SGS-3D substantially improves segmentation accuracy and robustness against inaccurate masks from pre-trained models, yielding high-fidelity object instances while maintaining strong generalization across diverse indoor and outdoor environments. Code is available in the supplementary materials.
SAGOnline: Segment Any Gaussians Online
Aug 11, 20253D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for explicit 3D scene representation, yet achieving efficient and consistent 3D segmentation remains challenging. Current methods suffer from prohibitive computational costs, limited 3D spatial reasoning, and an inability to track multiple objects simultaneously. We present Segment Any Gaussians Online (SAGOnline), a lightweight and zero-shot framework for real-time 3D segmentation in Gaussian scenes that addresses these limitations through two key innovations: (1) a decoupled strategy that integrates video foundation models (e.g., SAM2) for view-consistent 2D mask propagation across synthesized views; and (2) a GPU-accelerated 3D mask generation and Gaussian-level instance labeling algorithm that assigns unique identifiers to 3D primitives, enabling lossless multi-object tracking and segmentation across views. SAGOnline achieves state-of-the-art performance on NVOS (92.7% mIoU) and Spin-NeRF (95.2% mIoU) benchmarks, outperforming Feature3DGS, OmniSeg3D-gs, and SA3D by 15--1500 times in inference speed (27 ms/frame). Qualitative results demonstrate robust multi-object segmentation and tracking in complex scenes. Our contributions include: (i) a lightweight and zero-shot framework for 3D segmentation in Gaussian scenes, (ii) explicit labeling of Gaussian primitives enabling simultaneous segmentation and tracking, and (iii) the effective adaptation of 2D video foundation models to the 3D domain. This work allows real-time rendering and 3D scene understanding, paving the way for practical AR/VR and robotic applications.
PointGauss: Point Cloud-Guided Multi-Object Segmentation for Gaussian Splatting
Aug 01, 2025



We introduce PointGauss, a novel point cloud-guided framework for real-time multi-object segmentation in Gaussian Splatting representations. Unlike existing methods that suffer from prolonged initialization and limited multi-view consistency, our approach achieves efficient 3D segmentation by directly parsing Gaussian primitives through a point cloud segmentation-driven pipeline. The key innovation lies in two aspects: (1) a point cloud-based Gaussian primitive decoder that generates 3D instance masks within 1 minute, and (2) a GPU-accelerated 2D mask rendering system that ensures multi-view consistency. Extensive experiments demonstrate significant improvements over previous state-of-the-art methods, achieving performance gains of 1.89 to 31.78% in multi-view mIoU, while maintaining superior computational efficiency. To address the limitations of current benchmarks (single-object focus, inconsistent 3D evaluation, small scale, and partial coverage), we present DesktopObjects-360, a novel comprehensive dataset for 3D segmentation in radiance fields, featuring: (1) complex multi-object scenes, (2) globally consistent 2D annotations, (3) large-scale training data (over 27 thousand 2D masks), (4) full 360{\deg} coverage, and (5) 3D evaluation masks.
Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration
Apr 01, 2025The reconstruction of immersive and realistic 3D scenes holds significant practical importance in various fields of computer vision and computer graphics. Typically, immersive and realistic scenes should be free from obstructions by dynamic objects, maintain global texture consistency, and allow for unrestricted exploration. The current mainstream methods for image-driven scene construction involves iteratively refining the initial image using a moving virtual camera to generate the scene. However, previous methods struggle with visual discontinuities due to global texture inconsistencies under varying camera poses, and they frequently exhibit scene voids caused by foreground-background occlusions. To this end, we propose a novel layered 3D scene reconstruction framework from panoramic image, named Scene4U. Specifically, Scene4U integrates an open-vocabulary segmentation model with a large language model to decompose a real panorama into multiple layers. Then, we employs a layered repair module based on diffusion model to restore occluded regions using visual cues and depth information, generating a hierarchical representation of the scene. The multi-layer panorama is then initialized as a 3D Gaussian Splatting representation, followed by layered optimization, which ultimately produces an immersive 3D scene with semantic and structural consistency that supports free exploration. Scene4U outperforms state-of-the-art method, improving by 24.24% in LPIPS and 24.40% in BRISQUE, while also achieving the fastest training speed. Additionally, to demonstrate the robustness of Scene4U and allow users to experience immersive scenes from various landmarks, we build WorldVista3D dataset for 3D scene reconstruction, which contains panoramic images of globally renowned sites. The implementation code and dataset will be released at https://github.com/LongHZ140516/Scene4U .
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
Oct 13, 2024



With the rapid development of AI-generated content, the future internet may be inundated with synthetic data, making the discrimination of authentic and credible multimodal data increasingly challenging. Synthetic data detection has thus garnered widespread attention, and the performance of large multimodal models (LMMs) in this task has attracted significant interest. LMMs can provide natural language explanations for their authenticity judgments, enhancing the explainability of synthetic content detection. Simultaneously, the task of distinguishing between real and synthetic data effectively tests the perception, knowledge, and reasoning capabilities of LMMs. In response, we introduce LOKI, a novel benchmark designed to evaluate the ability of LMMs to detect synthetic data across multiple modalities. LOKI encompasses video, image, 3D, text, and audio modalities, comprising 18K carefully curated questions across 26 subcategories with clear difficulty levels. The benchmark includes coarse-grained judgment and multiple-choice questions, as well as fine-grained anomaly selection and explanation tasks, allowing for a comprehensive analysis of LMMs. We evaluated 22 open-source LMMs and 6 closed-source models on LOKI, highlighting their potential as synthetic data detectors and also revealing some limitations in the development of LMM capabilities. More information about LOKI can be found at https://opendatalab.github.io/LOKI/
Direction-aware Feature-level Frequency Decomposition for Single Image Deraining
Jun 15, 2021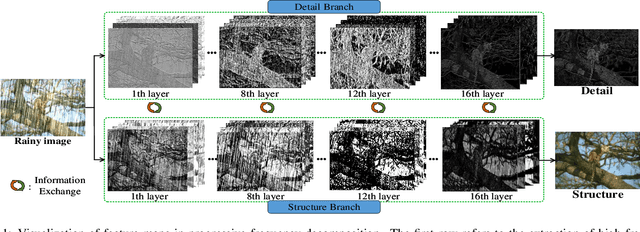

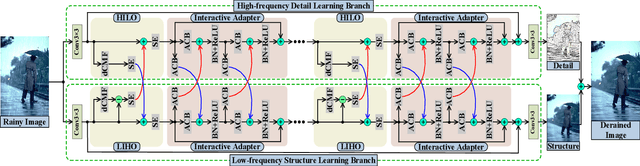
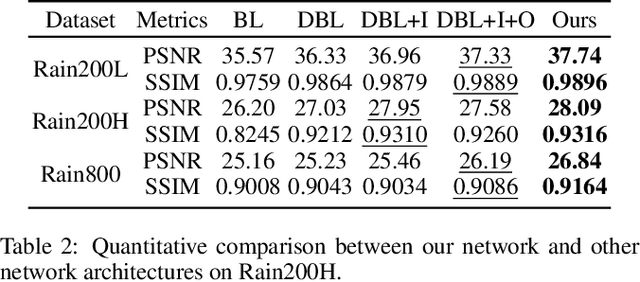
We present a novel direction-aware feature-level frequency decomposition network for single image deraining. Compared with existing solutions, the proposed network has three compelling characteristics. First, unlike previous algorithms, we propose to perform frequency decomposition at feature-level instead of image-level, allowing both low-frequency maps containing structures and high-frequency maps containing details to be continuously refined during the training procedure. Second, we further establish communication channels between low-frequency maps and high-frequency maps to interactively capture structures from high-frequency maps and add them back to low-frequency maps and, simultaneously, extract details from low-frequency maps and send them back to high-frequency maps, thereby removing rain streaks while preserving more delicate features in the input image. Third, different from existing algorithms using convolutional filters consistent in all directions, we propose a direction-aware filter to capture the direction of rain streaks in order to more effectively and thoroughly purge the input images of rain streaks. We extensively evaluate the proposed approach in three representative datasets and experimental results corroborate our approach consistently outperforms state-of-the-art deraining algorithms.
PointNLM: Point Nonlocal-Means for vegetation segmentation based on middle echo point clouds
Jun 20, 2019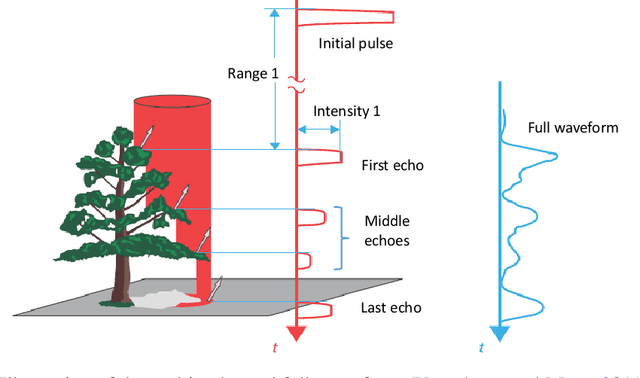
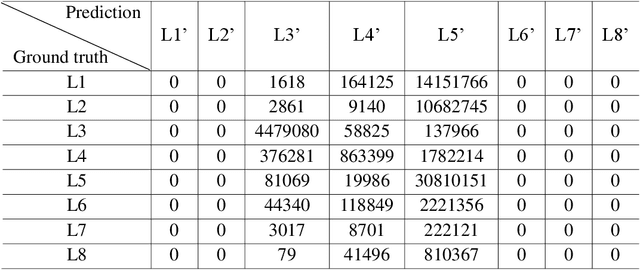
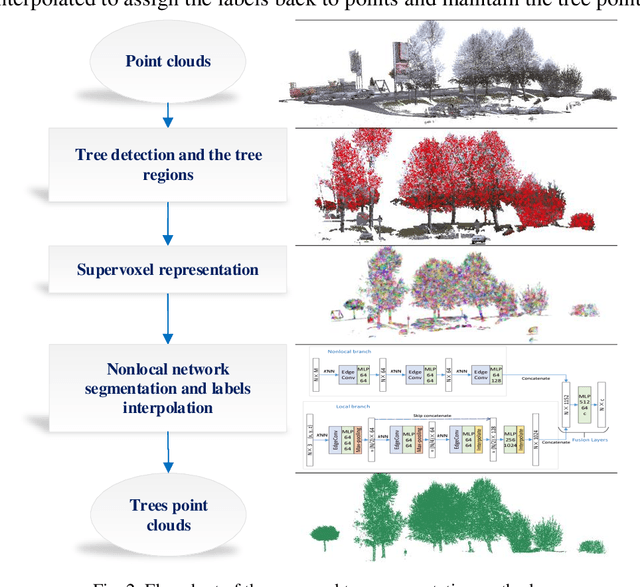

Middle-echo, which covers one or a few corresponding points, is a specific type of 3D point cloud acquired by a multi-echo laser scanner. In this paper, we propose a novel approach for automatic segmentation of trees that leverages middle-echo information from LiDAR point clouds. First, using a convolution classification method, the proposed type of point clouds reflected by the middle echoes are identified from all point clouds. The middle-echo point clouds are distinguished from the first and last echoes. Hence, the crown positions of the trees are quickly detected from the huge number of point clouds. Second, to accurately extract trees from all point clouds, we propose a 3D deep learning network, PointNLM, to semantically segment tree crowns. PointNLM captures the long-range relationship between the point clouds via a non-local branch and extracts high-level features via max-pooling applied to unordered points. The whole framework is evaluated using the Semantic 3D reduced-test set. The IoU of tree point cloud segmentation reached 0.864. In addition, the semantic segmentation network was tested using the Paris-Lille-3D dataset. The average IoU outperformed several other popular methods. The experimental results indicate that the proposed algorithm provides an excellent solution for vegetation segmentation from LiDAR point clouds.