 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebqa
Papers and Code
Failure is Feedback: History-Aware Backtracking for Agentic Traversal in Multimodal Graphs
Feb 03, 2026Open-domain multimodal document retrieval aims to retrieve specific components (paragraphs, tables, or images) from large and interconnected document corpora. Existing graph-based retrieval approaches typically rely on a uniform similarity metric that overlooks hop-specific semantics, and their rigid pre-defined plans hinder dynamic error correction. These limitations suggest that a retriever should adapt its reasoning to the evolving context and recover intelligently from dead ends. To address these needs, we propose Failure is Feedback (FiF), which casts subgraph retrieval as a sequential decision process and introduces two key innovations. (i) We introduce a history-aware backtracking mechanism; unlike standard backtracking that simply reverts the state, our approach piggybacks on the context of failed traversals, leveraging insights from previous failures. (ii) We implement an economically-rational agentic workflow. Unlike conventional agents with static strategies, our orchestrator employs a cost-aware traversal method to dynamically manage the trade-off between retrieval accuracy and inference costs, escalating to intensive LLM-based reasoning only when the prior failure justifies the additional computational investment. Extensive experiments show that FiF achieves state-of-the-art retrieval on the benchmarks of MultimodalQA, MMCoQA and WebQA.
MMRAG-RFT: Two-stage Reinforcement Fine-tuning for Explainable Multi-modal Retrieval-augmented Generation
Dec 19, 2025Multi-modal Retrieval-Augmented Generation (MMRAG) enables highly credible generation by integrating external multi-modal knowledge, thus demonstrating impressive performance in complex multi-modal scenarios. However, existing MMRAG methods fail to clarify the reasoning logic behind retrieval and response generation, which limits the explainability of the results. To address this gap, we propose to introduce reinforcement learning into multi-modal retrieval-augmented generation, enhancing the reasoning capabilities of multi-modal large language models through a two-stage reinforcement fine-tuning framework to achieve explainable multi-modal retrieval-augmented generation. Specifically, in the first stage, rule-based reinforcement fine-tuning is employed to perform coarse-grained point-wise ranking of multi-modal documents, effectively filtering out those that are significantly irrelevant. In the second stage, reasoning-based reinforcement fine-tuning is utilized to jointly optimize fine-grained list-wise ranking and answer generation, guiding multi-modal large language models to output explainable reasoning logic in the MMRAG process. Our method achieves state-of-the-art results on WebQA and MultimodalQA, two benchmark datasets for multi-modal retrieval-augmented generation, and its effectiveness is validated through comprehensive ablation experiments.
VLMT: Vision-Language Multimodal Transformer for Multimodal Multi-hop Question Answering
Apr 11, 2025


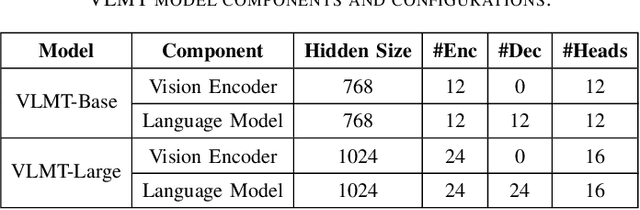
The increasing availability of multimodal data across text, tables, and images presents new challenges for developing models capable of complex cross-modal reasoning. Existing methods for Multimodal Multi-hop Question Answering (MMQA) often suffer from limited reasoning capabilities, reliance on modality conversion, and inadequate alignment between visual and textual representations. To address these limitations, this paper introduces Vision-Language Multimodal Transformer (VLMT), a unified architecture that integrates a transformer-based vision encoder with a sequence-to-sequence language model. VLMT employs a direct token-level injection mechanism to fuse visual and textual inputs within a shared embedding space, eliminating the need for intermediate projection layers. To enhance cross-modal alignment and reasoning, a three-stage pretraining strategy is proposed to progressively align vision-language representations and improve the model's capacity for multimodal understanding. Based on the pretrained backbone, two task-specific modules are instantiated to form a two-stage MMQA framework: a multimodal reranker that predicts document relevance scores and utilizes a relative threshold with top-k strategy for context retrieval, and a multimodal question answering model that generates contextually grounded answers based on the retrieved evidence. Comprehensive experiments on two benchmark datasets demonstrate the effectiveness of the proposed approach. On MultimodalQA validation set, VLMT-Large achieves 76.5% Exact Match and 80.1% F1, outperforming the previous state-of-the-art by +9.1% in Exact Match and +8.8% in F1. On WebQA, it attains a QA score of 47.6, surpassing prior models such as PERQA by +3.2. These results highlight VLMT's strong capabilities in multimodal reasoning and its potential to advance real-world information retrieval and question answering systems.
Quantifying Memorization and Retriever Performance in Retrieval-Augmented Vision-Language Models
Feb 19, 2025Large Language Models (LLMs) demonstrate remarkable capabilities in question answering (QA), but metrics for assessing their reliance on memorization versus retrieval remain underdeveloped. Moreover, while finetuned models are state-of-the-art on closed-domain tasks, general-purpose models like GPT-4o exhibit strong zero-shot performance. This raises questions about the trade-offs between memorization, generalization, and retrieval. In this work, we analyze the extent to which multimodal retrieval-augmented VLMs memorize training data compared to baseline VLMs. Using the WebQA benchmark, we contrast finetuned models with baseline VLMs on multihop retrieval and question answering, examining the impact of finetuning on data memorization. To quantify memorization in end-to-end retrieval and QA systems, we propose several proxy metrics by investigating instances where QA succeeds despite retrieval failing. Our results reveal the extent to which finetuned models rely on memorization. In contrast, retrieval-augmented VLMs have lower memorization scores, at the cost of accuracy (72% vs 52% on WebQA test set). As such, our measures pose a challenge for future work to reconcile memorization and generalization in both Open-Domain QA and joint Retrieval-QA tasks.
ASRank: Zero-Shot Re-Ranking with Answer Scent for Document Retrieval
Jan 25, 2025



Retrieval-Augmented Generation (RAG) models have drawn considerable attention in modern open-domain question answering. The effectiveness of RAG depends on the quality of the top retrieved documents. However, conventional retrieval methods sometimes fail to rank the most relevant documents at the top. In this paper, we introduce ASRank, a new re-ranking method based on scoring retrieved documents using zero-shot answer scent which relies on a pre-trained large language model to compute the likelihood of the document-derived answers aligning with the answer scent. Our approach demonstrates marked improvements across several datasets, including NQ, TriviaQA, WebQA, ArchivalQA, HotpotQA, and Entity Questions. Notably, ASRank increases Top-1 retrieval accuracy on NQ from $19.2\%$ to $46.5\%$ for MSS and $22.1\%$ to $47.3\%$ for BM25. It also shows strong retrieval performance on several datasets compared to state-of-the-art methods (47.3 Top-1 by ASRank vs 35.4 by UPR by BM25).
Multimodal Multihop Source Retrieval for Web Question Answering
Jan 07, 2025



This work deals with the challenge of learning and reasoning over multi-modal multi-hop question answering (QA). We propose a graph reasoning network based on the semantic structure of the sentences to learn multi-source reasoning paths and find the supporting facts across both image and text modalities for answering the question. In this paper, we investigate the importance of graph structure for multi-modal multi-hop question answering. Our analysis is centered on WebQA. We construct a strong baseline model, that finds relevant sources using a pairwise classification task. We establish that, with the proper use of feature representations from pre-trained models, graph structure helps in improving multi-modal multi-hop question answering. We point out that both graph structure and adjacency matrix are task-related prior knowledge, and graph structure can be leveraged to improve the retrieval performance for the task. Experiments and visualized analysis demonstrate that message propagation over graph networks or the entire graph structure can replace massive multimodal transformers with token-wise cross-attention. We demonstrated the applicability of our method and show a performance gain of \textbf{4.6$\%$} retrieval F1score over the transformer baselines, despite being a very light model. We further demonstrated the applicability of our model to a large scale retrieval setting.
An Entailment Tree Generation Approach for Multimodal Multi-Hop Question Answering with Mixture-of-Experts and Iterative Feedback Mechanism
Dec 10, 2024With the rise of large-scale language models (LLMs), it is currently popular and effective to convert multimodal information into text descriptions for multimodal multi-hop question answering. However, we argue that the current methods of multi-modal multi-hop question answering still mainly face two challenges: 1) The retrieved evidence containing a large amount of redundant information, inevitably leads to a significant drop in performance due to irrelevant information misleading the prediction. 2) The reasoning process without interpretable reasoning steps makes the model difficult to discover the logical errors for handling complex questions. To solve these problems, we propose a unified LLMs-based approach but without heavily relying on them due to the LLM's potential errors, and innovatively treat multimodal multi-hop question answering as a joint entailment tree generation and question answering problem. Specifically, we design a multi-task learning framework with a focus on facilitating common knowledge sharing across interpretability and prediction tasks while preventing task-specific errors from interfering with each other via mixture of experts. Afterward, we design an iterative feedback mechanism to further enhance both tasks by feeding back the results of the joint training to the LLM for regenerating entailment trees, aiming to iteratively refine the potential answer. Notably, our method has won the first place in the official leaderboard of WebQA (since April 10, 2024), and achieves competitive results on MultimodalQA.
* Erratum: We identified an error in the calculation of the F1 score in table 4 reported in a previous version of this work. The performance of the new result is better than the previous one. The corrected values are included in this updated version of the paper. These changes do not alter the primary conclusions of our research
Unlock Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
Oct 21, 2023



This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL) to learn an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of a well-trained dense retriever, T5-ANCE, by incorporating the image features encoded by the visual module as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and exact the related texts and image documents from anchor linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. Our further analyses show that the visual module plugin method is tailored to enable the image understanding ability for an existing dense retrieval model. Besides, we also show that the language model has the ability to extract image semantics from image encoders and adapt the image features in the input space of language models. All codes are available at https://github.com/OpenMatch/MARVEL.
Progressive Evidence Refinement for Open-domain Multimodal Retrieval Question Answering
Oct 15, 2023



Pre-trained multimodal models have achieved significant success in retrieval-based question answering. However, current multimodal retrieval question-answering models face two main challenges. Firstly, utilizing compressed evidence features as input to the model results in the loss of fine-grained information within the evidence. Secondly, a gap exists between the feature extraction of evidence and the question, which hinders the model from effectively extracting critical features from the evidence based on the given question. We propose a two-stage framework for evidence retrieval and question-answering to alleviate these issues. First and foremost, we propose a progressive evidence refinement strategy for selecting crucial evidence. This strategy employs an iterative evidence retrieval approach to uncover the logical sequence among the evidence pieces. It incorporates two rounds of filtering to optimize the solution space, thus further ensuring temporal efficiency. Subsequently, we introduce a semi-supervised contrastive learning training strategy based on negative samples to expand the scope of the question domain, allowing for a more thorough exploration of latent knowledge within known samples. Finally, in order to mitigate the loss of fine-grained information, we devise a multi-turn retrieval and question-answering strategy to handle multimodal inputs. This strategy involves incorporating multimodal evidence directly into the model as part of the historical dialogue and question. Meanwhile, we leverage a cross-modal attention mechanism to capture the underlying connections between the evidence and the question, and the answer is generated through a decoding generation approach. We validate the model's effectiveness through extensive experiments, achieving outstanding performance on WebQA and MultimodelQA benchmark tests.
Unified Language Representation for Question Answering over Text, Tables, and Images
Jun 29, 2023



When trying to answer complex questions, people often rely on multiple sources of information, such as visual, textual, and tabular data. Previous approaches to this problem have focused on designing input features or model structure in the multi-modal space, which is inflexible for cross-modal reasoning or data-efficient training. In this paper, we call for an alternative paradigm, which transforms the images and tables into unified language representations, so that we can simplify the task into a simpler textual QA problem that can be solved using three steps: retrieval, ranking, and generation, all within a language space. This idea takes advantage of the power of pre-trained language models and is implemented in a framework called Solar. Our experimental results show that Solar outperforms all existing methods by 10.6-32.3 pts on two datasets, MultimodalQA and MMCoQA, across ten different metrics. Additionally, Solar achieves the best performance on the WebQA leaderboard