 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMT: Vision-Language Multimodal Transformer for Multimodal Multi-hop Question Answering
Apr 11, 2025


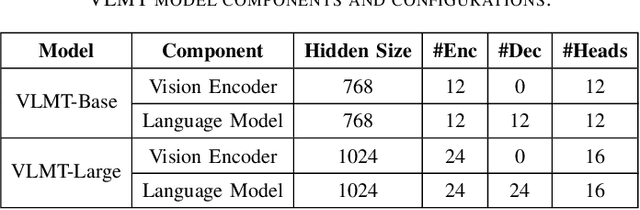
The increasing availability of multimodal data across text, tables, and images presents new challenges for developing models capable of complex cross-modal reasoning. Existing methods for Multimodal Multi-hop Question Answering (MMQA) often suffer from limited reasoning capabilities, reliance on modality conversion, and inadequate alignment between visual and textual representations. To address these limitations, this paper introduces Vision-Language Multimodal Transformer (VLMT), a unified architecture that integrates a transformer-based vision encoder with a sequence-to-sequence language model. VLMT employs a direct token-level injection mechanism to fuse visual and textual inputs within a shared embedding space, eliminating the need for intermediate projection layers. To enhance cross-modal alignment and reasoning, a three-stage pretraining strategy is proposed to progressively align vision-language representations and improve the model's capacity for multimodal understanding. Based on the pretrained backbone, two task-specific modules are instantiated to form a two-stage MMQA framework: a multimodal reranker that predicts document relevance scores and utilizes a relative threshold with top-k strategy for context retrieval, and a multimodal question answering model that generates contextually grounded answers based on the retrieved evidence. Comprehensive experiments on two benchmark datasets demonstrate the effectiveness of the proposed approach. On MultimodalQA validation set, VLMT-Large achieves 76.5% Exact Match and 80.1% F1, outperforming the previous state-of-the-art by +9.1% in Exact Match and +8.8% in F1. On WebQA, it attains a QA score of 47.6, surpassing prior models such as PERQA by +3.2. These results highlight VLMT's strong capabilities in multimodal reasoning and its potential to advance real-world information retrieval and question answering systems.
PAtt-Lite: Lightweight Patch and Attention MobileNet for Challenging Facial Expression Recognition
Jun 16, 2023



Facial Expression Recognition (FER) is a machine learning problem that deals with recognizing human facial expressions. While existing work has achieved performance improvements in recent years, FER in the wild and under challenging conditions remains a challenge. In this paper, a lightweight patch and attention network based on MobileNetV1, referred to as PAtt-Lite, is proposed to improve FER performance under challenging conditions. A truncated ImageNet-pre-trained MobileNetV1 is utilized as the backbone feature extractor of the proposed method. In place of the truncated layers is a patch extraction block that is proposed for extracting significant local facial features to enhance the representation from MobileNetV1, especially under challenging conditions. An attention classifier is also proposed to improve the learning of these patched feature maps from the extremely lightweight feature extractor. The experimental results on public benchmark databases proved the effectiveness of the proposed method. PAtt-Lite achieved state-of-the-art results on CK+, RAF-DB, FER2013, FERPlus, and the challenging conditions subsets for RAF-DB and FERPlus. The source code for the proposed method will be available at https://github.com/JLREx/PAtt-Lite.
Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle
Apr 14, 2016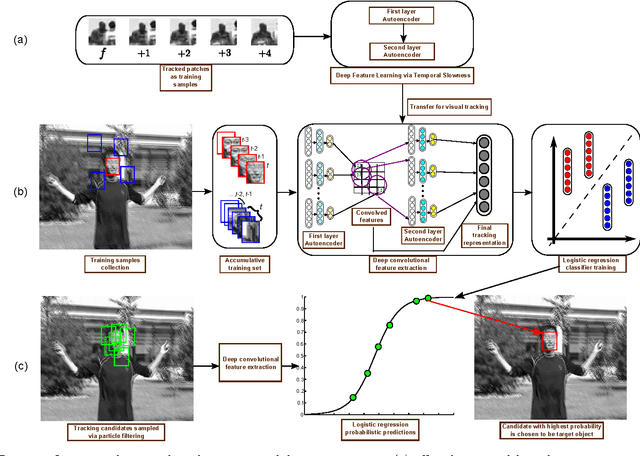
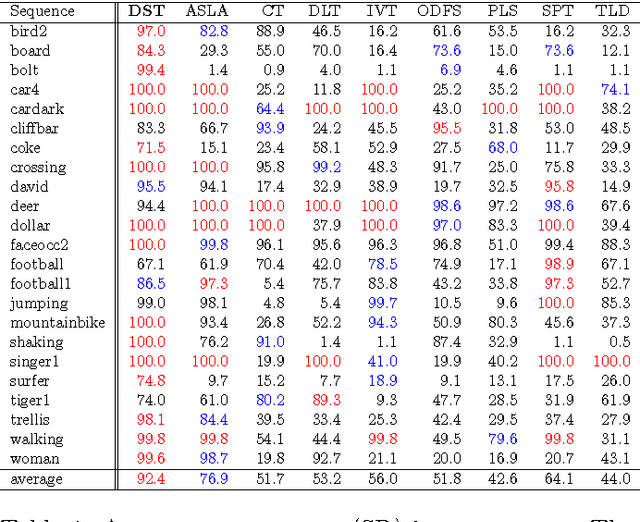
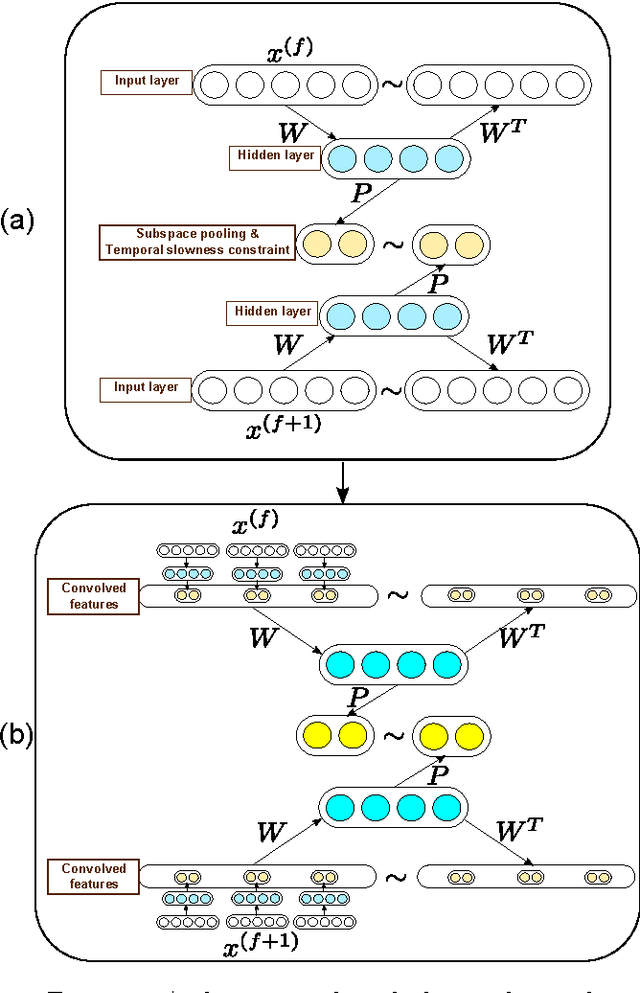
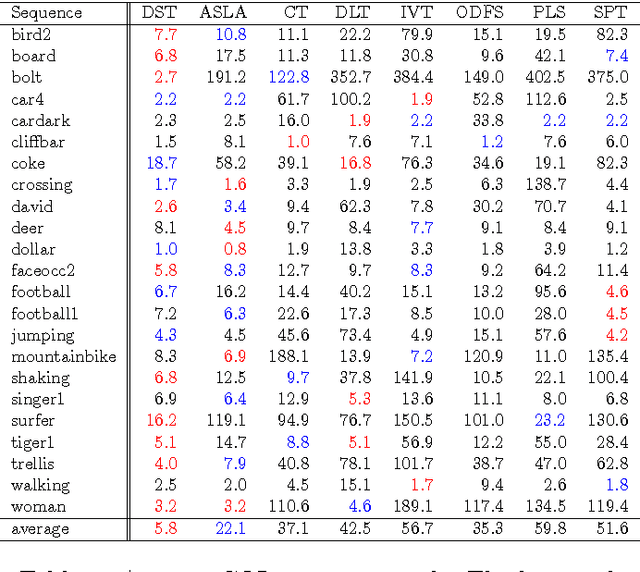
Visual representation is crucial for a visual tracking method's performances. Conventionally, visual representations adopted in visual tracking rely on hand-crafted computer vision descriptors. These descriptors were developed generically without considering tracking-specific information. In this paper, we propose to learn complex-valued invariant representations from tracked sequential image patches, via strong temporal slowness constraint and stacked convolutional autoencoders. The deep slow local representations are learned offline on unlabeled data and transferred to the observational model of our proposed tracker. The proposed observational model retains old training samples to alleviate drift, and collect negative samples which are coherent with target's motion pattern for better discriminative tracking. With the learned representation and online training samples, a logistic regression classifier is adopted to distinguish target from background, and retrained online to adapt to appearance changes. Subsequently, the observational model is integrated into a particle filter framework to peform visual tracking. Experimental results on various challenging benchmark sequences demonstrate that the proposed tracker performs favourably against several state-of-the-art trackers.