 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGap Coreference Dataset
Papers and Code
Multimodal Coreference Resolution for Chinese Social Media Dialogues: Dataset and Benchmark Approach
Apr 19, 2025Multimodal coreference resolution (MCR) aims to identify mentions referring to the same entity across different modalities, such as text and visuals, and is essential for understanding multimodal content. In the era of rapidly growing mutimodal content and social media, MCR is particularly crucial for interpreting user interactions and bridging text-visual references to improve communication and personalization. However, MCR research for real-world dialogues remains unexplored due to the lack of sufficient data resources.To address this gap, we introduce TikTalkCoref, the first Chinese multimodal coreference dataset for social media in real-world scenarios, derived from the popular Douyin short-video platform. This dataset pairs short videos with corresponding textual dialogues from user comments and includes manually annotated coreference clusters for both person mentions in the text and the coreferential person head regions in the corresponding video frames. We also present an effective benchmark approach for MCR, focusing on the celebrity domain, and conduct extensive experiments on our dataset, providing reliable benchmark results for this newly constructed dataset. We will release the TikTalkCoref dataset to facilitate future research on MCR for real-world social media dialogues.
Enhancing Coreference Resolution with Pretrained Language Models: Bridging the Gap Between Syntax and Semantics
Apr 08, 2025



Large language models have made significant advancements in various natural language processing tasks, including coreference resolution. However, traditional methods often fall short in effectively distinguishing referential relationships due to a lack of integration between syntactic and semantic information. This study introduces an innovative framework aimed at enhancing coreference resolution by utilizing pretrained language models. Our approach combines syntax parsing with semantic role labeling to accurately capture finer distinctions in referential relationships. By employing state-of-the-art pretrained models to gather contextual embeddings and applying an attention mechanism for fine-tuning, we improve the performance of coreference tasks. Experimental results across diverse datasets show that our method surpasses conventional coreference resolution systems, achieving notable accuracy in disambiguating references. This development not only improves coreference resolution outcomes but also positively impacts other natural language processing tasks that depend on precise referential understanding.
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
Oct 02, 2024



Large language models (LLMs) have shown remarkable capabilities in natural language processing; however, they still face difficulties when tasked with understanding lengthy contexts and executing effective question answering. These challenges often arise due to the complexity and ambiguity present in longer texts. To enhance the performance of LLMs in such scenarios, we introduce the Long Question Coreference Adaptation (LQCA) method. This innovative framework focuses on coreference resolution tailored to long contexts, allowing the model to identify and manage references effectively. The LQCA method encompasses four key steps: resolving coreferences within sub-documents, computing the distances between mentions, defining a representative mention for coreference, and answering questions through mention replacement. By processing information systematically, the framework provides easier-to-handle partitions for LLMs, promoting better understanding. Experimental evaluations on a range of LLMs and datasets have yielded positive results, with a notable improvements on OpenAI-o1-mini and GPT-4o models, highlighting the effectiveness of leveraging coreference resolution to bridge context gaps in question answering.
Enhancing Cross-Document Event Coreference Resolution by Discourse Structure and Semantic Information
Jun 23, 2024



Existing cross-document event coreference resolution models, which either compute mention similarity directly or enhance mention representation by extracting event arguments (such as location, time, agent, and patient), lacking the ability to utilize document-level information. As a result, they struggle to capture long-distance dependencies. This shortcoming leads to their underwhelming performance in determining coreference for the events where their argument information relies on long-distance dependencies. In light of these limitations, we propose the construction of document-level Rhetorical Structure Theory (RST) trees and cross-document Lexical Chains to model the structural and semantic information of documents. Subsequently, cross-document heterogeneous graphs are constructed and GAT is utilized to learn the representations of events. Finally, a pair scorer calculates the similarity between each pair of events and co-referred events can be recognized using standard clustering algorithm. Additionally, as the existing cross-document event coreference datasets are limited to English, we have developed a large-scale Chinese cross-document event coreference dataset to fill this gap, which comprises 53,066 event mentions and 4,476 clusters. After applying our model on the English and Chinese datasets respectively, it outperforms all baselines by large margins.
Major Entity Identification: A Generalizable Alternative to Coreference Resolution
Jun 20, 2024



The limited generalization of coreference resolution (CR) models has been a major bottleneck in the task's broad application. Prior work has identified annotation differences, especially for mention detection, as one of the main reasons for the generalization gap and proposed using additional annotated target domain data. Rather than relying on this additional annotation, we propose an alternative formulation of the CR task, Major Entity Identification (MEI), where we: (a) assume the target entities to be specified in the input, and (b) limit the task to only the frequent entities. Through extensive experiments, we demonstrate that MEI models generalize well across domains on multiple datasets with supervised models and LLM-based few-shot prompting. Additionally, the MEI task fits the classification framework, which enables the use of classification-based metrics that are more robust than the current CR metrics. Finally, MEI is also of practical use as it allows a user to search for all mentions of a particular entity or a group of entities of interest.
SEAM: A Stochastic Benchmark for Multi-Document Tasks
Jun 23, 2024



Various tasks, such as summarization, multi-hop question answering, or coreference resolution, are naturally phrased over collections of real-world documents. Such tasks present a unique set of challenges, revolving around the lack of coherent narrative structure across documents, which often leads to contradiction, omission, or repetition of information. Despite their real-world application and challenging properties, there is currently no benchmark which specifically measures the abilities of large language models (LLMs) on multi-document tasks. To bridge this gap, we present SEAM (a Stochastic Evaluation Approach for Multi-document tasks), a conglomerate benchmark over a diverse set of multi-document datasets, setting conventional evaluation criteria, input-output formats, and evaluation protocols. In particular, SEAM addresses the sensitivity of LLMs to minor prompt variations through repeated evaluations, where in each evaluation we sample uniformly at random the values of arbitrary factors (e.g., the order of documents). We evaluate different LLMs on SEAM finding that multi-document tasks pose a significant challenge for LLMs, even for state-of-the-art models with 70B parameters. In addition, we show that the stochastic approach uncovers underlying statistical trends which cannot be observed in a static benchmark. We hope that SEAM will spur progress via consistent and meaningful evaluation of multi-document tasks.
RGAT: A Deeper Look into Syntactic Dependency Information for Coreference Resolution
Sep 10, 2023



Although syntactic information is beneficial for many NLP tasks, combining it with contextual information between words to solve the coreference resolution problem needs to be further explored. In this paper, we propose an end-to-end parser that combines pre-trained BERT with a Syntactic Relation Graph Attention Network (RGAT) to take a deeper look into the role of syntactic dependency information for the coreference resolution task. In particular, the RGAT model is first proposed, then used to understand the syntactic dependency graph and learn better task-specific syntactic embeddings. An integrated architecture incorporating BERT embeddings and syntactic embeddings is constructed to generate blending representations for the downstream task. Our experiments on a public Gendered Ambiguous Pronouns (GAP) dataset show that with the supervision learning of the syntactic dependency graph and without fine-tuning the entire BERT, we increased the F1-score of the previous best model (RGCN-with-BERT) from 80.3% to 82.5%, compared to the F1-score by single BERT embeddings from 78.5% to 82.5%. Experimental results on another public dataset - OntoNotes 5.0 demonstrate that the performance of the model is also improved by incorporating syntactic dependency information learned from RGAT.
* 8 pages, 5 figures
Counter-GAP: Counterfactual Bias Evaluation through Gendered Ambiguous Pronouns
Feb 11, 2023



Bias-measuring datasets play a critical role in detecting biased behavior of language models and in evaluating progress of bias mitigation methods. In this work, we focus on evaluating gender bias through coreference resolution, where previous datasets are either hand-crafted or fail to reliably measure an explicitly defined bias. To overcome these shortcomings, we propose a novel method to collect diverse, natural, and minimally distant text pairs via counterfactual generation, and construct Counter-GAP, an annotated dataset consisting of 4008 instances grouped into 1002 quadruples. We further identify a bias cancellation problem in previous group-level metrics on Counter-GAP, and propose to use the difference between inconsistency across genders and within genders to measure bias at a quadruple level. Our results show that four pre-trained language models are significantly more inconsistent across different gender groups than within each group, and that a name-based counterfactual data augmentation method is more effective to mitigate such bias than an anonymization-based method.
The Gap on GAP: Tackling the Problem of Differing Data Distributions in Bias-Measuring Datasets
Nov 12, 2020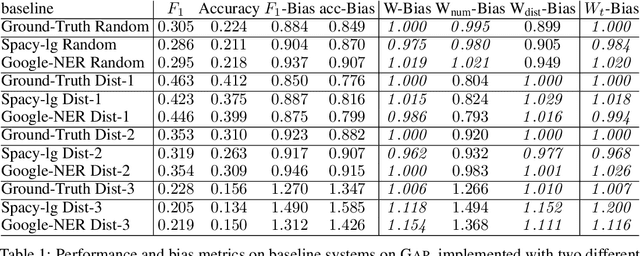
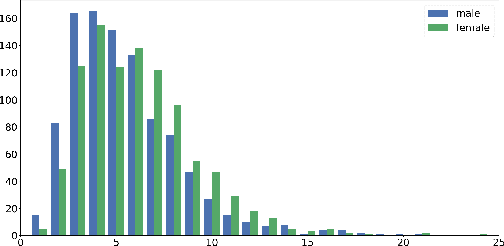
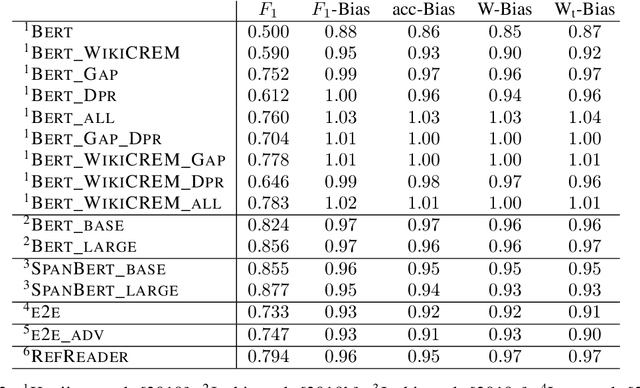
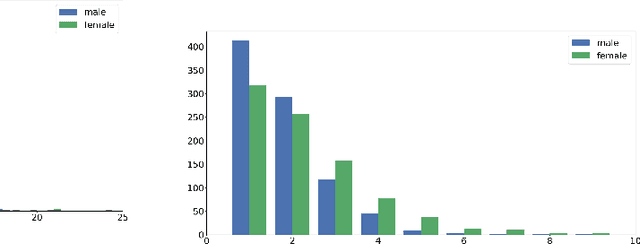
Diagnostic datasets that can detect biased models are an important prerequisite for bias reduction within natural language processing. However, undesired patterns in the collected data can make such tests incorrect. For example, if the feminine subset of a gender-bias-measuring coreference resolution dataset contains sentences with a longer average distance between the pronoun and the correct candidate, an RNN-based model may perform worse on this subset due to long-term dependencies. In this work, we introduce a theoretically grounded method for weighting test samples to cope with such patterns in the test data. We demonstrate the method on the GAP dataset for coreference resolution. We annotate GAP with spans of all personal names and show that examples in the female subset contain more personal names and a longer distance between pronouns and their referents, potentially affecting the bias score in an undesired way. Using our weighting method, we find the set of weights on the test instances that should be used for coping with these correlations, and we re-evaluate 16 recently released coreference models.
Understanding Points of Correspondence between Sentences for Abstractive Summarization
Jun 10, 2020
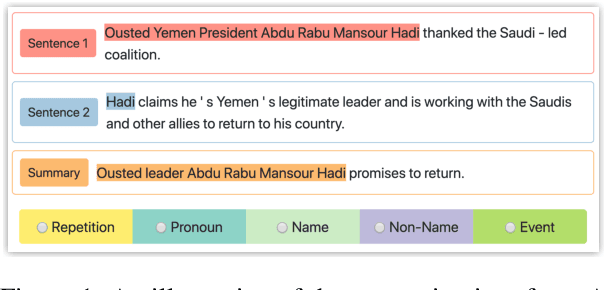
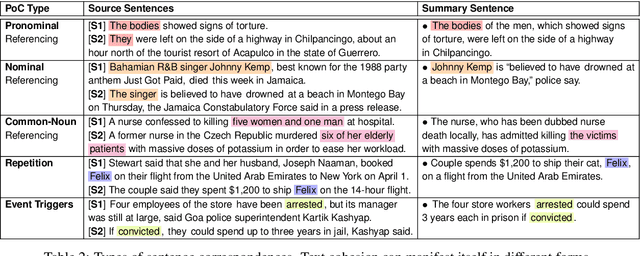

Fusing sentences containing disparate content is a remarkable human ability that helps create informative and succinct summaries. Such a simple task for humans has remained challenging for modern abstractive summarizers, substantially restricting their applicability in real-world scenarios. In this paper, we present an investigation into fusing sentences drawn from a document by introducing the notion of points of correspondence, which are cohesive devices that tie any two sentences together into a coherent text. The types of points of correspondence are delineated by text cohesion theory, covering pronominal and nominal referencing, repetition and beyond. We create a dataset containing the documents, source and fusion sentences, and human annotations of points of correspondence between sentences. Our dataset bridges the gap between coreference resolution and summarization. It is publicly shared to serve as a basis for future work to measure the success of sentence fusion systems. (https://github.com/ucfnlp/points-of-correspondence)