 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheMatiQ: From Research Question to Structured Data through Interactive Schema Discovery
Apr 10, 2026Many disciplines pose natural-language research questions over large document collections whose answers typically require structured evidence, traditionally obtained by manually designing an annotation schema and exhaustively labeling the corpus, a slow and error-prone process. We introduce ScheMatiQ, which leverages calls to a backbone LLM to take a question and a corpus to produce a schema and a grounded database, with a web interface that lets steer and revise the extraction. In collaboration with domain experts, we show that ScheMatiQ yields outputs that support real-world analysis in law and computational biology. We release ScheMatiQ as open source with a public web interface, and invite experts across disciplines to use it with their own data. All resources, including the website, source code, and demonstration video, are available at: www.ScheMatiQ-ai.com
ReliableEval: A Recipe for Stochastic LLM Evaluation via Method of Moments
May 28, 2025



LLMs are highly sensitive to prompt phrasing, yet standard benchmarks typically report performance using a single prompt, raising concerns about the reliability of such evaluations. In this work, we argue for a stochastic method of moments evaluation over the space of meaning-preserving prompt perturbations. We introduce a formal definition of reliable evaluation that accounts for prompt sensitivity, and suggest ReliableEval - a method for estimating the number of prompt resamplings needed to obtain meaningful results. Using our framework, we stochastically evaluate five frontier LLMs and find that even top-performing models like GPT-4o and Claude-3.7-Sonnet exhibit substantial prompt sensitivity. Our approach is model-, task-, and metric-agnostic, offering a recipe for meaningful and robust LLM evaluation.
More Documents, Same Length: Isolating the Challenge of Multiple Documents in RAG
Mar 06, 2025



Retrieval-augmented generation (RAG) provides LLMs with relevant documents. Although previous studies noted that retrieving many documents can degrade performance, they did not isolate how the quantity of documents affects performance while controlling for context length. We evaluate various language models on custom datasets derived from a multi-hop QA task. We keep the context length and position of relevant information constant while varying the number of documents, and find that increasing the document count in RAG settings poses significant challenges for LLMs. Additionally, our results indicate that processing multiple documents is a separate challenge from handling long contexts. We also make the datasets and code available: https://github.com/shaharl6000/MoreDocsSameLen .
SEAM: A Stochastic Benchmark for Multi-Document Tasks
Jun 23, 2024



Various tasks, such as summarization, multi-hop question answering, or coreference resolution, are naturally phrased over collections of real-world documents. Such tasks present a unique set of challenges, revolving around the lack of coherent narrative structure across documents, which often leads to contradiction, omission, or repetition of information. Despite their real-world application and challenging properties, there is currently no benchmark which specifically measures the abilities of large language models (LLMs) on multi-document tasks. To bridge this gap, we present SEAM (a Stochastic Evaluation Approach for Multi-document tasks), a conglomerate benchmark over a diverse set of multi-document datasets, setting conventional evaluation criteria, input-output formats, and evaluation protocols. In particular, SEAM addresses the sensitivity of LLMs to minor prompt variations through repeated evaluations, where in each evaluation we sample uniformly at random the values of arbitrary factors (e.g., the order of documents). We evaluate different LLMs on SEAM finding that multi-document tasks pose a significant challenge for LLMs, even for state-of-the-art models with 70B parameters. In addition, we show that the stochastic approach uncovers underlying statistical trends which cannot be observed in a static benchmark. We hope that SEAM will spur progress via consistent and meaningful evaluation of multi-document tasks.
Collecting a Large-Scale Gender Bias Dataset for Coreference Resolution and Machine Translation
Sep 10, 2021

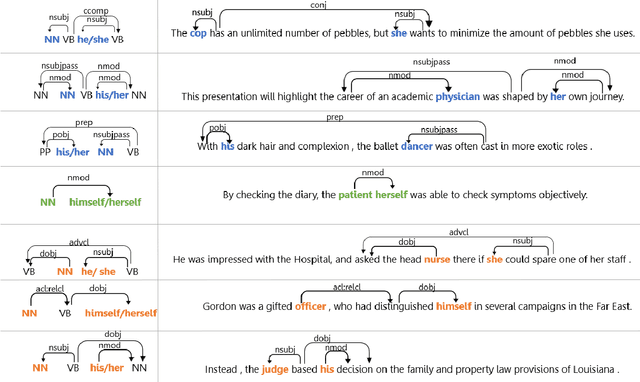
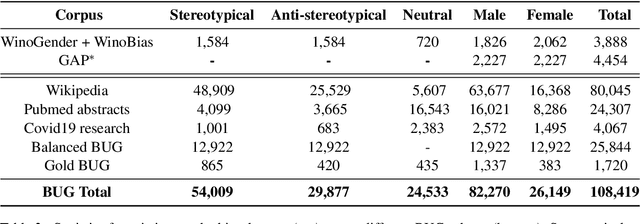
Recent works have found evidence of gender bias in models of machine translation and coreference resolution using mostly synthetic diagnostic datasets. While these quantify bias in a controlled experiment, they often do so on a small scale and consist mostly of artificial, out-of-distribution sentences. In this work, we find grammatical patterns indicating stereotypical and non-stereotypical gender-role assignments (e.g., female nurses versus male dancers) in corpora from three domains, resulting in a first large-scale gender bias dataset of 108K diverse real-world English sentences. We manually verify the quality of our corpus and use it to evaluate gender bias in various coreference resolution and machine translation models. We find that all tested models tend to over-rely on gender stereotypes when presented with natural inputs, which may be especially harmful when deployed in commercial systems. Finally, we show that our dataset lends itself to finetuning a coreference resolution model, finding it mitigates bias on a held out set. Our dataset and models are publicly available at www.github.com/SLAB-NLP/BUG. We hope they will spur future research into gender bias evaluation mitigation techniques in realistic settings.